
2020-2024年代码生成模型发展全景图:开源与闭源项目的竞赛
2020年
- 10月:
- GPT-C: 最早发布的代码生成模型之一,基于GPT架构。
2021年
- 2月:
- PyMT5: 一个基于MT5架构的代码生成工具。
- 5月:
- CodeGPT: 基于GPT架构的代码生成模型,旨在帮助开发者编写代码。
- 7月:
- GPT-J: 开源的GPT系列模型,适用于多种任务,包括代码生成。
- 9月:
- Codex: OpenAI发布的一款强大的代码生成器,可以理解和编写代码。
- 11月:
- CodeT5: 基于T5模型的代码生成工具,提供更智能的代码补全。
2022年
- 1月:
- JuPyT5: 专为Jupyter环境优化的T5模型。
- 3月:
- AlphaCode: 新型代码生成器,提升了代码质量和生成速度。
- 4月:
- CodeGen: Salesforce推出的一款功能强大的代码生成工具。
- 7月:
- CodeRL, 和其他多个新工具发布。
- 9月:
- CodeGeeX, 和其他多个新工具发布。
2023年
- 1月:
- SantaCoder, 和其他多个新工具发布。
- 自2023年初至今,各大公司如腾讯、华为、Meta等陆续发布了各自的新型代码生成工具:
- 如腾讯的RLTF, Meta的Llama系列以及华为的PanGu-Coder2等。
更近期
每一年都有大量新工具和更新版本发布,如:
- 在2022年11月,OpenAI发布了Codex,这是一款功能强大的代码生成器,在开发者社区引起了广泛关注和应用。 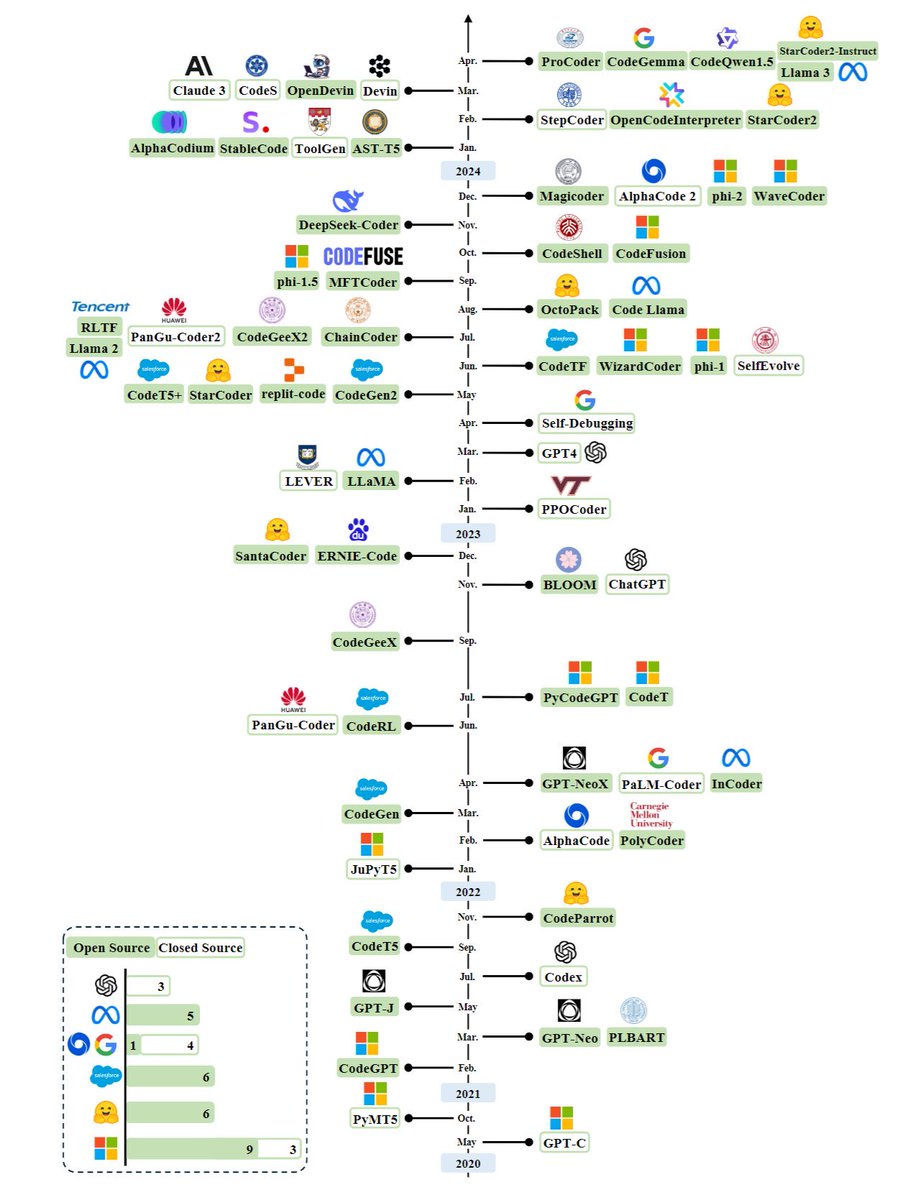
在AI搜索引擎迅速崛起的背景下,谷歌搜索排名系统仍然是理解“搜索”本质的重要资源。
谷歌的搜索排名不仅依赖于优质内容和SEO措施,还受到用户搜索行为、新信号以及动态环境的影响。以下是谷歌搜索引擎排名系统的详细工作原理:
索引过程
1. 发现与爬取:Googlebot首先发现并爬取新网页。
2. 内容标识:Alexandria系统为每个内容分配一个唯一的DocID。
3. 添加到索引:内容经过分析后被添加到谷歌的搜索索引中。
搜索过程
1. 分析搜索词:QBST系统负责解析用户输入的搜索词。
2. 检索相关内容:Ascorer从倒排索引中检索出前1000个相关DocID。
3. 结果排序:Superroot系统将这1000个结果重新排序为前10个最相关的结果。
重要的排名影响因素
1. Twiddlers:这是一系列专门的过滤器,用于微调和调整页面排名。
2. NavBoost:利用用户点击和行为数据来对排名进行动态调整。
3. 质量评估与机器学习:通过质量评估员和RankLab对结果进行人工评估,以训练机器学习算法。
最终结果展示
1. 组装页面:Google Web Server (GWS)负责组装最终展示给用户的搜索结果页面。
2. 优化布局:Tangram和Glue系统用于优化页面布局以提升用户体验。
3. 实时调整:CookBook系统根据新鲜度和即时用户行为做出最后时刻的排名调整。
SEO建议
1. 多样化流量来源,不要依赖单一渠道。
2. 品牌与域名知名度,提升品牌影响力。
3. 理解用户意图,确保内容满足用户需求。
4. 优化标题与描述,提高点击率和吸引力。
