爱情的生物学奥秘:大脑如何引导浪漫情感
这张图深入解析了爱情的生理过程和大脑在这一过程中扮演的角色。
大脑中的爱情区域
- 海马体、内侧脑岛、前扣带回:
- 这些区域负责调节奖励感受,是爱情形成的核心。
- 下丘脑:
- 产生多巴胺、催产素和加压素,这些化学物质是坠入爱河的关键。
- 垂体腺:
- 调节并分泌激素,维持身体内的化学平衡。
- 杏仁核:
- 在爱情中,减少恐惧和压力感。
坠入爱河的五个步骤
1. 多巴胺释放:
- 下丘脑释放多巴胺,引发兴奋和狂喜。
2. 血清素水平变化:
- 血清素下降,可能导致痴迷或迷恋,类似强迫症状。
3. 神经生长因子(NGF)增加:
- 新恋情中NGF水平高,维持浪漫情感的强度。
4. 催产素和加压素作用:
- 增强联系和承诺感,有助于长期关系的发展。
5. 大脑活动变化:
- 爱情影响大脑不同部分,标准变得模糊,人们更容易接受伴侣的不完美。
身体敏感热点
- 包括眼睑、耳朵、脖子等部位,这些区域对刺激非常敏感,可引发性兴奋。
总结
这张图揭示了爱情背后的复杂生物学机制,通过科学视角帮助我们理解浪漫关系中的神经活动,为探索人类情感提供了新的洞察力。 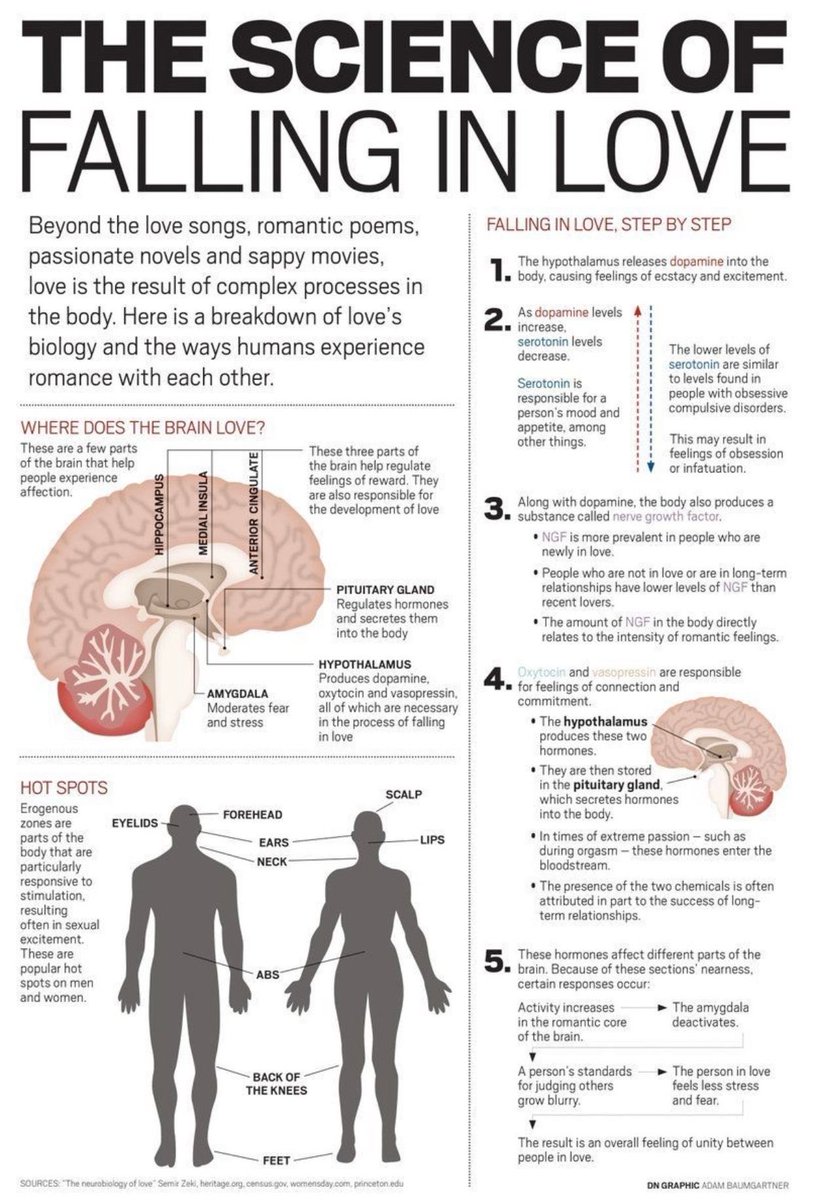
数据科学金字塔:从数据采集到深度学习的全景之旅
1. 数据收集(Collect):
- 通过工具、日志、传感器等手段收集外部和用户生成的数据。这是数据处理的基础,由数据基础设施工程师负责。
2. 数据移动与存储(Move/Store):
- 确保数据流动的可靠性,使用ETL管道和结构化及非结构化存储技术。数据工程师在这一层级发挥关键作用。
3. 探索与转换(Explore/Transform):
- 包括数据清洗、异常检测和准备工作,为后续分析提供干净的数据集。
4. 聚合与标注(Aggregate/Label):
- 利用分析、指标、分段和特征提取等方法创建训练数据。此阶段由数据科学家和分析师负责。
5. 学习与优化(Learn/Optimize):
- 通过A/B测试、实验和简单的机器学习算法进行优化,以实现人工智能和深度学习目标。机器学习工程师在此阶段引领创新。
该图展示了从基础的数据收集到复杂的深度学习模型开发的完整流程,每个阶段都由不同专业人员负责,体现了数据科学领域的多样性和复杂性。 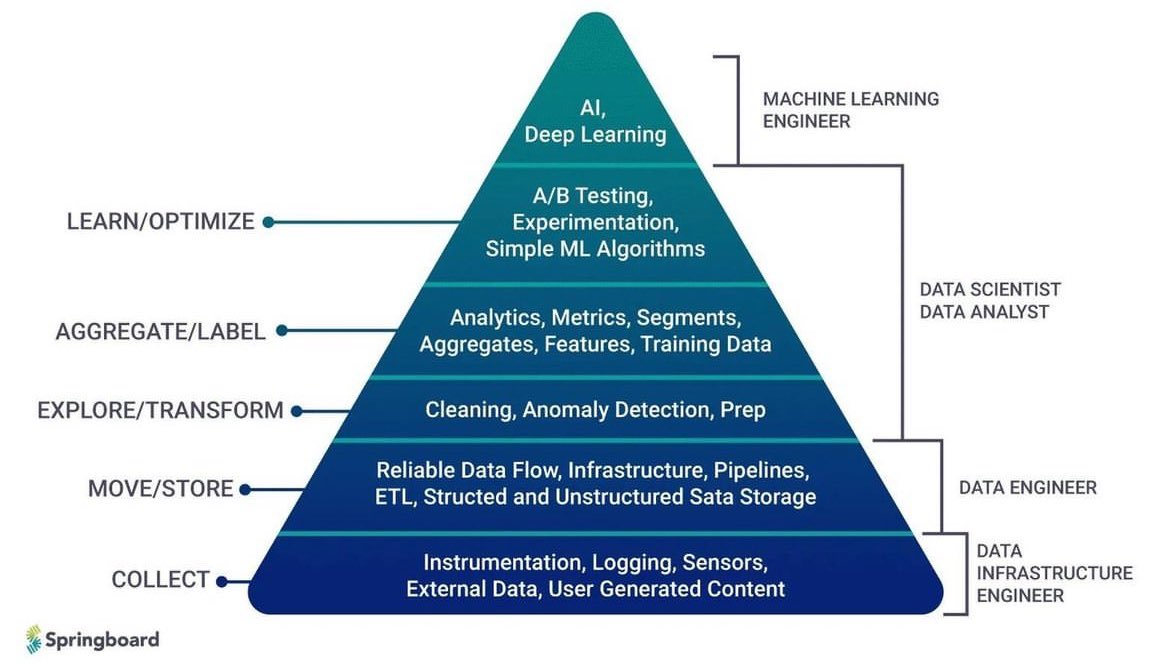
探索简单线性回归的基础理论
1. 简单线性回归简介:
- 简单线性回归是一种基本的统计回归方法,用于预测分析。其核心是通过一个自变量和一个因变量找到线性关系。
2. 计算方法:
