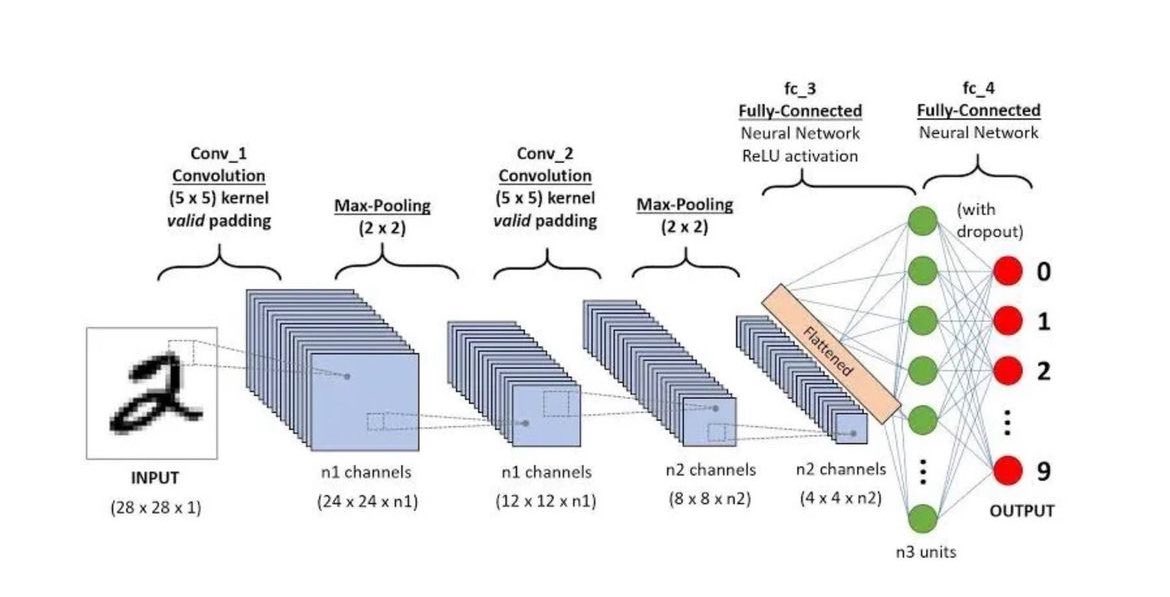
这张图展示了一个卷积神经网络(CNN)如何识别手写数字的过程。让我们用大白话来解读,并配合一些场景,让大家更容易理解。
场景:数字识别
假设你有一张手写的数字图片,比如“2”,你希望计算机能自动识别它是“2”。
1. 输入层(Input):
- 场景:你把手写的“2”扫描成一张28x28像素的黑白图片,输入到模型中。
2. 第一层卷积(Conv_1 Convolution):
- 场景:计算机会用一个5x5的小窗口在整张图片上滑动,每次滑动都会生成一个新的小图,这些小图拼成了一个新的大图(24x24大小),这个过程会提取出图片中的基本特征,比如线条和边缘。
3. 第一次池化(Max-Pooling):
- 场景:接下来,计算机会把刚才生成的大图进行压缩,使用2x2的窗口滑动,每次取窗口内最大值,这样会得到一个更小但信息浓缩的图(12x12大小)。这个步骤叫做池化,它能减少数据量,同时保留重要特征。
4. 第二层卷积(Conv_2 Convolution):
- 场景:再用一个5x5的小窗口在压缩后的图上滑动,再次生成新的特征图,这次的特征更加复杂和高级。
5. 第二次池化(Max-Pooling):
- 场景:再次进行压缩,得到8x8和4x4大小的特征图。这一步进一步浓缩信息,让后续处理更高效。
6. 展平层(Flattened):
- 场景:将4x4大小的特征图展开成一维向量,把所有信息串联起来,为下一步全连接层做准备。
7. 全连接层1(fc_3 Fully-Connected Neural Network):
- 场景:展开的一维向量输入到一个神经网络中,每个节点都与下一层的每个节点相连。通过这种方式,可以综合所有特征,开始做出判断。
8. 全连接层2(fc_4 Fully-Connected Neural Network with Dropout):
- 场景:在这个过程中,还会随机丢弃一些节点连接(Dropout),防止过拟合,使模型更具泛化能力。
9. 输出层(Output):
- 场景:最后,模型输出10个值,每个值对应一个数字(0到9)。哪个值最大,就代表模型认为输入图片是哪个数字。例如,如果对应“2”的值最大,那么模型就判断输入的是“2”。
总结
通过以上步骤,这个卷积神经网络能够自动从输入的一张手写数字图片中提取特征,逐步简化和综合这些特征,最终准确地识别出这个数字。这种方法不仅用于手写数字识别,还广泛应用于各种图像分类任务。
如果你觉得这个解读帮助了你,请给我大大的赞!