5. 改善页面结构与用户体验,提升网站易用性。
6. 更新扩展现有内容,保持信息的新鲜度而不是单纯创建新内容。
7. 高质量反向链接建设,提高网站权威性。
8. 创作独特且全面的内容,确保信息丰富且结构良好。
通过深入理解这些机制和建议,可以更有效地优化网站,使其在谷歌搜索结果中获得更高排名。 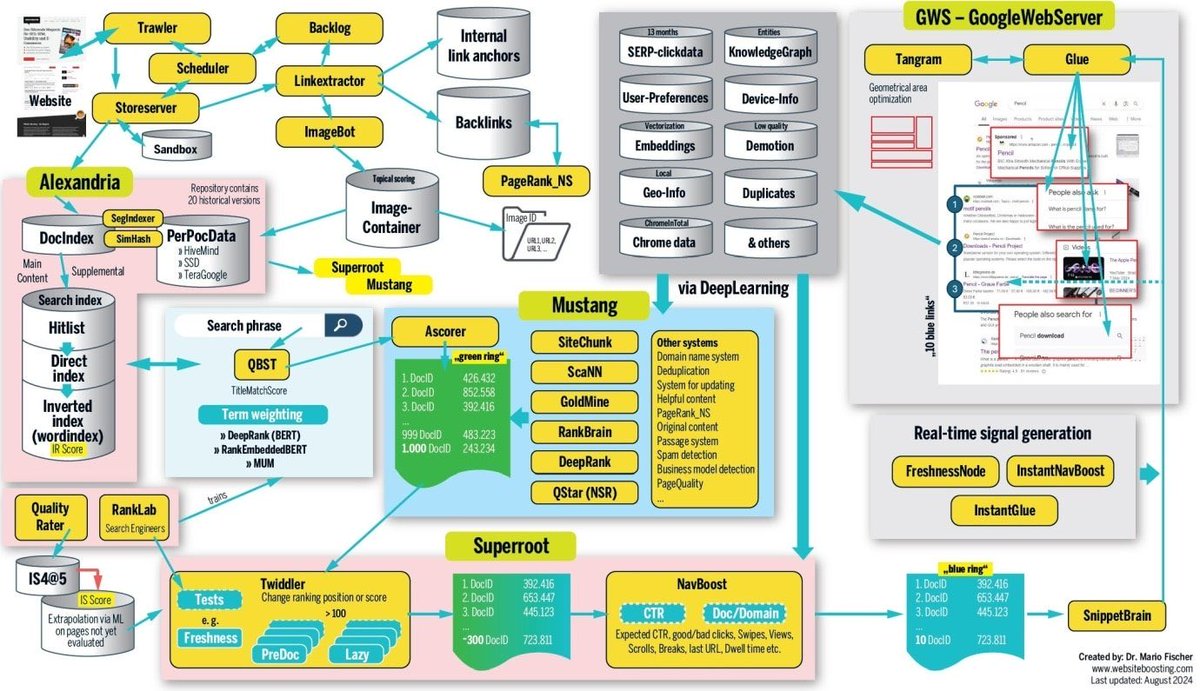
高级RAG技术指南:从预检索到生成
这是一份关于15种高级RAG(检索增强生成)技术的全面指南,分为4个主要阶段:
00 - 预检索和数据索引技术
1. 使用LLM增加信息密度
- 利用大型语言模型来提升数据的丰富性和详细程度。
2. 应用分层索引检索
- 通过分层次地组织和检索数据,提升检索效率。
3. 使用假设问题索引改善检索对称性
- 通过创建假设问题来平衡和优化数据的检索对称性。
4. 使用LLM删除数据索引中的重复信息
- 利用大型语言模型清理数据中的冗余信息,确保数据简洁高效。
5. 测试和优化分块策略
- 研究并优化将大数据集拆分为更小块的策略,以提高处理效率。
01 - 检索技术
6. 使用LLM优化搜索查询
- 利用大型语言模型来改进搜索查询的精准度。
7. 使用假设文档嵌入(HyDE)解决查询-文档不对称问题
- 应用假设文档嵌入方法,平衡查询和文档之间的信息不对称。
8. 实现查询路由或RAG决策模式
- 构建查询路由系统或决策模式,以便更智能地处理检索请求。
02 - 检索后技术
9. 使用reranking优先处理搜索结果
- 对初步搜索结果进行重新排序,以突出最相关的信息。
10. 使用上下文提示压缩优化搜索结果
- 利用上下文提示压缩技术,提高搜索结果的相关性和简洁性。
11. 使用校正RAG对检索到的文档进行评分和过滤
- 应用校正后的RAG模型,对获取的文档进行评分和过滤,提升精度。
03 - 生成技术
12. 使用思维链提示调整噪音
- 应用思维链提示方法,减少生成内容中的噪音,提高质量。
13. 使用Self-RAG使系统具有自反性
- 引入自反性,使系统能够自我评估和改进生成内容。
14. 通过微调忽略不相关上下文
- 调整模型以忽略无关背景,提高生成内容的相关性。
15. 使用自然语言推理使LLM对不相关上下文具有鲁棒性
- 利用自然语言推理能力,使大型语言模型能够抵御无关背景干扰。
04 - 其他潜在改进
- 微调嵌入模型:调整嵌入模型以优化性能。
- 使用GraphRAG:将知识图谱整合到RAG系统中,提升知识连接与利用效率。
- 使用长上下文LLM:如Gemini 1.5或GPT-4 128k,用于替代传统分块和检索方法,实现更长上下文处理能力。
报告下载地址:

OpenAI阻止伊朗的秘密影响行动
OpenAI发现了一些账户,这些账户与伊朗的一个秘密影响行动有关。这些账户使用ChatGPT生成内容,讨论多个话题,包括美国总统竞选。虽然这些内容并没有被广泛传播,但OpenAI还是决定封禁这些账户。
OpenAI的声明
OpenAI致力于防止滥用和提高AI生成内容的透明度。他们正在努力检测和阻止试图操纵公众舆论或影响政治结果的秘密影响行动(IO),这些行动通常会隐藏背后操作者的真实身份或意图。尤其在2024年,有很多选举要举行,防止这种情况变得尤为重要。OpenAI在这一年里扩展了这方面的工作,通过利用他们自己的AI模型来更好地检测和理解滥用行为。
