揭开AI处理大数据背后的神秘面纱:从分块到生成报告,一步步带你走进未来!
理解AI在结构化与非结构化数据中的应用
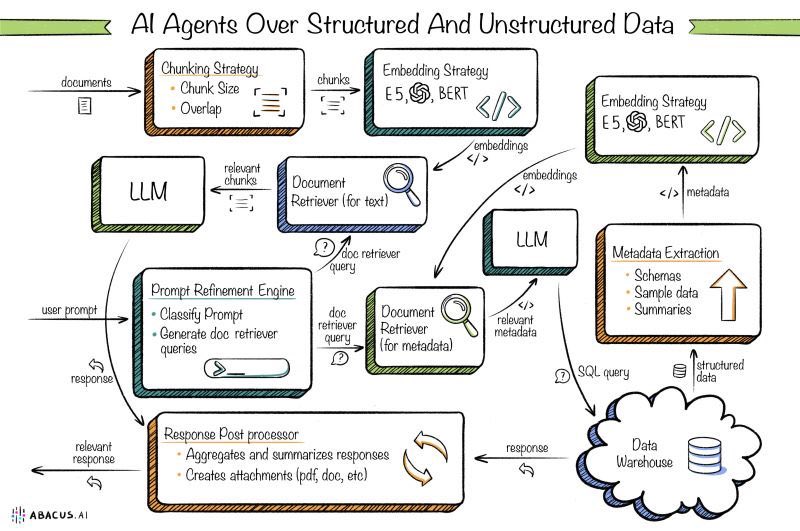
这张图展示了AI如何处理结构化和非结构化数据,以便生成有用的响应。让我们一步步来解读每个环节,并举个具体的场景来帮助理解。
1. Chunking Strategy(分块策略)
图中的文件会被分成多个小块,这些小块可以是固定大小或有重叠的部分。这样做的目的是便于后续处理和分析。
场景:想象你有一本电子书,你把它分成每个章节来处理,这样更容易找到特定内容。
2. Embedding Strategy(嵌入策略)
每个小块都会被转换成向量表示(embeddings),这种转换可以使用例如E5或BERT等模型。这些向量表示让计算机更容易理解和处理文本。
场景:将电子书的每一章转换成数字形式,方便计算机进行分析和搜索。
3. Document Retriever(文档检索器)
LLM(大型语言模型)根据用户的查询从已分块并嵌入的小块中检索相关内容。
场景:当你搜索电子书中的某个主题时,系统会找到最相关的章节。
4. Prompt Refinement Engine(提示优化引擎)
这个模块会对用户的输入进行分类,并生成适合的检索查询,以确保找到最相关的信息。
场景:你输入一个问题,系统会先理解你的问题类型,然后生成合适的查询去搜索答案。
5. Document Retriever for Metadata(元数据文档检索器)
这个模块专门用来检索元数据,比如文件结构、示例数据和摘要等。
场景:如果你需要了解电子书的章节结构或摘要,系统会通过这个模块快速找到相关信息。
6. Metadata Extraction(元数据提取)
从结构化数据中提取出有用的信息,包括模式、示例数据和摘要。这些信息可以进一步用于优化查询结果。
场景:提取电子书的目录和摘要信息,方便用户快速浏览内容。
7. Response Post Processor(响应后处理器)
最后,系统会对生成的响应进行汇总和总结,还可以创建附件如PDF或Word文档供下载。
场景:当你提出一个复杂问题时,系统不仅回答你的问题,还会生成一份详细报告供你下载。
场景应用
假设你是一名研究人员,需要在一个大型数据库中查找与某个特定课题相关的所有文献。通过上述流程:
1. 系统先将所有文献分块并嵌入向量表示;
2. 当你输入查询时,提示优化引擎会生成合适的检索查询;
3. 文档检索器从数据库中找到相关文献;
4. 元数据提取模块提供文献的摘要和结构信息;
5. 最后,响应后处理器生成一个包含所有相关信息的报告供你参考。
通过以上解释,相信大家对AI如何处理结构化与非结构化数据有了更清晰的认识。