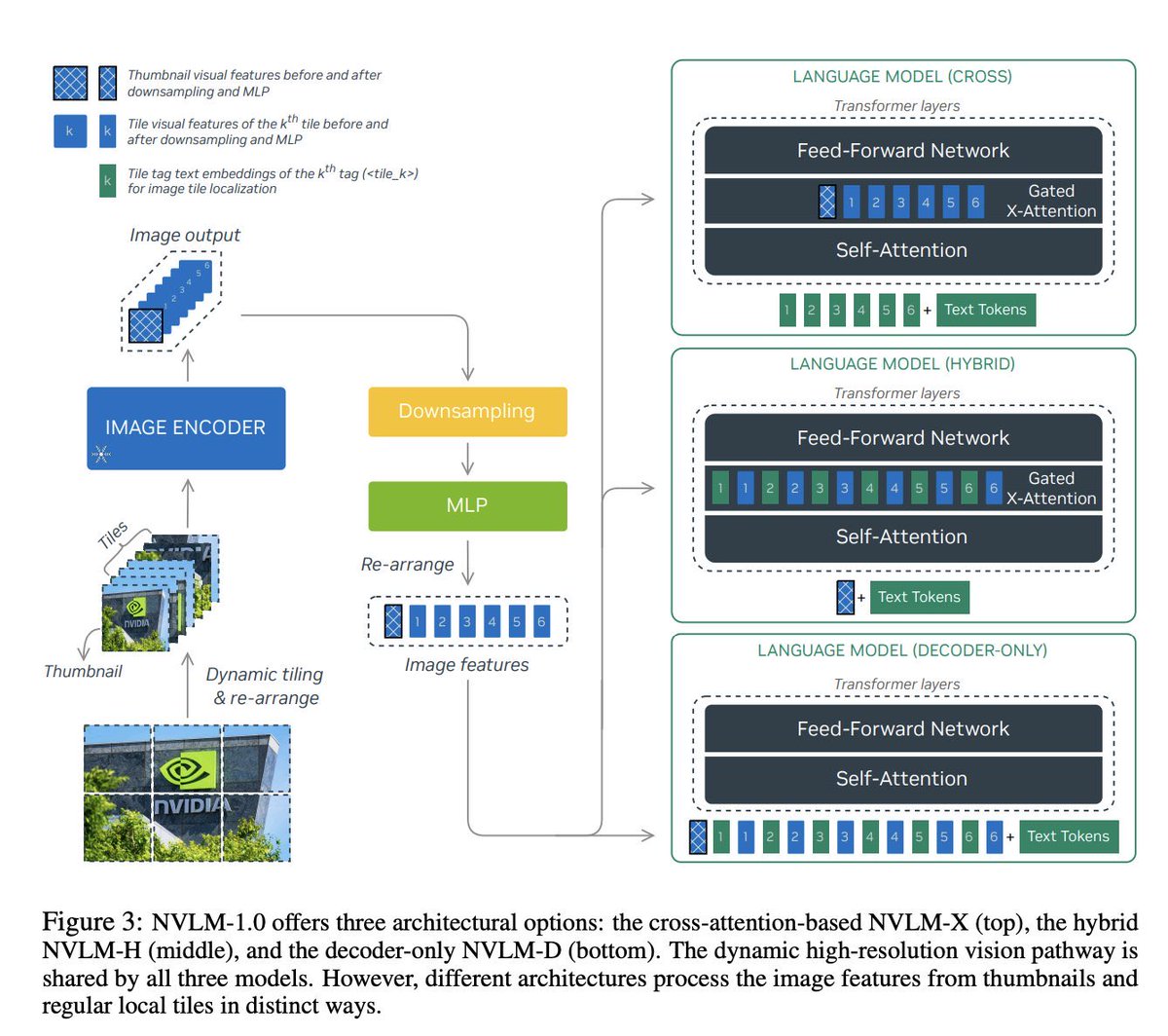
NVLM-1.0: 三大架构选项揭秘 - 跨模态视觉语言模型的未来
1. 图像编码和特征提取:
- 图像首先通过一个图像编码器进行处理,生成缩略图和动态切片(Tiles)。
- 这些切片经过下采样和多层感知器(MLP)处理后,重新排列为一组图像特征。
2. 多种语言模型选项:
- NVLM-X(Cross-Attention Based):
- 采用交叉注意力机制,将图像特征与文本标记嵌入结合。
- 通过自注意力机制和门控交叉注意力机制处理数据。
- NVLM-H(Hybrid):
- 混合模式结合了自注意力机制和交叉注意力机制。
- 图像特征和文本标记嵌入在相同网络层中进行整合。
- NVLM-D(Decoder-Only):
- 仅使用解码器,通过自注意力机制处理数据。
- 图像特征与文本标记嵌入一同输入到模型中。
3. 独特的处理方式:
- 虽然这三种模型共享动态高分辨率视觉路径,但它们在处理缩略图和局部切片时有着独特的方法。
- 这种差异化处理方法使得每种架构在不同应用场景下具有各自的优势。
4. 创新点与优势:
- NVLM-1.0不仅在多模态数据处理上表现卓越,还通过灵活的架构设计满足了不同任务需求。
- 多样化的架构选择使得该模型在应用场景上更具适应性,从而提升了整体性能和用户体验。
综上所述,NVLM-1.0通过其三种创新性架构,为跨模态视觉语言任务提供了强大的解决方案。这不仅增强了模型对复杂任务的处理能力,还为未来的研究和应用奠定了坚实基础。