猜测OpenAI为何这样做
1. 维护平台可信度
- OpenAI需要确保其平台不会被滥用来传播虚假信息或进行政治操纵,以维护其可信度和公信力。
2. 防止政治干预
- 在2024年这个选举之年,防止外国势力通过人工智能技术干涉美国等国家的选举是至关重要的。通过采取措施,OpenAI可以帮助维护选举的公平性和透明度。
3. 法律与道德责任
- OpenAI有责任确保其技术不会被用于非法或不道德的行为。这不仅是对用户负责,也是对社会负责。
4. 提升用户体验
- 通过清除不良内容和滥用行为,OpenAI可以为用户提供更可靠和安全的使用环境。
5. 技术优化
- 利用自身AI模型来检测和防止滥用行为,也有助于OpenAI进一步优化其技术,提高模型的安全性和准确性。
综上所述,OpenAI这样做不仅是为了保护其平台免受滥用,还为了维护社会公共利益,确保选举公正,并履行其法律与道德责任。这也反映了他们在不断改进技术以应对新挑战方面所做出的努力。 
11月1-3号 硅谷南湾最大的生成式AI大会 https://t.co/Ok3bBTEYIZ 欢迎大家👻
AI生态系统全景图:应用与基础设施的全面解析
这张图片展示了当前AI生态系统中的主要公司和项目,按照应用和基础设施两个大类进行分类,并进一步细分为各个子领域。以下是详细总结:
应用层
横向应用
- 企业(Enterprise)
- Ema、Orby AI、HERCULES AI、zeta labs、KLARITY、Lindy、https://t.co/GjZ7uychXp
- 这些公司主要专注于企业级AI解决方案,提供自动化、数据分析和决策支持等服务。
- 消费者(Consumer)
- MultiOn、Minion AI、Rewind、NOX
- 面向消费者的AI应用,包括个人助理、娱乐和生活辅助等。
垂直应用
- 金融(Finance)
- Norm Ai、Casca、Parcha
- 专注于金融行业的AI解决方案,如风险管理、投资分析和金融数据处理。
- 法律(Legal)
- Harvey., Legal Fly, Leya
- 提供法律服务自动化、文档分析和合规性检查等AI工具。
- 医疗保健(Healthcare)
- Hippocratic AI, https://t.co/kMsHBdkF7m, ABRIDGE
- 医疗保健领域的AI解决方案,包括诊断辅助、患者管理和健康数据分析。
- 客户支持(Customer Support)
- COGNIQ, Moven AGI, DECAGON, SIERRA
- 提供客户支持自动化和智能客服解决方案。
- 销售与市场推广(Sales & GTM)
- ARTISAN, https://t.co/A7rfIUrhA5, 11x, enso
- 专注于销售和市场推广的AI工具,如客户关系管理和市场分析。
软件开发(Software Development)
- 包括多家公司,主要提供软件开发相关的AI工具,如代码生成和自动化测试。
基础设施层
数据与记忆(Data & Memory)
- FalkorDB, pgvector, Weaviate, PINECONE, DATAVOLO,
MemGPT
- 提供数据存储和处理解决方案,支持大规模数据管理与访问。
框架(Frameworks)
