
The streak seems to cap out at 181 days. I haven't done the math to figure out why, maybe that's when I last recreated the Ditto database?
A rare few power users are tied at the cap.
nostr:nprofile1qydhwumn8ghj7emvv4shxmmwv96x7u3wv3jhvtmjv4kxz7gqyqewrqnkx4zsaweutf739s0cu7et29zrntqs5elw70vlm8zudr3y2sndk4n nostr:nprofile1qydhwumn8ghj7emvv4shxmmwv96x7u3wv3jhvtmjv4kxz7gqyqlhwrt96wnkf2w9edgr4cfruchvwkv26q6asdhz4qg08pm6w3djgzwr0kg


#Ditto now displays daily streaks! To have a streak, no more than 24 hours can pass since your last post.

On the Fediverse you can't simply learn something and then be like "let me move to a different server". I mean you kind of can, but only with permission from the admin, who is already your adversary at this point.
>users don't even know what's happening
Like I said, the only barrier is ignorance. I'm not saying it's good, but if people have to, they can learn.
Strong disagree on that one. The only barrier there is human ignorance, since people can just switch to a different app and lose nothing. They don't lose their posts or followers, and can pick up right where they left off.
The barrier on the Fediverse is technological. After you join a server you can't change your mind.
People can use their keys to go elsewhere on the network.

Looks like they're trying to be the Cloudflare of Nostr.
You caught me. But if a "Translate" button appeared on that, it would just be funny, not annoying.
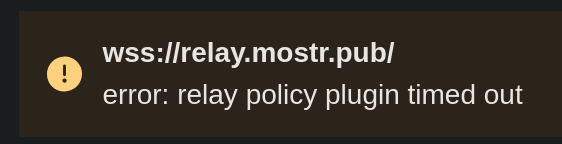
I fixed a problem with relay.mostr.pub which was causing new events to not be served on its relay.
My bad... I had a bug in my policy script. It's fixed now. Thank you for reporting it!
Yep, this one right here: https://github.com/fabiospampinato/lande
I used fasttext years ago on the Fediverse, and people complained about it a lot. So this time I'm using an obscure library I found digging through GitHub issues: https://github.com/fabiospampinato/lande
This one is specifically trained on small text, making it ideal for shitposts, but it still doesn't even take the character set into account.
fasttext is one of the ones that failed for me. Too many wrongly detected languages. It's trained on Wikipedia data, not shitposts.
Language detection is surprisingly difficult. The neural networks get basic things wrong. They will say that Korean text is actually Chinese, even though you can obviously see with your eyes that it's not.
After multiple libraries failed this basic test, I did something brave and implemented a naive regex solution in #Ditto. It does a first pass on the text before moving it on to the neural network.
안녕하세요
For example, if ALL the characters are in Korean script, it must be Korean. Even if it's a nonsensical sequence of Korean characters, it cannot be any language other than Korean due to the fact Korean makes exclusive use of this character set.
There are only a few languages where this is possible: Korean, Greek, and Hebrew.
Again, this is only possible if ALL characters in the text match a target language, so simply using "π" in a text does not make it Greek. So, currently this check is very narrow.
Notes about other languages:
Chinese: it's not possible to do a regex-only solution for Chinese, since Han script is also part of Japanese.
Japanese: we *can* definitively detect Japanese, as long as the text contains at least one Hirigana or Katakana character in addition to 0 or more Han characters. So at least *some* Japanese text can be unambiguously detected just by a regex.
Russian: Cyrillic text is used by a handful of languages besides Russian. BUT, if the text is entirely Cyrillic, that at least narrows down the *possible* languages it could be.
Next steps:
To optimize this, the regexes will narrow down possible languages of a text before passing it to the neural network.
For example, if a text is entirely Han, we would restrict the model to deciding only between Chinese and Japanese. If it's Cyrillic, we'd do the same thing, but with the 6 or so Cyrillic languages.
We could also try to match, say, 90% of the text instead of 100%, to any specific script, to catch outliers like occasional English words used in Japanese, etc. We are already stripping things like punctuation, emojis, and URLs before passing text to the model.
Finally, this is all so we can use a lightweight, embedded solution for language detection, instead of calling out to some proprietary API, or even a giant self-hosted solution. In that case, I believe a layered solution will always be needed. We have to do these naive checks to put "guardrails" on the model, so its guesses can't stray outside of common sense. Switching the model can improve it, but these naive checks will still be true.

Your NIP-05 is too slow or we're too slow to verify it
I accidentally documented it wrong, it's actually "protocol:atproto"
This will show some results from when I was mirroring posts from eclipse.pub here, but I haven't figured out the best way to show everything that doesn't involve spending thousands of dollars on SSDs.
#Ditto search now supports negative search tokens. That means you can use -protocol:activitypub to remove everything from the bridge, or even -language:de to remove the Germans.

