SCoRe:AI自我纠错的革命性突破
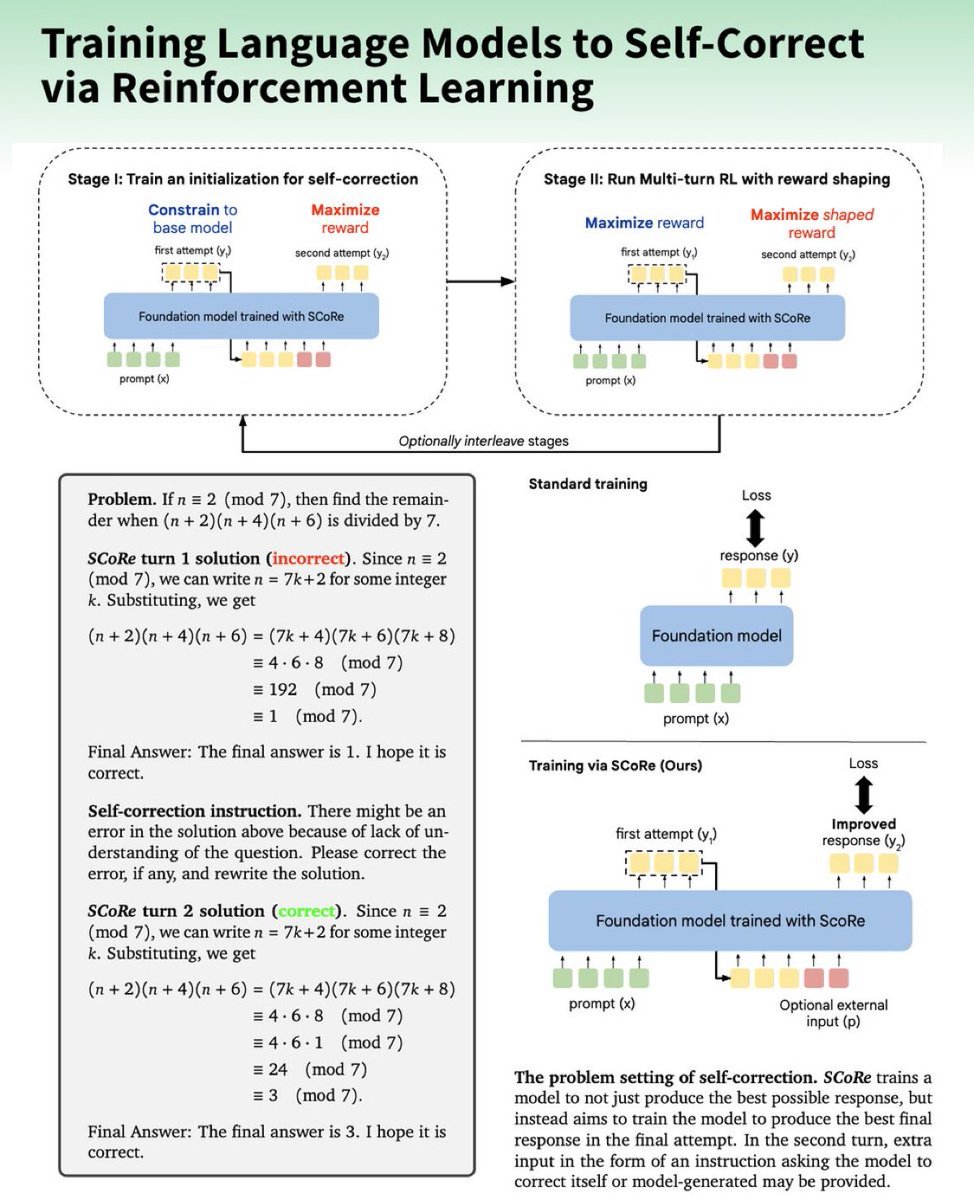
Google DeepMind开发了一种名为SCoRe的多轮思维链在线强化学习方法,旨在通过完全自生成数据来提升自我纠错能力。SCoRe在MATH和HumanEval两个基准上分别实现了15.6%和9.1%的性能提升。这项技术展示了在没有外部反馈的情况下,模型如何通过自我生成的数据进行训练,从而在推理问题上生成响应并纠正错误。
实施步骤
1. 选择预训练的大语言模型(LLM):如Gemini 1.0或1.5 Flash,作为自我纠错增强的基础模型,并收集初始训练任务集。
2. 第一阶段(Stage 1):使用强化学习(REINFORCE)训练模型进行高奖励修订,但限制首次尝试不发生改变,以KL散度实现首次和第二次尝试分布的解耦。
3. 第二阶段(Stage 2):去除首次尝试的改变限制,训练两次尝试以优化奖励,包括一个设计好的奖励,以最大化自我纠错(对从首次到第二次尝试正确性的转换给予更高奖励)。
关键见解
- 监督微调(SFT)不足以有效培养自我纠错行为,因为它只适用于离线模型生成的纠正轨迹。
- 在第一阶段使用RL作为SFT可能只会让模型擅长于纠正或推理,而非两者兼备。
- 采用REINFORCE算法贯穿整个过程,且政策内采样对于多轮自我纠错的成功至关重要。
- 数学和HumanEval性能显著提升:分别提高了15.6%和9.1%。
- 单轮训练虽能提升初始表现,但对后续回合的自我纠错无助。
- 用STaR替代REINFORCE导致性能下降,将SCoRe与推理时间缩放结合可提高10.5%。
这项研究表明,通过强化学习实现AI系统的自我优化潜力巨大,将来这种技术可能会在更复杂的推理任务中发挥关键作用。
阅读完整研究请访问:https://t.co/yc5rUkptrk。