- 包括LangChain, DSPy, griptape, maisa
- 提供开发框架,帮助构建和部署AI模型及应用。
工具(Tooling)
- Browserbase, Tiny Fish, Reworkd, WORDWARE
- 各种开发工具,支持代码编写、调试及协作等功能。
编排与评估(Orchestration and Evaluation)
- emergence, https://t.co/Oxkx9vXEad, Braintrust
- 提供模型编排和性能评估工具,帮助优化AI系统的效率与效果。
智能代理模型(Agentic Models)
- H, imbue, ADEPT, essential AI
- 专注于智能代理模型的开发,用于实现复杂任务的自动化处理。
总结
这张图展示了当前AI技术生态系统中的主要参与者,从企业级应用到消费者产品,再到垂直行业的专业解决方案,以及支撑这些应用的底层基础设施。各公司通过提供多样化的产品和服务,共同推动着人工智能技术的发展和普及。这张全景图不仅有助于理解当前AI产业格局,也为企业选择合作伙伴或投资对象提供了参考。 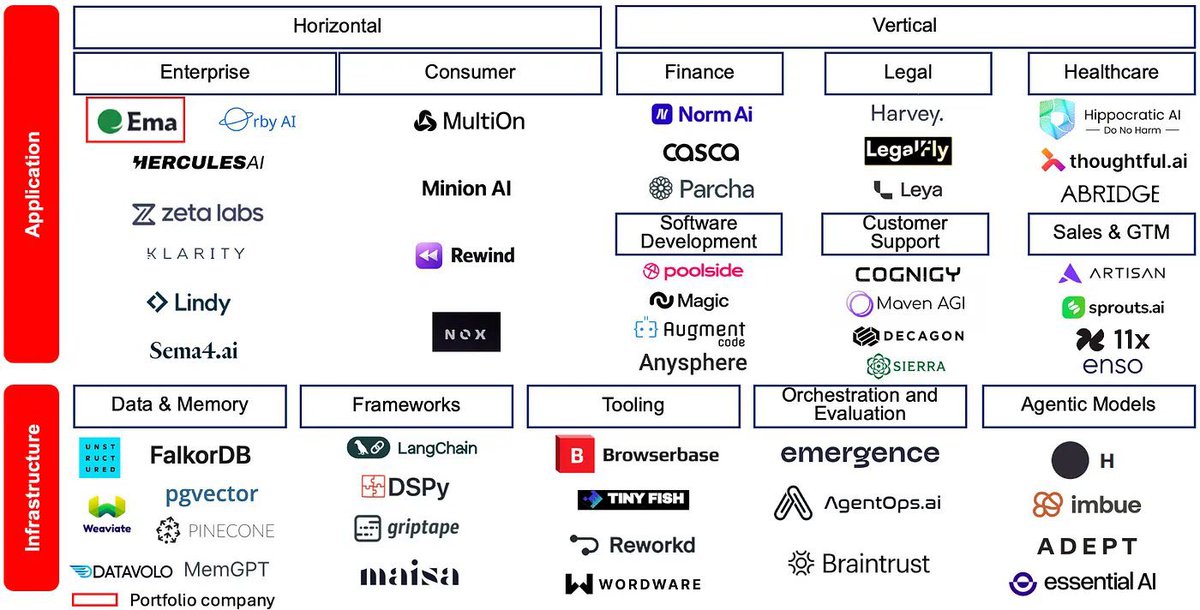

详细的ChatGPT使用指南🔑
旨在帮助用户从初学者到专业人士更好地掌握如何有效地使用ChatGPT。以下是对图中内容的详细解读:
1. 了解术语 (Learn The Terminology)
- Model: 类似于AI的大脑,通过大量数据进行学习。
- Prompt: 用户输入的指令或问题。
- Input: 提供给AI的信息,通常是提示或问题的一部分。
- Output: AI对输入的响应。
- Token: 文本中最小的单位,可以是一个词或字符的一部分。
- Max Tokens: AI可以处理的最大令牌数量。
2. 掌握这些命令 (Master These Commands)
- List: 列出项目、想法或步骤。
- Act as: 假设特定角色以提供定制化回应。
- Continue: 扩展当前讨论。
- Elaborate: 提供更多细节或解释。
- Summarize: 总结信息。
- Identify Gaps: 突出缺失或不完整的元素。
- Pros and Cons: 评估主题的优缺点。
3. 使用这些提示结构 (Use These Prompt Structures)
自定义ChatGPT提示以满足具体需求:
- TREF: Task, Requirement, Expectation, Format
- SCET: Situation, Complication, Expectation, Task
- PECRA: Purpose, Expectation, Context, Request, Action
- GRADE: Goal, Request, Action, Detail, Examples
- ROSES: Role, Objective, Scenario, Expected Solution, Steps
4. 避免在编写提示时犯错误 (Mistakes To Avoid When Crafting Prompts)
1. 避免模糊或封闭式问题:
- 不要问:“你认为我们的网站好吗?”
- 应该问:“你能具体说明我们网站上的哪些页面对你最有用,并说明原因吗?”