- 回归线方程为 \( Y_i = Ax + B \),其中 \( A \) 是斜率,\( B \) 是截距。通过这些参数,可以确定最佳拟合线。
3. 定义最佳拟合:
- 最佳拟合线是误差最小的直线。残差(误差)是预测值与实际值之间的差异。
4. 数学获取方式:
- 使用均方误差(MSE)来优化 \( A \) 和 \( B \)。梯度下降法用于优化损失函数,以减少所有数据点的 MSE。
5. 评价指标:
- 常用指标包括决定系数 \( R^2 \) 和均方根误差(RMSE)。
6. 应用假设:
- 变量之间需要线性关系。
- 残差应独立且正态分布。
- 残差具有恒定方差。
此图为学习简单线性回归提供了清晰的概述和计算步骤,是理解基础机器学习理论的重要资源。 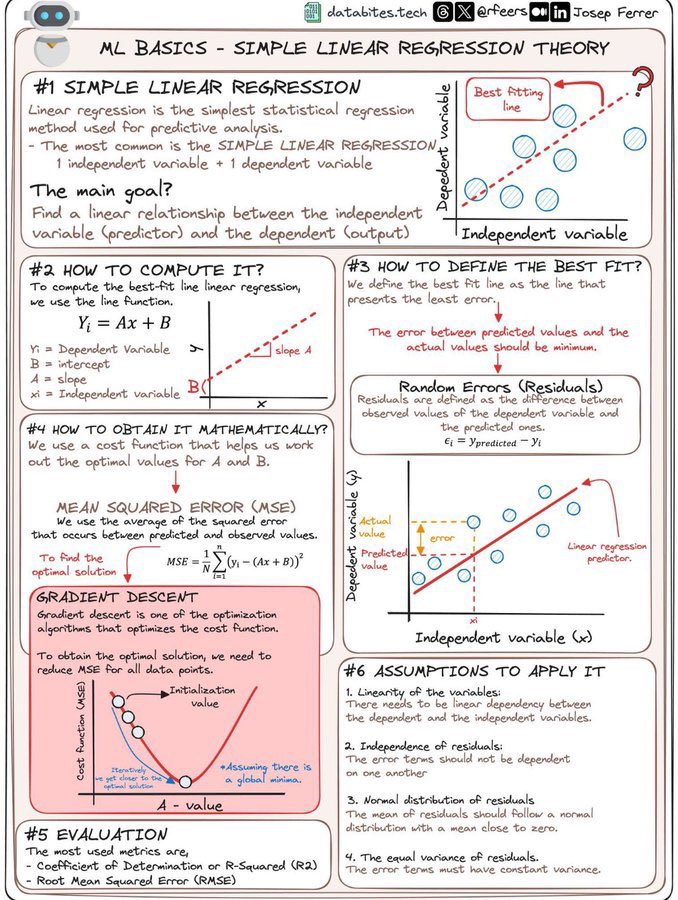
探索机器学习的宇宙:全面解析流行模型
这幅图详细展示了各种流行的机器学习模型及其分类,帮助我们理解每种方法的应用场景和特点:
1. 监督学习:
- 分类:用于将数据点分入预定义的类别中,如kNN、逻辑回归、朴素贝叶斯、决策树和支持向量机(SVM)。
- 回归:预测连续值输出,包括线性回归、多项式回归、Lasso和Ridge。
2. 无监督学习:
- 聚类:将数据分组为自然形成的集群,如k-means、DBSCAN和模糊C均值。
- 模式搜索:如Apriori和ECLAT,用于发现数据中的频繁模式。
- 降维技术:PCA、LDA等,用于减少特征数量,提高计算效率。
3. 强化学习:
- 使用如Q-Learning和深度Q网络(DQN),用于训练智能体在环境中通过奖励机制进行决策。
4. 神经网络:
- 多层感知机(MLP):基础前馈神经网络。
- 卷积神经网络(CNN):擅长处理图像数据。
- 循环神经网络(RNN):处理序列数据,如时间序列分析。
- 生成对抗网络(GAN)和变压器(Transformers):用于生成数据和自然语言处理。
5. 集成模型:
- 通过组合多个模型来提高预测性能,包括Boosting(如XGBoost)、Bagging(如随机森林)以及Stacking技术。
每种模型都有其独特的应用场景,了解这些模型可以帮助你在不同的数据科学任务中选择最合适的方法。 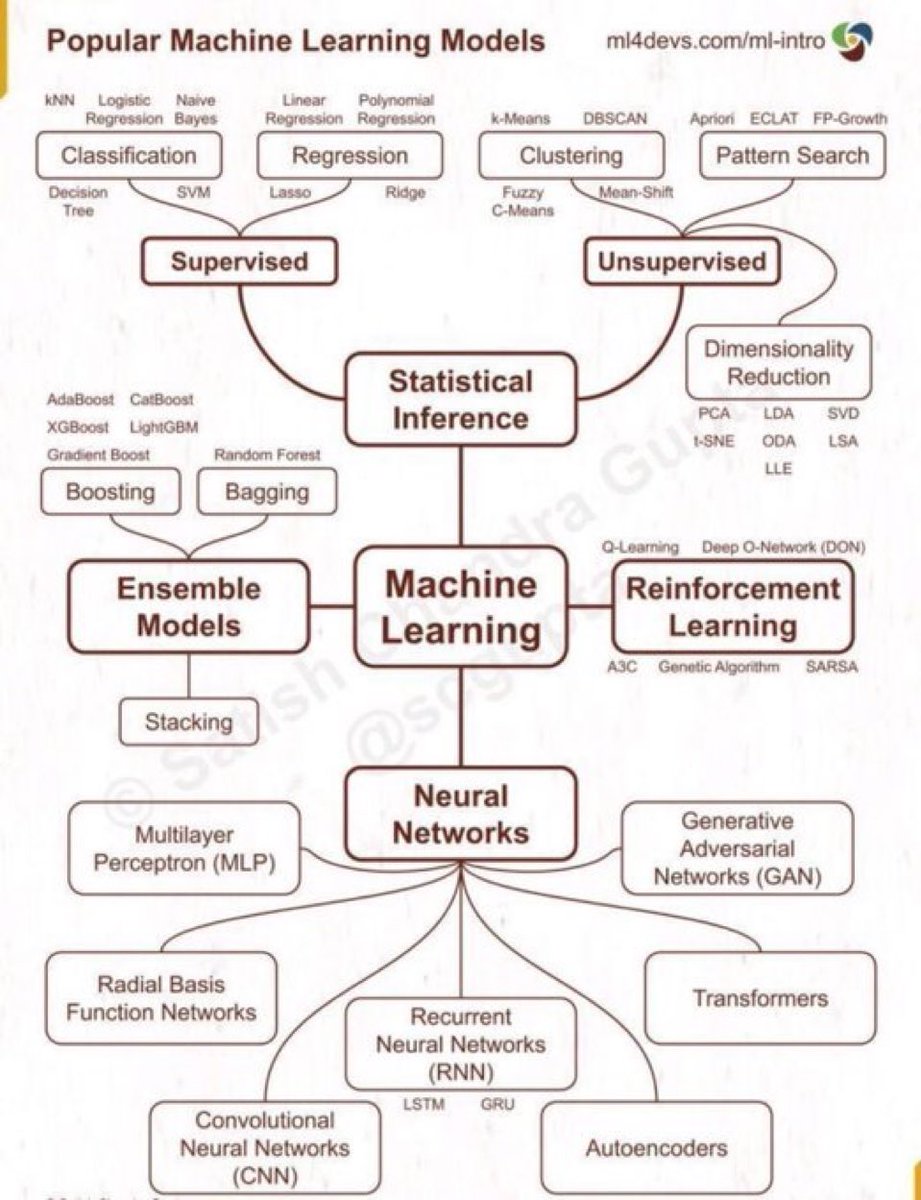
解锁高效生活:全面掌握80/20法则
这幅图深入解析了如何应用80/20法则,通过聚焦最重要的20%努力来实现80%的成果,提升生活和工作的效率:
1. 任务优先:
- 策略:将任务按重要性排序,优先完成能够产生最大影响的部分。
- 实施:每天列出待办事项,挑选最关键的任务进行处理,以确保资源和精力用于高效产出。
