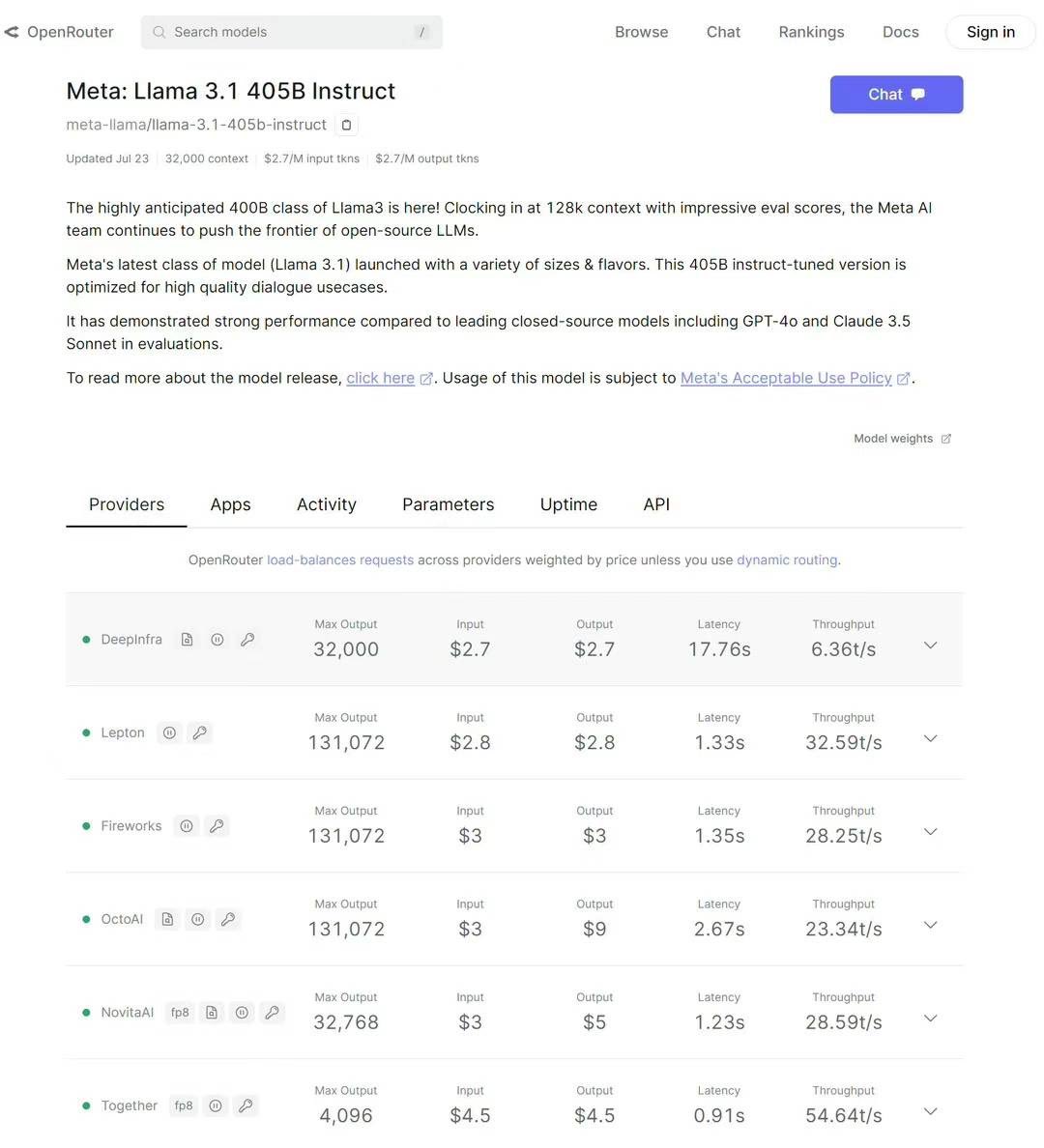
Llama 3.1 405B 模型的性能测评展示了一些重要见解,以下是分析后的主要观点和总结:
1. 模型支持和经济性:
- 几乎所有提供商都迅速支持 Llama 3.1 405B 模型,开源软件和模型的共同开发已经成为常态。我们只需几分钟修改一点 Python 代码就能支持这个模型。
- Llama 3.1 405B 模型的运行成本很高,需要半台或一台机器来运行,每秒处理约 30 个 token。相比之下,70B 模型每秒可处理超过 150 个 token。
- 虽然 Llama 3.1 405B 模型的成本高,但在良好优化和高工作负载饱和度下,仍然可以盈利,不是纯亏钱。对于投资者来说,不要指望这种价格的纯 API 服务能像传统 SaaS 那样有 80% 的利润率。
2. 性能优化和量化:
- LeptonAI API 在速度、价格、并发、成本等多个参数之间做了平衡,以确保可持续性。
- 未来量化将成为标准,FP16 将被 Int8/FP8 取代。精度不下降的前提下,需要进行 per channel / grouped 的量化。
3. 未来预测和模型适用性:
- 预计未来一年左右,Llama 3.1 405B 的效率将提升至少 4 倍。
- 在垂直应用中,70B 模型通常就足够了,很多情况下 8B 通过微调也能很好地工作。Llama 3.1 允许并推荐用户微调自己的模型。
4. 模型支持和推荐:
- Llama 3.1 405B 允许企业/专用部署。我们相信 AI 不仅仅是 API,Lepton AI 构建了一个完整的 AI 云来满足端到端的需求。
据 https://t.co/St5O59mmxt 分析,Llama 3.1 405B 的采用仍会受到速度和价格的限制,但其开源特性和高效优化将使其在未来一年内显著提升效率,成为市场上具有竞争力的模型之一。
有关更多详细信息和企业部署,请联系 Lepton AI。