2. 别忘了以用户为中心:
- 不要问:“我们的产品有什么问题?”
- 应该问:“使用我们的产品时,你面临哪些挑战?我们可以做些什么来改善你的体验?”
5. 使用这些参数 (Use These Parameters)
控制模型生成内容的方法:
- Temperature:控制生成内容的“创造性”,值越高生成内容越多样化,值越低生成内容越保守。例子:`Simulate a 'temperature' value of 1 in our conversation.`
- Diversity_penalty:较高的多样性惩罚会导致输出更加多样化和重复度较低。例子:`Simulate a 'diversity_penalty' value of 0.9 in our conversation.`
- Presence_penalty:较高的存在惩罚会导致输出更多的新词汇和短语。例子:`Simulate a 'presence_penalty' value of 0.9 in our conversation.`
- Frequency_penalty:控制模型对频繁出现词汇的惩罚程度。例子:`Simulate a 'frequency_penalty' value of 1 in our conversation.`
- Stop_words:控制模型是否生成“stop words”(如“a”,“the”和“and”)。例子:`Use 'stop_words' value of 0.5 in our conversation.`
语气 (Tone)
不同语气可以使AI适应各种场景,增加其灵活性:
- 专业 (Professional):适用于技术信息、重要更新和正式场合。
- 友好 (Friendly):让互动更舒适,促进轻松交流。
- 热情 (Enthusiastic):激励用户尝试新事物,传达正能量。
- 同理心 (Empathetic):对于支持服务非常有用,可以帮助用户感觉被理解和支持。
- 教育性 (Instructional):提供清晰简洁的指导,非常适合教程和说明书。
- 安慰性 (Reassuring):安抚用户,对缓解焦虑非常有帮助。
- 鼓舞人心 (Inspirational):激励用户采取行动,尝试新功能或深入参与项目。
有用的ChatGPT插件(仅限GPT4)
一些推荐插件包括Noteable、AskYourPDF、Video Insights等,这些插件能增强ChatGPT在不同任务中的表现。
有用的ChatGPT扩展
扩展功能如Superpower ChatGPT、Prompt Storm等,可以增强ChatGPT在互联网访问和文件上传等方面的能力。
附加资源
提供了一些额外资源链接,如PromptStacks、FlowGPT、Github资源库等,以便用户进一步探索和优化ChatGPT使用体验。
通过理解并应用这些技巧和策略,您将能够更有效地利用ChatGPT,实现更精准、更有价值的交互。 
2024欧洲移民一览 https://t.co/NgPFOIaCvT 
巴菲特2024年第二季度持仓曝光(
最新投资组合)
总结:
1. 苹果(AAPL)仍是最大持仓,占比30.09%,但减持了49.33%。
2. 美国银行(BAC)和美国运通(AXP) 分别占比14.67%和12.54%。
3. 可口可乐(KO)和雪佛龙(CVX) 分别占比9.09%和6.63%,其中雪佛龙减持3.55%。
4. 新增仓位中,西方石油公司(OXY) 增加了2.93%,Chubb Limited(CB) 增加了4.28%,Liberty SiriusXM Series C(LSXMK) 增加了6.90%,Sirius XM Holdings Inc.(SIRI) 增加了262.24%。
5. 大幅减持的公司包括:T-Mobile US Inc.(TMUS) 减少10.87%,Liberty Media Corp Formula One Series C (FWONK) 减少9.60%。
这是巴菲特及其公司Berkshire Hathaway截至2024年6月30日的最新投资组合。 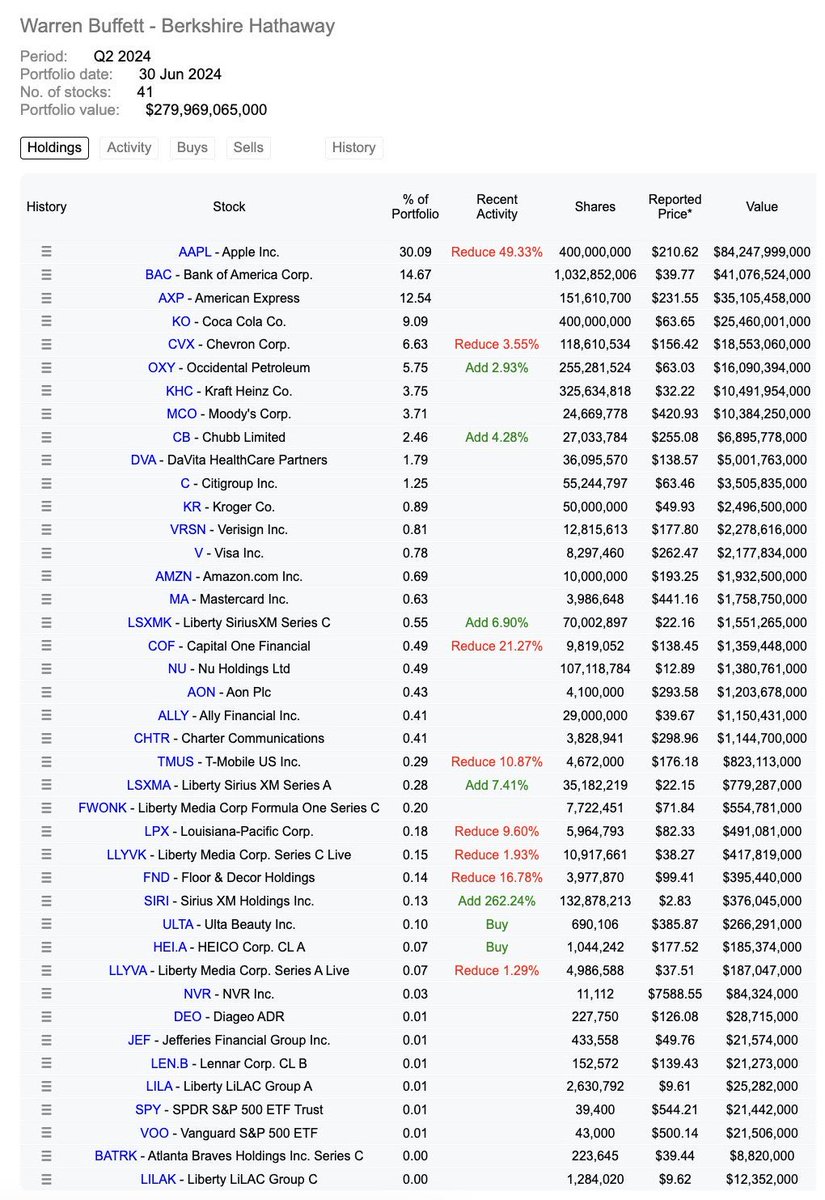
什么是AGI