2. 发挥优势:
- 策略:识别自身最具影响力的技能或特长,并将其作为重心。
- 实施:将其他任务委托给他人或外包,从而专注于发挥最大优势的领域。
3. 活动管理:
- 策略:找到那些耗时多却收效少的活动,并将其剔除或优化。
- 实施:定期审视日常活动,确保每项活动都在为目标贡献价值。
4. 决策简化:
- 策略:关注能显著影响结果的关键因素,从而快速做出明智决策。
- 实施:使用决策矩阵或其他工具,帮助识别并优先考虑重要变量。
5. 学习优化:
- 策略:集中学习那些能带来最多收益的知识和技能。
- 实施:制定学习计划,专注于高效学习方法,如主动回忆和间隔复习。
6. 习惯分析:
- 策略:分析并强化那些能带来积极效果的习惯。
- 实施:通过习惯追踪和反馈调整行为,确保正面习惯持续发展。
7. 人际关系:
- 策略:培育对个人成长和成功最有益的人际网络。
- 实施:定期维护重要关系,通过交流和合作深化连接。
8. 衣橱精简:
- 策略:投资于多功能、高质量服装,减少选择负担。
- 实施:清理衣橱,只保留适合各种场合且频繁使用的服饰。
9. 健康关注:
- 策略:专注于能够显著改善健康状况的核心习惯。
- 实施:优先安排充足睡眠、均衡饮食和定期锻炼,以保持身体机能最佳状态。
10. 物品整理:
- 策略:识别并保留真正需要和常用的物品,其余则捐赠或丢弃。
- 实施:每季度进行一次物品整理,确保生活环境简洁高效。
通过这些详细的方法,你可以有效地运用80/20法则,实现更高效、更满意的人生。 
掌握学习艺术:记忆与知识保持的终极指南!
这幅图展示了如何有效记忆和保留知识的策略,助你成为学习高手:
1. 费曼技巧:
- 选择主题:深入理解一个主题。
- 简单解释:用简单的语言或对孩子解释。
- 识别知识空白:找出并填补理解中的漏洞。
- 精炼解释:提高解释的清晰度和准确性。
- 自我测试:通过测试进一步简化解释。
2. 莱特纳系统:
- 通过逐步减少复习频率,将难题转化为易题。
- 每周三次复习难题、两次中等题、一次易题。
3. 主动回忆:
- 主动提取信息,加强神经连接,而非被动吸收。
4. 六大记忆保持技巧:
- 多样化资源:使用视频、书籍和便利贴等多种学习材料。
- 建立联系:用类比将新信息与熟悉概念关联,便于理解和记忆。
- 深入理解:关注背后的原因,加深理解,使信息更有意义。
- 关注健康:优先保证睡眠、营养和锻炼,维持大脑健康。
- 间隔学习:分散学习时间,避免认知过载。
- 信息分块:将复杂信息分解成小块,逐步学习以防止压倒性负担。
这些方法旨在提升学习效率,使知识更容易被吸收和长期保留。 
黑客神器揭秘:七大震撼工具!
