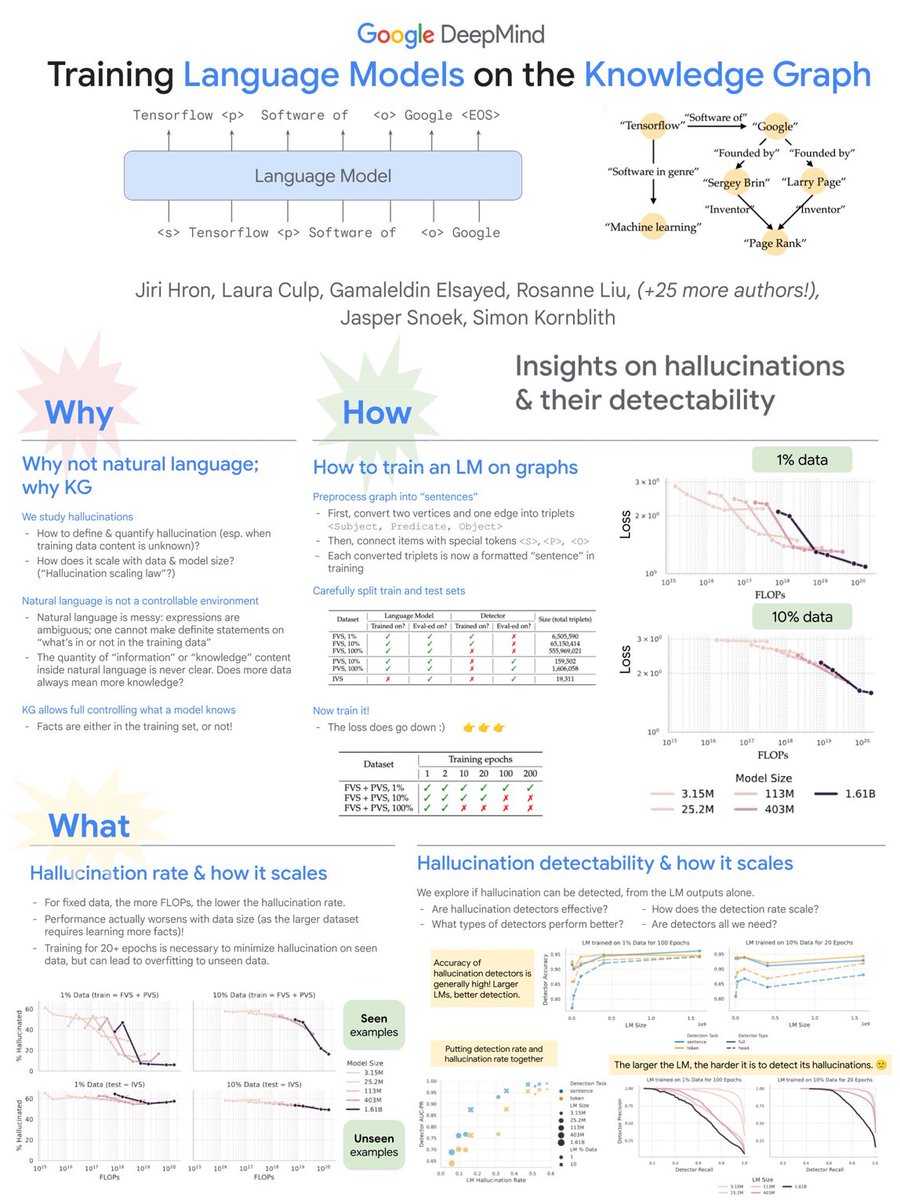
用知识图谱重塑语言模型:破解幻觉的终极武器!
这张图展示了Google DeepMind在知识图谱上训练语言模型的研究,特别关注幻觉(hallucinations)及其可检测性。
为什么使用知识图谱而不是自然语言?
1. 自然语言的复杂性:表达模糊,难以定义和量化幻觉。
2. 信息控制:知识图谱允许更好地控制模型所知道的事实,确保训练集和测试集的分离。
如何在图谱上训练语言模型?
1. 数据预处理:将图转换为“句子”,并用特殊标记连接。
2. 训练与测试:精细划分训练集和测试集,以减少过拟合。
幻觉率及其扩展
1. 数据大小与性能:随着数据集增大,性能可能下降,需要更多训练周期来减少已知数据上的幻觉。
2. 计算能力影响:更多的FLOPs会降低幻觉率。
幻觉检测及其扩展
1. 检测效果:较大的语言模型通常具有更好的检测准确率,但随着模型变大,检测难度增加。
2. 不同检测器的表现:需要探索不同类型的检测器来提高效果。
总结而言,这项研究强调了在知识图谱上训练模型的优点,并探讨了如何有效地识别和减少幻觉。