AGI是“通用人工智能”的缩写,就像一个超级聪明的机器人,它不仅可以学会我们教给它的东西,还能自己学新东西和解决问题。比如,AGI不仅会下棋,还能学会新的游戏技巧,比人类学得更快、更灵活。
与狭义AI的区别:
狭义AI(比如聊天机器人、识别图片的AI)只能做特定任务。而AGI可以做各种不同类型的任务,可以跨领域学习和应用知识。
主要特征:
1. 通用性:能解决各种不同类型的问题。
2. 学习能力:可以自学新知识和技能。
3. 推理能力:能进行复杂的逻辑推理和决策。
4. 适应性:能在新环境中快速适应和学习。
5. 自我意识:可能具有自我意识和情感(但还在讨论中)。
总之,AGI就像一个超级聪明、能自己学东西的小伙伴,能够帮助我们解决很多复杂的问题。 
成为优秀领导者的八个必备素质🔑👻
1. 真实性:他们自知且真实,赢得了别人的信任,大家愿意跟随他们冒险。
2. 好奇心:他们会从他人的角度出发,探索未知,在做决定前先了解情况。
3. 分析能力:他们能够发现模式、趋势和因果关系,从而诊断问题并提出解决方案。
4. 适应能力:他们鼓励团队接受变化,并迅速作出反应。
5. 创造力:他们欢迎各种想法,并考虑所有可能性。
6. 处理模糊性:他们能将矛盾的想法和优先事项连接起来,以更好地应对不确定性。
7. 韧性:他们具有文化敏感度,谦虚地接受建议,并在必要时调整方向。
8. 同理心:他们能够站在员工的角度思考,找到共同点并加以培养。
中心信息是,伟大的领导者是通过培养这些品质而成的,而不是天生就具备的。 
Grok-2:xAI引领人工智能新时代的全新突破
本文介绍了埃隆·马斯克的xAI公司在AI领域的最新进展,特别是Grok-2及其迷你版本Grok-2 mini的发布
1. 模型发布背景:
- xAI公司专注于开发能够理解、推理并生成自然语言文本的高级AI模型。Grok系列旨在推动人工智能在聊天、编程、推理等多个领域的应用,提高模型的智能和实用性。
2. Grok-2的技术创新:
- Grok-2是在Grok-1.5基础上的进一步创新,展示了xAI在大型语言模型领域的深入研究。
- 它采用了先进的混合专家(MoE)模型架构,显著提升了处理复杂问题时的准确性和效率。
3. 核心能力:
- 推理能力:Grok-2优化了逻辑推理和问题解决能力,提高了处理复杂问题的精确性。
- 编码能力:在代码生成方面表现优异,可以帮助开发者快速生成高质量代码。
- 写作能力:能够根据指令或主题生成流畅、连贯的文本内容。
4. 模型性能评估:
- 根据Chatbot Arena测试结果,Grok-2在Elo得分上位列第四,显示出强大的推理竞争力。
- 应用程序研究员Nima Owji对Grok-2给予高度评价,尤其是在代码生成和新闻报道方面。
5. 商业化计划:
- xAI计划通过企业API向开发者提供Grok-2和Grok-2 mini,加速AI技术商业化进程。
- 预计API将提供多种功能,以满足不同行业和场景需求。
6. 未来展望:
- Grok-2有望在处理复杂问题和高级推理任务上进一步提升性能,同时扩展上下文理解能力,为用户提供更加丰富的多模态交互体验。 
据https://t.co/St5O59mmxt分析,这段话是在讨论Grok-2这款最新的人工智能模型,它在性能上非常出色。具体来说:
1. SOTA模型:Grok-2被认为是“State of the Art”的模型,也就是最先进的模型之一。
2. 性能对比:
- 虽然在某些方面略逊于Sonnet和GPT-4o,但它几乎与Llama-405b持平。
- 在一些关键基准测试上,如MMLU Pro和Human Eval(编程能力测试),Grok-2优于Gemini Pro。
3. 即将发布的企业API:
- 令人兴奋的是,他们很快会发布一个企业API,并且这个API是未经过滤的(uncensored),这意味着可能会有更大的应用潜力。
4. 市场认可:
- 作者对于能够在ChatLLM中集成Grok-2感到非常期待,并且认为有更多优秀的玩家进入市场是件好事。
总之,这段话表达了对Grok-2模型性能的认可和对其未来应用的期待。
AI监管的两难选择:加州SB-1047法案与科学家的反对声
1. 广泛的监管范围:
- 法案将市面上绝大多数的大型AI模型定义为“风险”,要求对其进行额外监督。这包括使用超过10^26次计算的模型,几乎涵盖了所有主流的大型AI模型。
