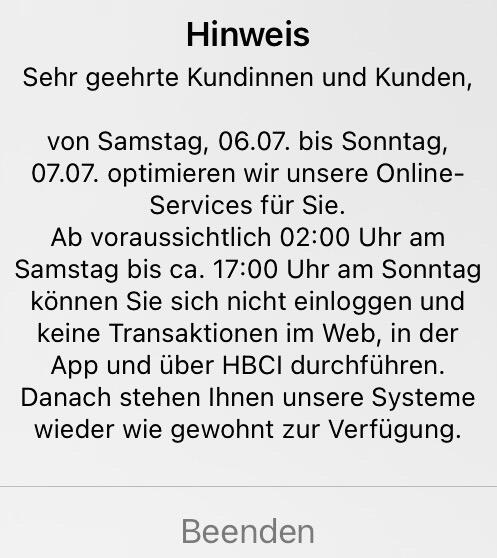
“Dear customers,
from Saturday, July 6th to Sunday,
July 7th we will be optimizing our online services for you. From approximately 2:00 a.m. on Saturday until approximately 5:00 p.m. on Sunday you will not be able to log in or carry out any transactions on the web, in the app or via HBCI. After that our systems will be available to you again as usual.”
👇🏻
In traditional banking, your funds reside on a centralized ledger, which can sometimes become inaccessible due to various reasons. However, it becomes even more concerning when a government controls a single, centralized Central Bank Digital Currency (#CBDC) ledger—a honey-pot of unprecedented amounts of citizens' personal data. Governments evolve over time, and this technology could potentially be misused by totalitarian regimes in an unprecedented way especially in a cashless society. In contrast, #Bitcoin offers reliability. On the Bitcoin network, 8 billion people can transact with digital cash 24/7/365 without needing permission from any central authority. Take a moment to consider this before forming your own opinion.
#StudyBitcoin 🧡