
got llama running locally on steamdeck 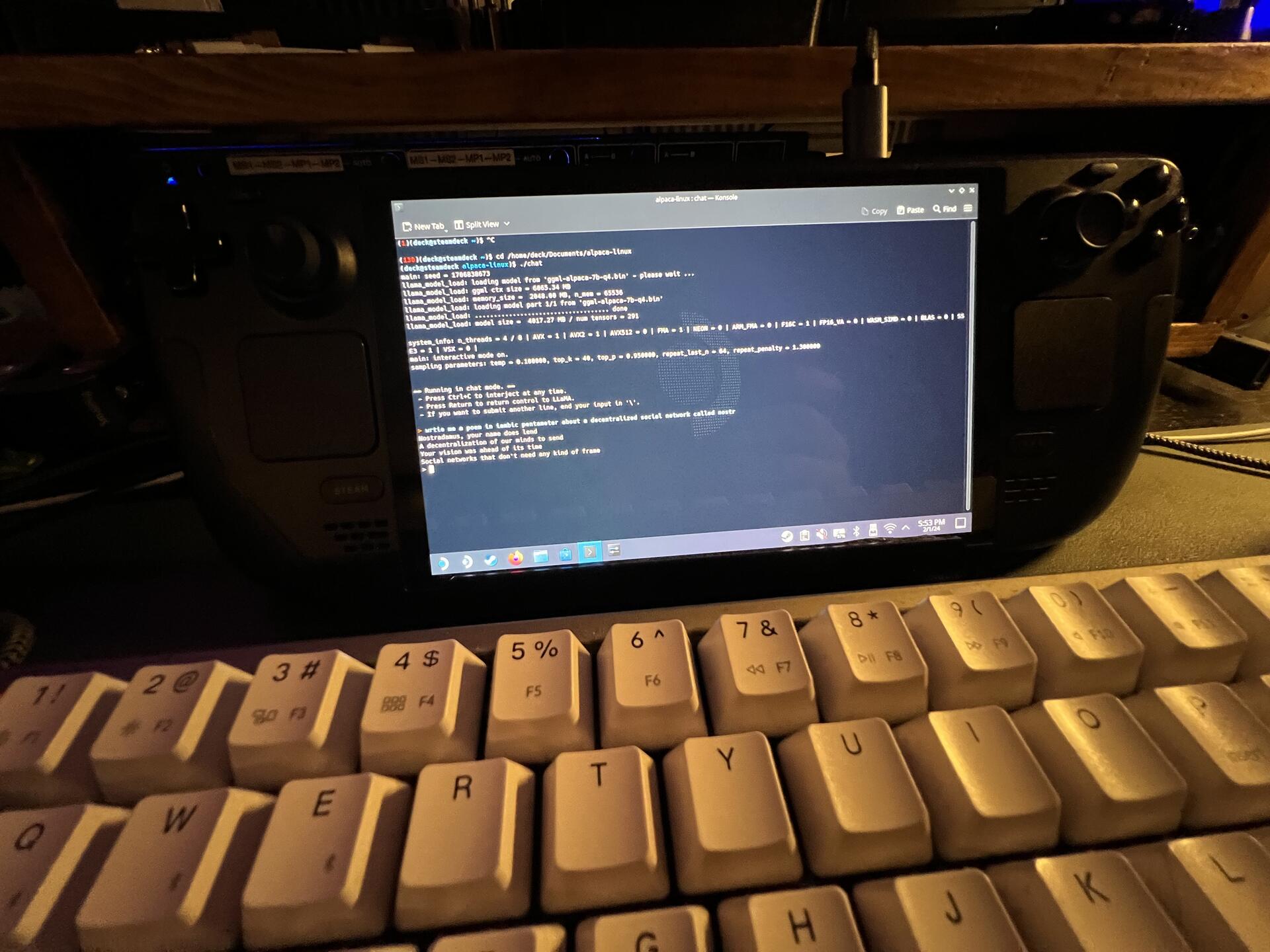
Discussion

Amazing! 7b models run good?
it’s fast, but no retained context between prompts, running nous Hermes 13b on my Mac through local.ai and thats actually passable in a survival situation.
I have a fairly beefy P16 thinkpad and I run 34b models via ollama.ai decently
Pretty amazing tech. If only more people stopped using centralized chatgpt and started using open source
Thanks for pointing me toward ollama i have the 64gb to run a larger model on desktop, gonna try out this weekend. Nice model browser they have.
also been playing with mlc chat on my phone… haven’t pushed that past 7b either.