这张图列出了七款顶尖的黑客工具,每一款都具备独特的功能和潜在威胁:
1. Raspberry Pi:
- 小巧便携的计算机,支持Linux系统和GPIO接口。
- 用于学习编程及探索计算技术的入门利器。
2. Rubber Ducky:
- 外观类似U盘,可用于多种攻击,如系统入侵和数据窃取。
- 能注入按键操作和恶意代码。
3. Flipper Zero:
- 多功能设备,能与RFID、NFC等无线信号互动。
- 可克隆访问卡、控制设备,是无线信号黑客的利器。
4. LAN Turtle:
- 隐蔽网络渗透工具,可插入网络中收集信息或进行攻击。
- 适用于网络安全测试和渗透任务。
5. Wi-Fi Pineapple:
- 强大的Wi-Fi侦察工具,可进行中间人攻击。
- 能创建虚假接入点,拦截分析无线流量。
6. Alfa Network Cards:
- 高性能Wi-Fi适配器,能捕获和注入数据包。
- 是无线安全评估的理想选择。
7. Ubertooth One:
- 开源USB设备,配有天线和无线收发器。
- 可监测附近设备的蓝牙信号。
这些工具揭示了网络安全领域的复杂性,也提醒我们加强防范以保护个人和企业的信息安全。 
数据科学的宝库:开启知识的大门!
这幅图展示了一系列数据科学领域的经典书籍,每本书都提供了独特的视角和深刻的见解:
1. 数据库与SQL:
- 《PostgreSQL》和《MySQL Notes for Professionals》提供了关于数据库管理和优化的重要指南。
2. R语言与统计学习:
- 《R for Data Science》和《Advanced R》是学习数据分析和统计模型构建的关键资源。
- 《The Elements of Statistical Learning》深入探讨统计推断和预测模型。
3. 数据挖掘与分析:
- 《Data Mining and Analysis》以及《Data Mining: Practical Machine Learning Tools and Techniques》为理解数据挖掘算法提供了实用方法。
4. 系统安全与可靠性:
- 《Building Secure & Reliable Systems》探讨了构建稳健系统所需的技术和策略。
5. 社交媒体与文本挖掘:
- 《Social Media Mining》和《Text Mining with R》揭示了从非结构化数据中提取信息的方法。
6. 信息检索与可视化:
- 《Introduction to Information Retrieval》和《Data Visualization》帮助读者掌握如何有效地获取和展示数据。
7. 遗传算法与机器学习:
- 《Genetic Algorithms in Search, Optimization, and Machine Learning》介绍了进化计算在优化问题中的应用。
8. 综合指南与手册:
- 《Data Science Handbook》和《An Introduction to Data Science》为初学者和专业人士提供全面的知识框架。
这些书籍构成了一个丰富的知识体系,帮助数据科学家不断提升技能、扩展视野,是进入数据科学世界的必备读物。 
OpenAI 刚刚发布了 Swarm,一个用于构建多智能体系统的轻量级库! https://t.co/w4q6vA0J7Y 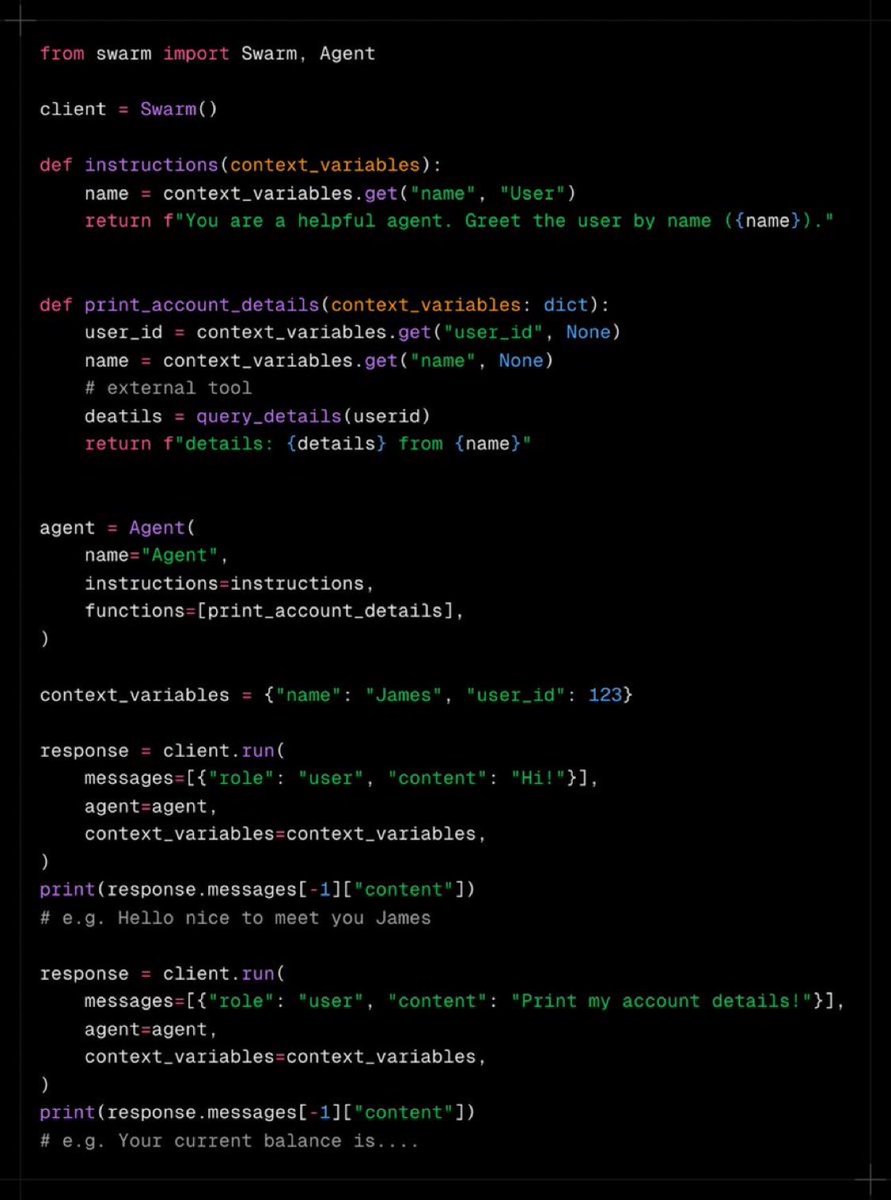
扫码支付揭秘:快速便捷的支付革命!
