GraphRAG 的基础与精髓解析
如果你想深入理解 GraphRAG 并重新解读其论文、文档和代码,下面的内容将为你提供全方位的视角。我们不仅会逐步剖析其架构和原理,还会结合现实中的应用实例,帮助你更好地掌握这个强大的技术工具。以下内容基于微软和 LlamaIndex 等开创性工作,详细介绍 GraphRAG 对现有 RAGs 的提升方向。
GraphRAG 是什么?
GraphRAG 是一种结构化、分层的检索增强生成(RAG)方法,与传统的基于纯文本片段的语义搜索方法相比,具有更高的复杂性和智能性。GraphRAG 通过从原始文本中提取知识图谱、构建社区层次结构,并为这些社区生成摘要,来提升在处理基于 RAG 的任务时的性能。
GraphRAG 的优势
1. 全局问题解决能力:GraphRAG 能够更好地回答涉及整个数据集的“全局问题”,而传统的 RAG 方法在这方面表现不佳。
2. 社区摘要与映射-归约方法:通过生成社区摘要并利用映射-归约方法,GraphRAG 能保留全局数据上下文中的所有相关内容,提供更加全面、精准的回答。
GraphRAG 的组成部分
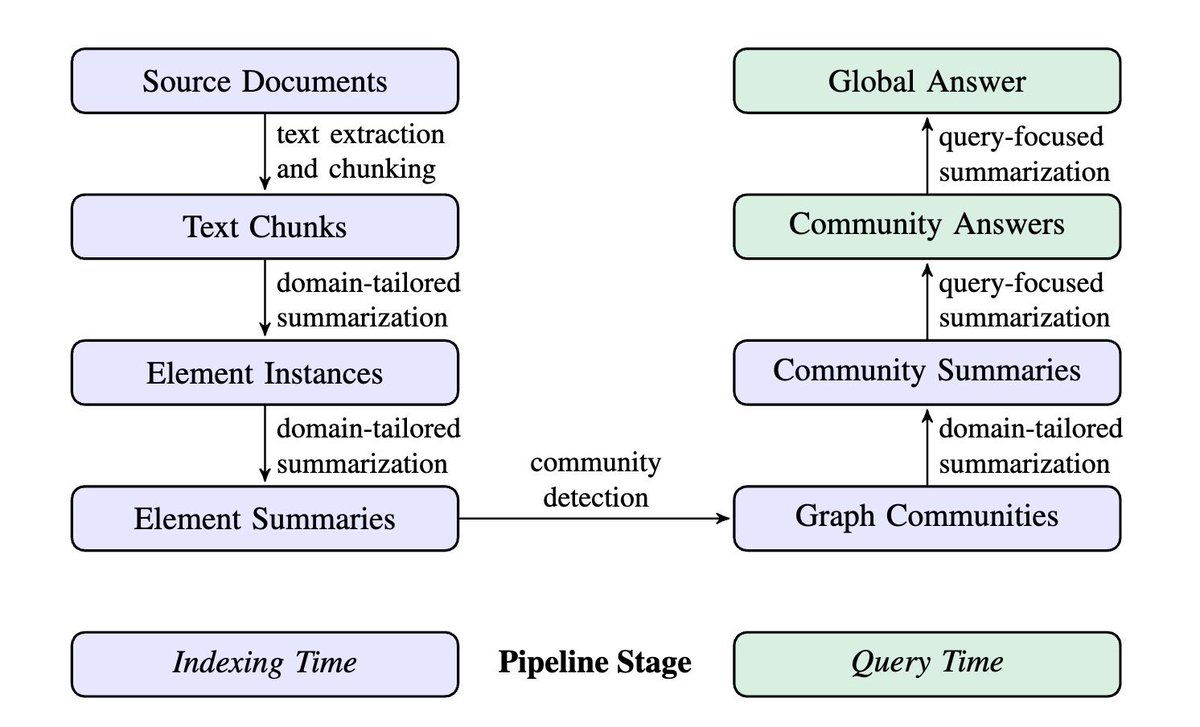
GraphRAG 的工作流程分为两个主要部分:索引(Indexing)和查询(Query),每个部分又包含多个具体流程。下面我们详细解析每个流程。
1. 索引(Indexing)
这个阶段的核心是从文本文档中提取并构建知识图谱。
1.1 从文本文档到文本块(Text Chunks)
处理源文档时,将输入文本分割成合适大小的文本块。例如,使用较小的 600 标记文本块能够捕获更多实体引用,而较大的 2400 标记文本块则可能遗漏部分信息。
1.2 从文本块到元素实例(Element Instances)
使用大语言模型(LLM)从文本中抽取实体、关系和声明描述,将其转化为图元素描述。虽然可能会出现实体引用格式不一致的情况,但 LLM 具备识别变体背后共通实体的能力。
1.3 从元素实例到图元素摘要(Element Summaries)
LLM 再次汇总这些实例,将它们转化为描述性文本。我们旨在提供丰富的描述性文本,适合 LLM 的能力和全局查询摘要需求。
1.4 从图元素摘要到图社区(Graph Communities)
采用 Leiden 算法将加权无向图划分为节点社区,恢复图的层次化社区结构。这一过程生成了一个便于全局摘要的社区层次结构。
2. 查询(Query)
在这个阶段,利用图节点的社区结构形成多层次的主题概述,以回应查询需求。
2.1 从图社区到社区摘要(Community Summaries)
为每个社区生成摘要,有助于用户理解数据集的整体架构和语义。这些摘要会依据节点的重要性进行优先级排序,并添加到语言模型的上下文中,直至满载。
2.2 从社区摘要到社区答案,再到全局答案(Community Answers → Global Answer)
收到用户查询后,先前生成的社区概要经过多阶段处理,形成最终答案。这一过程中,会综合不同层级的社区概要,并提示最适合回答问题的层级。
GraphRAG 在现实中的应用
为了理解 GraphRAG 在现实中的应用,我们可以从以下实例中获得一些启发:
实例1:学术研究
在学术研究领域,用 GraphRAG 可以从大量的文献中提取和总结相关领域的研究进展。例如,一位研究者想了解“2022年人工智能领域的主要研究方向”,GraphRAG 可以构建一个知识图谱,将所有的研究方向标记,并生成对应的社区摘要,为研究者提供全面的综述。
实例2:企业数据分析
在企业数据分析中,GraphRAG 可以帮助企业从庞大的数据集(如客户反馈、销售记录等)中提取有价值的信息。例如,一个企业想要理解客户的主要反馈问题,GraphRAG 可以从客户反馈中提取关键信息,构建反馈社区,并生成总结报告,帮助企业决策。
GraphRAG 与现有 RAGs 的提升方向
通过上述分析可以看出,GraphRAG 在应对全局性问题和生成全面摘要上具有显著优势。这种方法尤其适用于需要处理大量文本数据并生成高度抽象的总结报告的应用场景。凭借其复杂的社区结构和智能的摘要生成方法,GraphRAG 赋予研究者和企业更强大的信息处理能力,有望在未来成为 RAG 方向的终极形态。
通过这些深入解读和应用实例,相信你对 GraphRAG 的理解将更加全面和透彻。