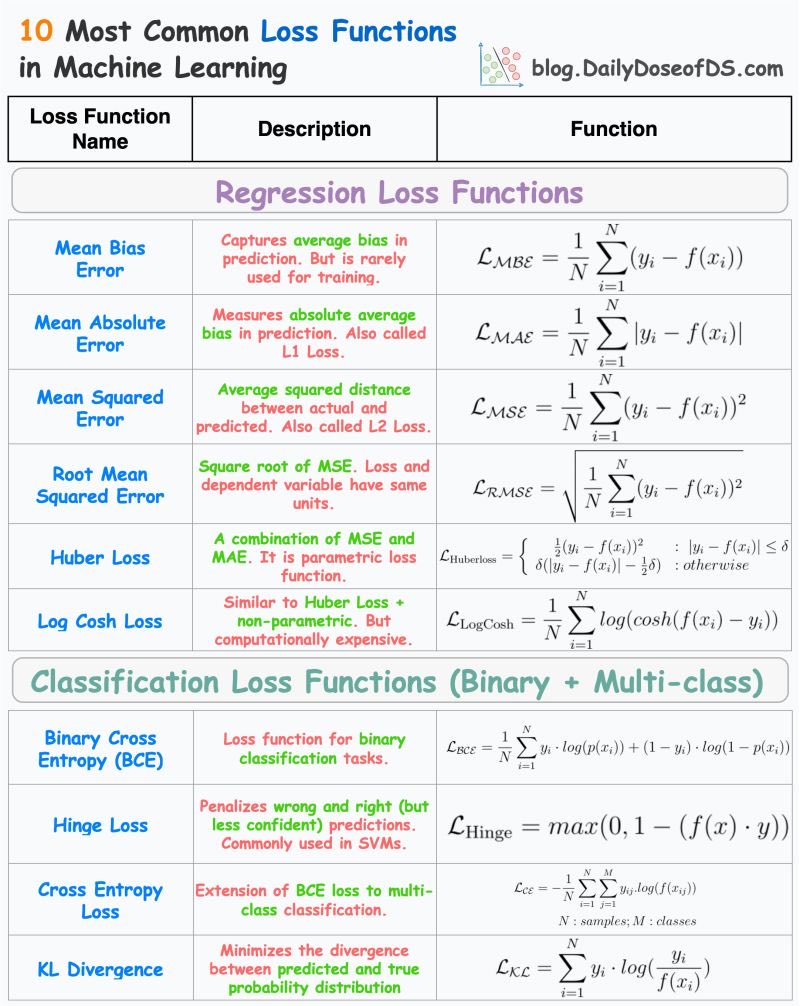
机器学习中的十大损失函数,轻松搞懂模型优化!
这张图表详细介绍了机器学习中常用的十种损失函数,它们是优化模型性能的关键工具。让我们用大白话来解读这些函数。
回归损失函数
1. 平均偏差误差 (Mean Bias Error):
- 主要用于捕捉预测中的平均偏差,但不常用于训练。
2. 平均绝对误差 (Mean Absolute Error, MAE):
- 测量预测与实际值之间的平均绝对差距,也称为L1损失。
3. 均方误差 (Mean Squared Error, MSE):
- 计算预测与实际值之间的平方距离,是L2损失的一种。
4. 均方根误差 (Root Mean Squared Error, RMSE):
- MSE的平方根,确保损失和变量单位一致。
5. Huber损失 (Huber Loss):
- 结合了MSE和MAE的优点,是一种参数化的损失函数。
6. Log Cosh损失:
- 类似于Huber Loss,但非参数化,计算成本较高。
分类损失函数
1. 二元交叉熵 (Binary Cross Entropy, BCE):
- 用于二元分类任务,衡量预测概率与实际标签之间的差异。
2. Hinge损失:
- 用于支持向量机(SVM),惩罚错误和不够自信的预测。
3. 交叉熵损失 (Cross Entropy Loss):
- BCE的扩展,用于多类别分类任务。
4. KL散度 (KL Divergence):
- 最小化预测分布与真实概率分布之间的差异。
这些损失函数是机器学习模型训练中的基础工具,它们帮助我们衡量模型性能并进行优化。通过选择合适的损失函数,可以更好地提升模型在不同任务中的表现。