这张图详细展示了“扫码支付”系统的工作流程:
1. 结账:
- 顾客在商家处进行结账,系统生成订单ID和金额。
2. 订单处理:
- 订单信息(如订单ID SN129803)发送至支付服务提供商(PSP)。
3. PSP处理:
- PSP接收订单信息,生成对应的二维码URL。
4. 二维码生成:
- PSP创建包含订单信息的二维码,并将其返回给商家。
5. 展示二维码:
- 商家在结账柜台展示二维码,供顾客扫描。
6. 顾客扫描:
- 顾客使用数字钱包应用扫描商家的二维码。
7. 付款确认:
- 顾客确认付款,点击“支付”按钮。
8. 支付请求发送:
- 数字钱包应用将支付请求发送至PSP网关。
9. 交易验证:
- PSP验证交易信息,确保资金和订单匹配。
10. 交易确认:
- PSP向商家和顾客双方发送成功通知,确认交易完成。
11. 完成支付:
- 顾客和商家都收到支付成功的确认信息,交易顺利结束。
12. 系统更新:
- 系统记录交易完成状态,确保财务记录准确无误。
这种流程确保了扫码支付的快速性和安全性,使得消费者和商家都能享受便捷的交易体验。 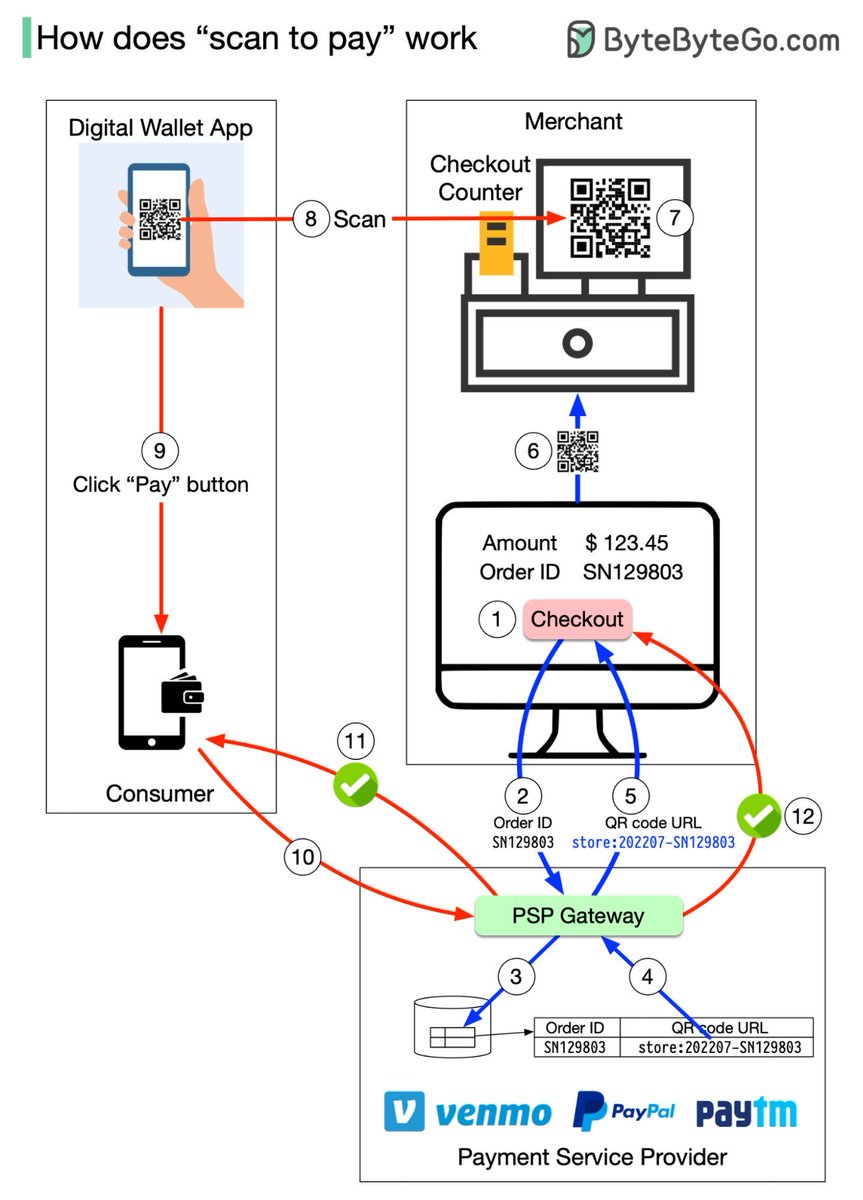
2024必备:九大系统让你脱颖而出!
这张图展示了九个强大的系统,帮助你在2024年实现个人和职业的全面提升:
1. 如何预算:
- 50-30-20法则:收入分配为50%必需品,30%想要,20%储蓄。
- 提高财务管理能力,确保财务健康。
2. 提升魅力:
- SHR方法:让人感到被重视,通过眼神接触、问好问题和记住对方名字来增强魅力。
3. 战胜完美主义:
- 70-20-10法则:大部分工作可能不完美,但少数会非常出色。勇敢面对失败才能取得成功。
4. 如何学习任何东西:
- 费曼技巧:通过教授他人和填补知识空白来加深理解。
5. 如何提供更新:
- 四点状态法:简明扼要地汇报任务进展,突出重点和障碍。
6. 如何做决策:
- 默认拒绝无关请求,专注于优先事项,以提高效率。
7. 从错误中学习:
- 行动后回顾:分析意图、结果和改进措施,以便在未来表现更好。
8. 有效沟通:
- 7-38-55规则:沟通中肢体语言占55%,声调38%,言辞仅7%。
9. 提高生产力:
- 3-3-3计划:每天投入3小时在重要项目上,3小时处理短任务,3小时进行维护活动。
这些策略将帮助你最大化利用时间和资源,实现卓越的个人成长和成就。 
全球眼球👀瞳色揭秘:人类眼睛的神奇多样性!
