打破长文本处理瓶颈:RetrievalAttention让AI推理快如闪电
在处理大量数据时,长上下文的语言模型(LLM)非常出色,但因为其使用的注意力机制计算复杂度较高,所以效率上有些挑战。简单来说,就是当你给模型大量信息时,它可能需要花费较长时间来处理和理解这些信息,这会导致推理过程变慢,特别是在需要大量显存和处理时间的时候。
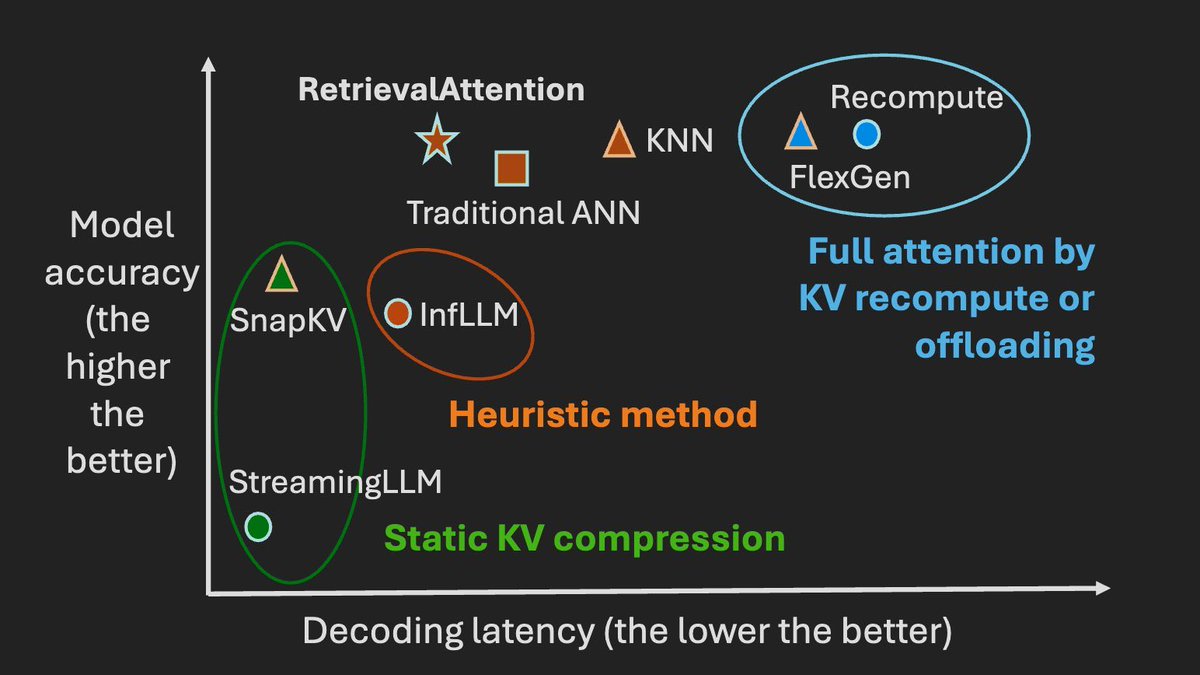
核心创新:RetrievalAttention 方法
这个方法的核心在于优化如何选择重要的信息进行处理。具体来说:
- 卸载大部分数据:把很多不那么重要的数据从GPU内存中移到CPU内存中,这样可以节省GPU的资源。
- 智能搜索算法:开发了一种新的搜索算法,能够更好地识别哪些信息对当前任务最重要,从而更精准地选择需要处理的数据。
- 协同策略:利用GPU和CPU共同工作,GPU负责最关键的数据,而CPU则动态查找其他相关数据。
实验结果
这个方法在多个测试中表现很好。在一些复杂的测试场景下,它能以较少的时间达到与全量处理相似的准确性。例如:
- 处理长度为128K的文本时,与传统方法相比,解码速度快了很多。
- 使用16GB的GPU内存就能在一台NVIDIA RTX4090显卡上高效运行大规模模型。
场景举例
想象一个客服机器人需要实时分析并回答用户问题。通常,这个机器人需要快速浏览数百万字节的数据(比如用户手册、常见问题解答等),以提供准确答案。通过使用RetrievalAttention方法,机器人可以更快地从海量信息中提取出最相关的数据进行分析和回答,从而提升响应速度和准确性。这就像是在图书馆找书时,能立刻找到所需书籍,而不是一本本翻找。