2. 对下游应用的严格限制:
- 要求开发者在部署前进行安全评估,具备紧急关停能力,并对任何下游不当使用负责。这种连带责任制被认为是不合理的,因为开发者难以控制用户如何使用他们的技术。
3. 限制开源开发:
- 法案要求超过特定规模的模型必须包含紧急停止装置,这可能会限制开源项目的发展,因为开源社区可能无法满足这些苛刻要求。
4. 吹哨人保护条款:
- 鼓励内部举报不合规行为,并保护举报者免受报复。这虽然是为了促进合规,但也可能导致企业内部紧张和不信任。
5. 信息备案要求:
- 要求在出售算力资源时收集客户详细信息,这被认为过于侵入性并增加了企业负担。
科学家们认为,该法案不仅可能抑制创新,还可能使加州失去其作为全球人工智能中心的地位。他们担心严格的监管将阻碍技术进步,而不是促进安全使用。由于这些原因,李飞飞、吴恩达、LeCun等众多知名科学家联名抗议这项法案。更多详情可以查看原文链接:https://t.co/813jhV5LvR。 
OpenAI最新发布的模型「chatgpt-4o-latest」具有以下六大亮点及其场景应用:
1. 多步分解推理能力:
- 亮点:内置Q 🍓,增强了复杂问题的分解和逐步解决能力。
- 场景:在需要逻辑推理的编程挑战中,模型可以一步步指导用户完成复杂算法。
2. 草莓测试专用问题处理:
- 亮点:能够有效应对特定设计的复杂问题集。
- 场景:在学术研究中,可以用于验证假设或模型性能,通过复杂问题测试模型的智能水平。
3. 高级技术领域应用:
- 亮点:在技术领域(如编程、数学)表现出色。
- 场景:开发者可以利用此模型来进行代码审查或优化算法,提高开发效率。
4. 增强的指令遵循能力:
- 亮点:能够更好地理解和执行复杂指令。
- 场景:在企业流程自动化中,该模型可以被训练成一个高效的虚拟助手,管理日常任务。
5. 改进的长文本处理能力:
- 亮点:处理长文本和多轮对话更加流畅。
- 场景:在客户服务中,可以提供连续且一致的信息反馈,提高用户体验。
6. 多模态扩展能力(潜力):
- 亮点:虽然当前版本主要侧重文本,但未来可能扩展到图像、语音等多模态交互。
- 场景:结合图像识别功能,可能用于教育领域,为学生提供可视化学习材料和互动式教程。
这些功能提升使得「chatgpt-4o-latest」成为一个强大且灵活的工具,适用于各种复杂应用场景。 
根据https://t.co/St5O59mmxt的分析,谷歌Gemini Live的十大功能亮点及场景示例如下:
1. 多模态识别:
- 亮点:支持自然语言、图像、视频和语音识别。
- 场景:用手机拍摄一幅画,Gemini Live能立即讲解其历史背景。
2. 实时互动:
- 亮点:用户可随时打断对话,进行即时交流。
- 场景:在讨论旅行计划时,可以随时调整行程安排。
3. 应用整合:
- 亮点:访问邮箱、地图和通讯录,实现自动化操作。
- 场景:直接通过语音助手预约餐厅或发送邮件。
4. 图像生成:
- 亮点:可以生成特定用途的图片。
- 场景:为朋友的生日创建个性化祝福图片。
5. 多语言支持:
- 亮点:提供10种语音选择和45种语言。
- 场景:在国外旅行时,使用不同语言与当地人交流。
6. 跨平台兼容:
- 亮点:计划扩展到iOS系统。
- 场景:iPhone用户也能享受相同的智能助手服务。
7. 谷歌生态集成:
- 亮点:与谷歌邮件、云盘等无缝连接。
- 场景:快速查找并分享云端文件。
8. 语音激活启动:
- 亮点:通过简单指令启动助手。
- 场景:“Hey Google”即可开始查询天气或设置提醒。
9. 扩展应用支持:
- 亮点:未来将集成更多应用,如Keep、Tasks等。
- 场景:管理日常待办事项更加高效便捷。
10. 市场快速占领:
- 亮点:迅速推出抢占市场先机。
- 场景:在新手机发布会上快速演示新功能,引起用户关注。
这些功能让Gemini Live成为一个强大且实用的智能助手,适用于各种日常生活和工作情境。 
最新的OpenAI ChatGPT-4o(20240808版本)在过去一周内通过"anonymous-chatbot"进行了测试,并且获得了超过11,000次社区投票。
OpenAI成功地重新夺回了第一的位置,以1314分的惊人成绩超越了谷歌的Gemini-1.5-Pro-Exp!