这张图展示了世界各地不同瞳色的分布比例,揭示了人类眼睛颜色的惊人多样性:
1. 棕色眼睛(70-79%):
- 全球最常见的瞳色。
- 高含量的黑色素使其呈现深色。
2. 蓝色眼睛(8-10%):
- 较为稀有,主要分布在欧洲北部。
- 低黑色素含量导致光散射,呈现蓝色。
3. 榛色眼睛(5%):
- 具有混合特征,通常在阳光下显得更明亮。
- 色素浓度介于棕色和绿色之间。
4. 琥珀色眼睛(5%):
- 独特而罕见,带有金黄色调。
- 由黄色素沉积形成。
5. 灰色眼睛(3%):
- 极为罕见,类似蓝眼但更浅。
- 黑色素含量非常低。
6. 绿色眼睛(2%):
- 世界上最稀有的瞳色之一。
- 多见于中欧和北欧。
7. 红/紫罗兰和异瞳症(各1%):
- 红/紫罗兰:极其罕见,多因遗传或病理原因。
- 异瞳症:双眼颜色不同,是一种独特的遗传现象。
这张图不仅展示了不同瞳色的分布,还强调了黑色素对眼睛颜色的重要影响。这种多样性体现了人类遗传的丰富性和复杂性。 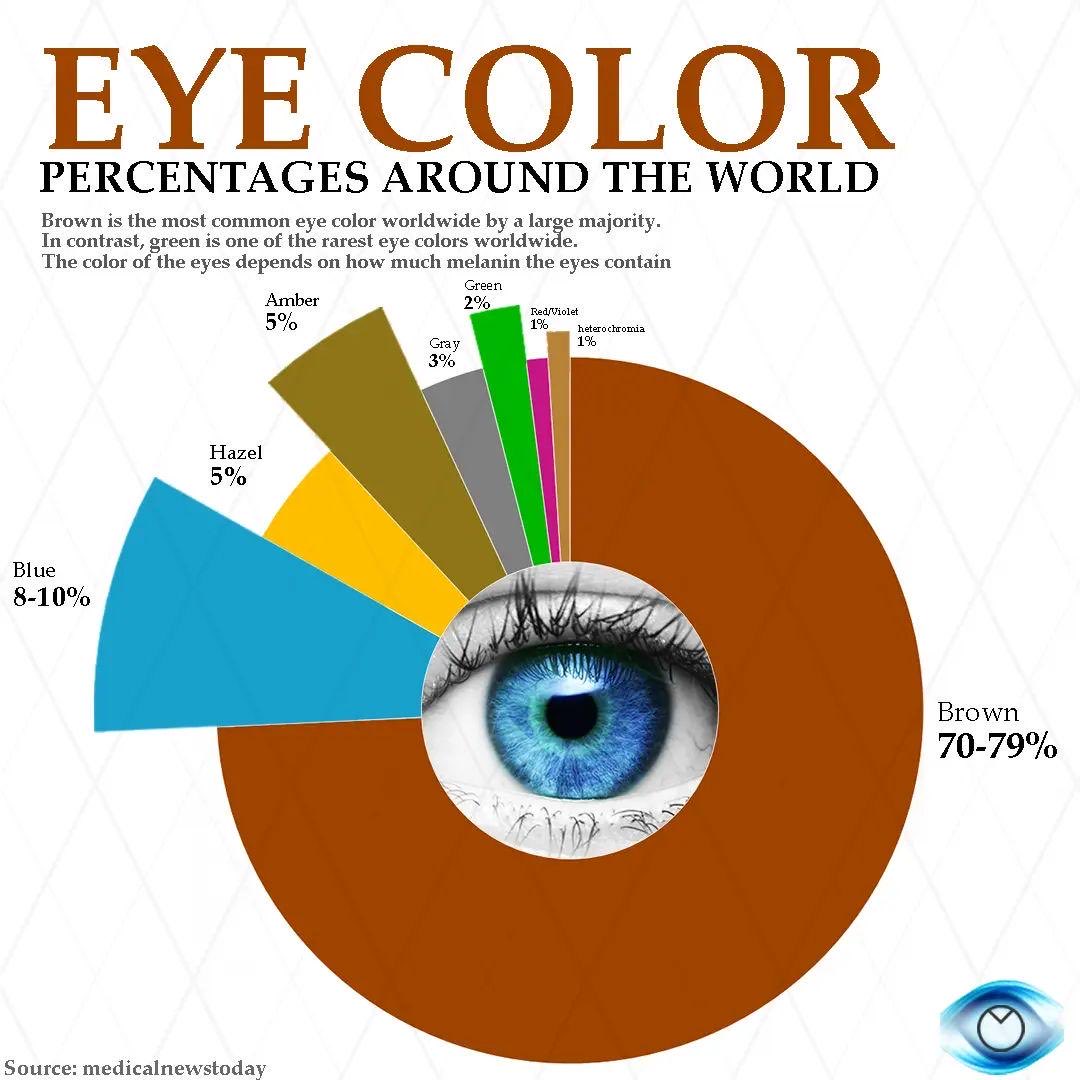
揭开贝叶斯定理的神秘面纱:概率推理的视觉盛宴!
这幅图是贝叶斯定理的可视化证明,帮助理解事件概率之间的关系。
1. 区域表示:
- A和B:分别是两个事件,用不同颜色表示。
- 重叠部分:表示A和B同时发生的概率,即联合概率。
2. 概率符号:
- P(A):事件A发生的概率。
- P(B):事件B发生的概率。
- P(A|B):在B已发生的条件下,A发生的概率(条件概率)。
- P(B|A):在A已发生的条件下,B发生的概率。
3. 贝叶斯定理公式:
\[
P(A|B) = \frac{P(B|A) \times P(A)}{P(B)}
\]
- 用于计算在已知B发生的情况下,A发生的概率。
- 通过计算,展示了如何利用已知信息更新对某事件发生概率的判断。
直观理解:
- 条件概率:图中用形状和颜色区分不同事件及其组合,帮助理解如何从一个事件的信息推导出另一个事件的信息。
- 乘法与除法关系:展示了如何通过乘积和比率关系来计算复杂概率。
这个可视化图解有助于更直观地理解贝叶斯定理在统计推断中的应用。 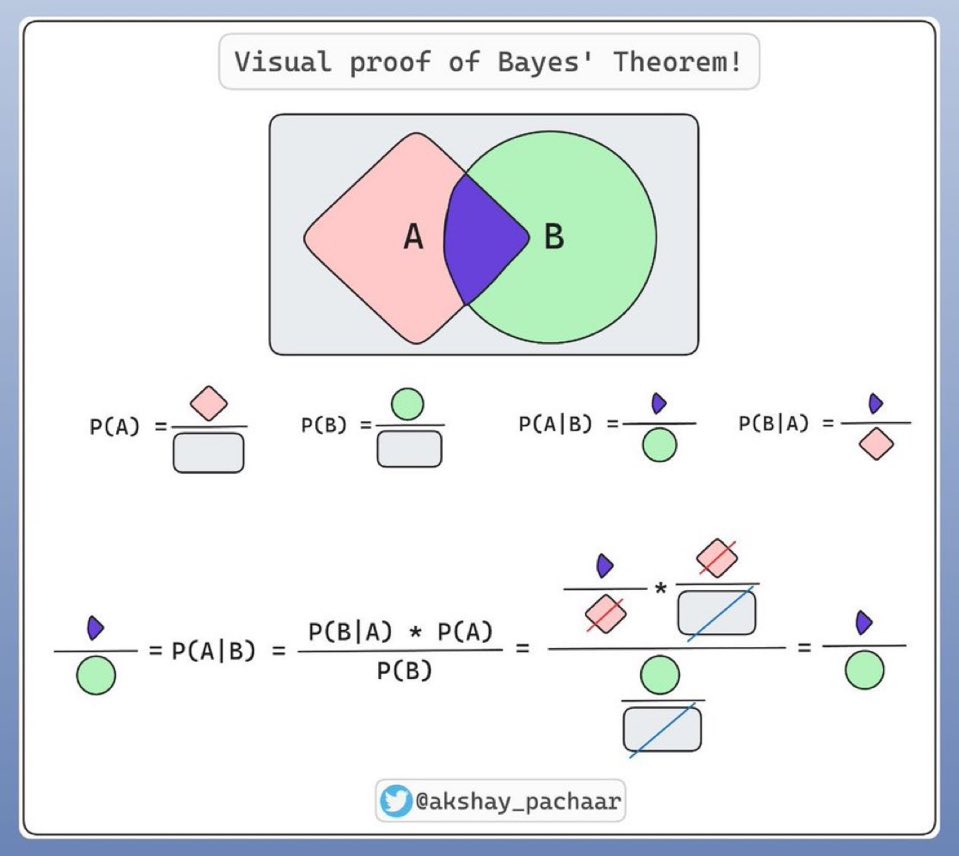
AI学习者的终极书单:从统计到深度学习,全面进阶指南!
这张图展示了一系列关于统计学习、机器学习和深度学习的经典书籍:
1. 《An Introduction to Statistical Learning》:适合初学者,涵盖R语言应用。
2. 《Mathematics for Machine Learning》:提供机器学习所需的数学基础。
3. 《Introduction to Statistics and Data Analysis》:结合练习和解决方案的统计学入门。
4. 《The Elements of Statistical Learning》:深入探讨数据挖掘和预测。
5. 《The Hundred-Page Machine Learning Book》:简明扼要地介绍机器学习的核心概念。
6. 《Deep Learning》:由深度学习领域的专家撰写,是深入理解深度学习的重要资源。
7. 《Forecasting: Principles and Practice》:聚焦时间序列预测。
8. 《Applied Econometric Time Series》:介绍计量经济学中的时间序列分析。
9. 《Bayesian Data Analysis》:详细讲解贝叶斯数据分析方法。
10. 《Python Machine Learning》:探讨使用Python进行机器学习的各种技术。
11. 《Reinforcement Learning: An Introduction》:强化学习领域的重要著作。
12. 《Machine Learning Yearning》:Andrew Ng关于AI项目策略的指导书。
这些书籍为你提供了从基础到高级的全面知识,助你在AI和数据科学领域取得成功。 
网络基础全揭秘:从IP到MAC,全面掌握网络世界的秘密!
这张图详细介绍了计算机网络中的关键概念:
1. IP地址:
- 公有IP:用于连接互联网。
- 私有IP:用于内部网络。
- IPv4和IPv6:IPv4有43亿个地址,而IPv6几乎无限。
- 静态IP与动态IP:静态IP永不改变,动态IP定期变化。
2. MAC地址:
- 是设备的物理地址,由制造商提供,无法更改。
- 用于在网络中识别设备。
3. OSI模型:
- 七层结构,从物理层到应用层,描述网络系统功能。
- 每层有具体的协议和应用,如HTTP、TCP/IP等。
4. TCP/IP模型:
- 四层结构,包括应用、传输、网络和网络接口层。
5. 关键术语:
- DNS:将域名转换为IP地址。
- DHCP:动态分配IP地址。
- ARP:将IP地址关联到MAC地址。
- NAT:实现内部和外部网络的连接。
6. 其他概念:
- VPN:提供加密连接,隐藏IP地址。
- 防火墙和路由器:保护和连接不同网络。
通过这张图,你可以清晰了解计算机网络中的基础知识,从而更好地理解和运用这些技术。 
Apple发布论文质疑:大语言模型数学推理的真相:进步还是假象?
这篇论文主要讲的是大语言模型(LLMs)在解决数学问题时的一些不足之处。研究使用了一种叫GSM8K的基准来测试这些模型在小学数学题上的表现。
虽然这些模型在这个基准上的表现有所提升,但研究人员发现,模型的真正数学推理能力可能没有实际提高。为了更准确地评估这些能力,他们开发了一个新的测试标准,叫GSM-Symbolic。
研究显示,当问题中的数值变化时,模型的表现会有很大不同。此外,如果问题中增加更多的句子,即使这些句子不影响答案,模型的表现也会变差,最多会下降65%。这表明目前的模型缺乏真正的逻辑推理能力,更像是在模仿之前学到的步骤。
总之,这项研究揭示了大语言模型在数学推理方面仍存在许多挑战。 
地球生命的重量级对比:植物主宰,细菌称霸,动物仅是配角!
这张图表令人震撼地展示了地球上不同生物类群的生物量比较。植物以450亿吨碳的压倒性优势占据主导地位,是地球生命重量的绝对霸主。
细菌虽然体积微小,却以70亿吨碳的总量紧随其后,显示出其无与伦比的重要性。
相比之下,所有动物的生物量总和为2.589亿吨碳,其中节肢动物(如海洋中的蟹、虾)占据最大份额,为1亿吨碳。
令人意外的是,人类在这场生命重量赛中仅贡献了0.06亿吨碳,甚至不如蠕虫(0.02亿吨碳)。
这幅图不仅揭示了生命形式的多样性,更让人反思人类在自然界中所处的位置与影响。 
解锁未来:强大AI如何重塑人类命运,迈向150岁寿命的新纪元!