新的ChatGPT-4o在技术领域表现出显著改进,特别是在编码能力方面,比之前的GPT-4o-20240513版本提高了30多分。此外,它在指令执行和处理复杂提示方面也有显著提升。
恭喜OpenAI取得这一非凡成就!
新的ChatGPT-4o分类排名如下:
- 综合排名:1
- 数学:1-2
- 编码:1
- 复杂提示处理:1
- 指令执行:1
- 长查询处理:1
- 多轮对话:1
更多图表见下方👇
如果你想了解更多详细信息,可以查看原始推文链接:https://t.co/RvcQ8PnXLF。 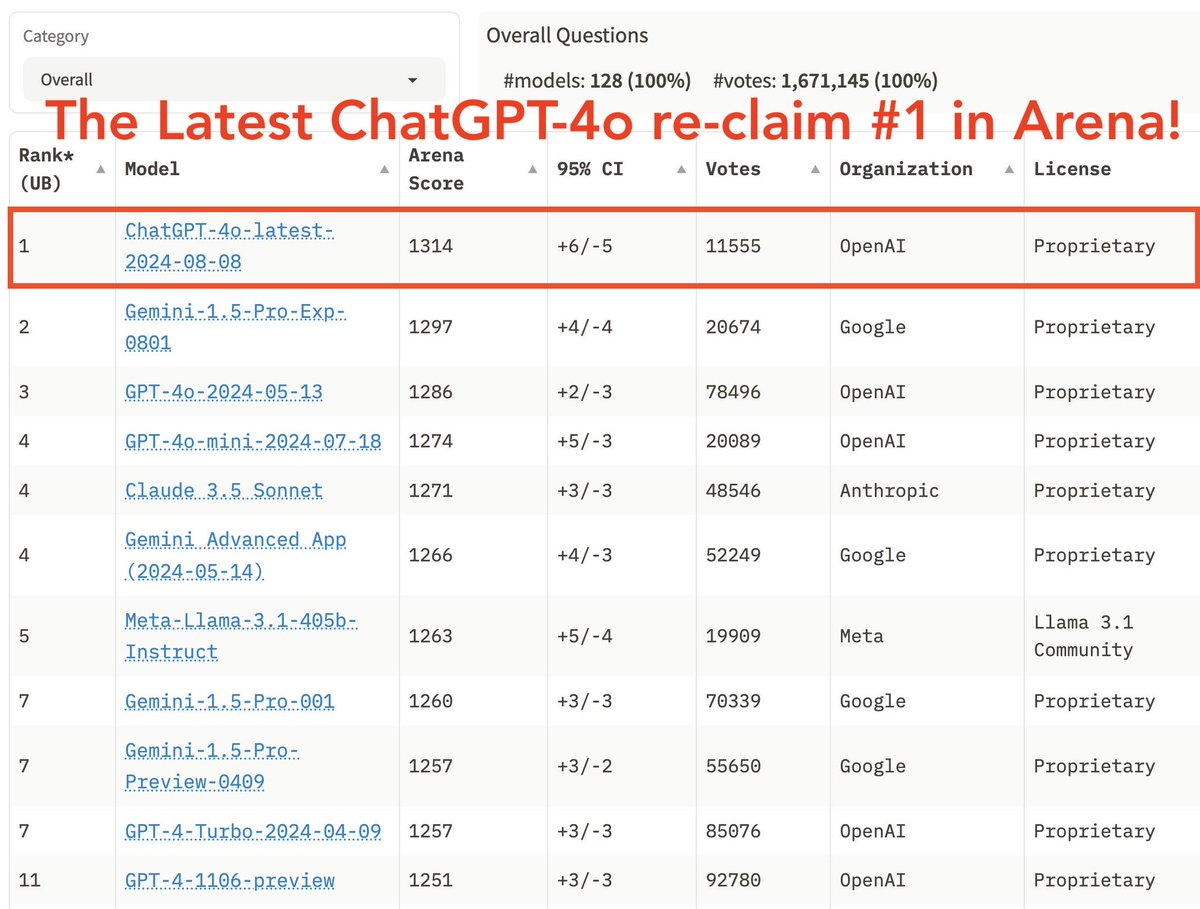
OAI这条推特的核心内容是关于SWE-bench的新版本发布。SWE-bench是一个用于评估AI模型解决实际软件问题能力的工具。这次更新是与原作者合作进行的,旨在更可靠地评估AI在处理现实世界软件问题上的表现。
具体来说,SWE-bench是一种基准测试方法,专注于模拟真实的软件开发场景,以测试AI模型如何理解和解决软件问题。通过这种方式,开发者可以更好地了解不同AI模型在实际应用中的能力和局限性。这也意味着新版本的SWE-bench可能会有改进,使其更加精确或全面地评估AI的性能。
这个推特的信息对于关注AI在软件工程领域应用的人士来说是一个重要更新,因为它不仅展示了当前技术的发展,还为未来的改进提供了基础。如果你想进一步了解,可以查看原始推文链接:https://t.co/P1vHRjAQQ2。
本次巴黎奥运会美国总共获得 126 块奖牌,加州的四所大学包揽了其中的 89块奖牌,占比约 71%!这四所大学是:斯坦福大学、UC Berkeley、南加大 (USC) 和 UCLA。 https://t.co/cUUJSxJHma 