在2024年10月11日,Anthropic的首席执行官Dario Amodei发表了一篇深刻的文章,探讨了强大人工智能(AI)对未来世界的潜力和影响。这篇文章不仅引发了广泛的关注,也激励我们重新思考AI如何塑造人类社会。他提出,尽管AI技术的发展伴随着风险,但其潜力巨大,可以显著提升人类生活质量。Amodei预测,在未来十年内,AI将有能力消除许多疾病,并可能将人类寿命延长至150岁。
强大人工智能的积极潜力
Amodei首先探讨了强大人工智能在多个领域的应用前景。他认为,AI可以在生物健康领域发挥重要作用,通过更精准的医疗诊断和个性化治疗方案,有望消除多种疾病。同时,在神经科学方面,AI能够帮助破解大脑运作的复杂机制,从而推动精神疾病治疗的突破。此外,AI在经济发展中也扮演着关键角色,通过优化资源配置和提高生产效率,实现可持续增长。
面临的风险与挑战
尽管前景广阔,Amodei也不忽视AI发展过程中面临的风险。他指出,大多数人低估了AI可能带来的负面影响,例如隐私泄露、算法偏见和就业替代等问题。因此,他强调需要建立稳健的监管框架,以确保AI技术在安全和可控范围内发展。这包括制定全球标准,加强国际合作,以及推动公众对AI技术及其影响的理解。
AI与社会结构变革
Amodei进一步分析了AI对社会结构可能带来的变革。他提出了一种“数据中心的天才国家”情景:在这种情境中,AI模型具备超越人类顶尖科学家的能力,可以自主进行科研、艺术创作等复杂任务。这种强大的智能体将极大加速科学研究和技术创新,但同时也可能改变劳动力市场结构,需要我们重新定义工作的意义和价值。
智能与经济要素的新关系
在经济领域,Amodei提出需要新的视角来理解智能与传统生产要素之间的新关系。在人工智能时代,智能成为一种关键生产要素,与劳动力、土地和资本相辅相成。我们应关注智能的边际回报,以及如何利用智能来推动经济发展的新模式。
展望未来:希望而非恐惧
最后,Amodei呼吁全球持有一个积极且务实的态度来面对强大人工智能的发展。他强调,希望而非恐惧应成为推动AI技术发展的主要动力。一个鼓舞人心且切实可行的未来愿景,将是团结各方力量应对挑战的重要基础。通过共同努力,我们可以实现一个由人工智能带来的美好未来。
这篇文章不仅是对人工智能未来的一次深刻反思,也为我们指明了努力方向。完整内容可以在相关平台上查看,以深入了解Amodei对强大人工智能发展的洞察。 
解锁AI智能:自动化复杂任务的未来
AI Agent正逐渐成为处理复杂任务的关键工具。正如图中所示,AI Agent通过以下几个步骤来实现任务自动化:
1. 任务描述和计划生成:用户提供任务描述,AI代理接收后开始生成计划。这个过程类似于人脑的运作方式,AI代理在这里展示了其强大的推理能力。
2. 知识库与推理:AI代理访问庞大的任务知识库,并利用其推理模块来理解和分析信息。这一步骤确保了计划的准确性和高效性。
3. 计划审批与执行:生成的计划需要经过批准或编辑,一旦确认无误,AI代理便开始执行。这里展示了LLMs(尤其是o1模型)的卓越推理能力,使得整个过程流畅无比。
4. 工具与数据存储:执行过程中,AI代理调用必要的工具和代码,与任何数据存储交互。这种整合能力使得AI能够灵活适应各种复杂环境。
通过这种方式,AI不仅仅是简单地完成任务,而是如同人类一般思考、规划并执行。这种技术进步不仅提升了效率,还为我们打开了一扇通往智能未来的大门。未来已来,让我们期待更多可能性的实现! 
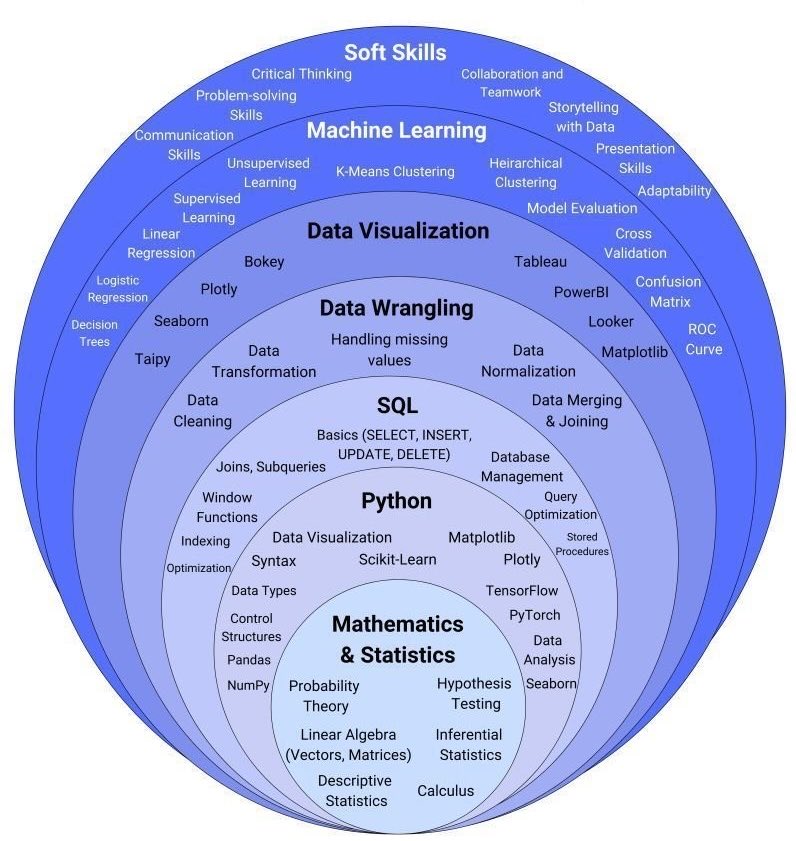
数据科学技能全景图‼️
这张图详细展示了成为一名数据科学家所需的核心技能和知识领域。各个环形层次代表不同类别的技能,从基础到高级依次排列:
1. 数学与统计学:包括概率论、线性代数、微积分等基础知识,这是数据科学分析的根基。
2. Python编程:强调数据处理、可视化和机器学习库,如Pandas、NumPy、Scikit-Learn等。
3. SQL:用于数据库管理和查询优化,掌握基本的SELECT、INSERT、UPDATE和DELETE操作。
4. 数据清洗与整理(Data Wrangling):涉及数据清理、转换和合并等技术,确保数据质量。
5. 数据可视化:使用工具如Tableau、Matplotlib进行数据展示,有助于洞察分析结果。
6. 机器学习:涵盖监督学习与无监督学习,包括K-Means聚类、决策树等模型。
7. 软技能:强调批判性思维、团队合作和数据故事讲述能力,这些都是成功传达分析结果所必需的。
这些技能共同构成了一个全面的数据科学知识体系,为解决复杂的数据问题提供了多种方法和工具。