I don't understand Blossom. How do you find a piece of content in it if you only have a hash? Or is that not a goal?
Discussion

it is
you have the hash and a pubkey, you basically use the same technique we use with NIP-65 to find events
e.g.
* you start with a URL that includes the hash
* you get an error because the server banned the photo of nostr:npub1gcxzte5zlkncx26j68ez60fzkvtkm9e0vrwdcvsjakxf9mu9qewqlfnj5z and Dilma
* you look up who uploaded the file (either a 1063 or the author of the event where you saw the URL)
* you fetch their NIP-65-equivalent list of blossom-servers
* you HEAD or GET the file from those
that's the most direct/happy path after censorship, but you could always publish a request (ala dvms) saying "willing to pay this much for a file with this hash"
That all sounds very shitty, but I think because of that it might work. I can't think of anything else better.
nostr:npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s have you seen it? Is this just like Daniel's blobstr?

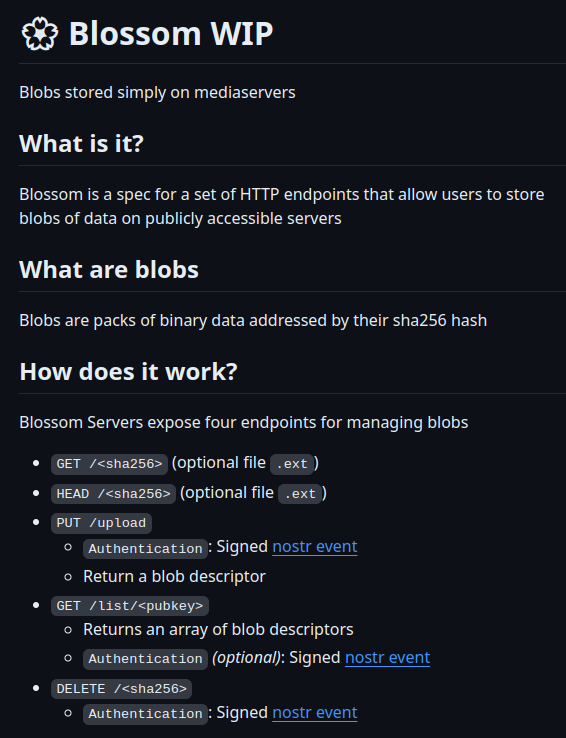
I haven’t looked at blossom that much, from what I understand nostr:npub13v47pg9dxjq96an8jfev9znhm0k7ntwtlh9y335paj9kyjsjpznqzzl3l8 just spec’d a way to do content addressable file lookups over http for redundancy, but doesn’t spec a way to distribute files to these blobstr servers.
One thing that just came to mind is a blobstr service is one that monitors these hashes and automatically mirrors them from your notes. You wouldn’t need any of the blossom machinery and would be more automated. I guess the blossom list thing would still be useful if you want to advertise which blobstr relays you use.
The only additional thing blobstr needs is authenticated uploads for uploading files. This could just be an api key and doesn’t need to involve nostr at all.
Maybe this is the same or very similar to blossom?
Seems to be pretty much the same.

What about NIP-97? This way, copies of the file can be distributed across multiple relays that choose to accept NIP-97 events, and users don't need to think about what servers to send the file to.

Remember when people were crying out against NIP-94? What a time...

I remember
the key difference is that this approach is backwards compatible and the happy-path is exactly the same clients do right now 😅
Yep, but the happy path doesn't solve anything. It is still centralized media database. Nobody wins if devs stay in the happy path. It's like saying custodial bitcoin is an innovation vs fiat systems. No, it's not. It's just an illusion.

😅 Maybe… it's time to send base64 image event.
Some clients are putting `data:image/jpeg;base64, ` uris right into the .content of kind1 because we don't really have a better solution right now.
this is a great way to disincentivize people from running relays. thanks client devs!
If relay operators are surprised by base64 images, I got news. There are worse things being transfered in broad daylight through regular events.
I just open source a relay who run at cloudflare with workers. It was designed to help people run their relays with the cf's free plan.
With this relay, people can hold their events. and It has one GB for people to hold their base64 image event.
Maybe there also should be many relays are welcome people to send image event with payment.

nah, the happy path being optimized and working-by-default is fundamental
that's what nostr gets right, the happy path works just as well as the centralized stuff, but if you get censored or infra just disappears you have a very very very easy path to recover which is so simple as to be basically invisible to users
"Works as well" because it is centralized. Blossom is very similar to NIP96 in that regard. Just different api calls. Since nostr:npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6 raised this initial thread, I don't think it is "very very very easy" to figure it out.

this flow seems overcomplicated
wouldn't it work better like this:
* you have a list of blossom nodes that you know about, and send out a query for hash
* one or more returns the hash
there is no participation of pubkeys in the protocol as i understand it
theoretically, a cluster of blossom nodes can propagate queries and cache the results for future queries
blossom makes no assumptions about blossom node caching strategies or how much or which data they might delete, this is part of the point, i think
Because this is super centralizing. Everybody just uses the same small set of Blossom servers?
Another thing that could be added is another layer of indirection. Instead of searching on "people's lists of blossom servers" to have a category list of servers of some kind. Like I publish a link of nostr:npub1gcxzte5zlkncx26j68ez60fzkvtkm9e0vrwdcvsjakxf9mu9qewqlfnj5z/Dilma picture, but I'm not saying I have hosted that picture on my blossom servers because I don't care very much about it.
I do know however there are a bunch of servers known for storing that kind of anti-leftist whistleblower-content that exposes the true origins of Nostr contributors and I somehow link to that in the URL?
I don't know, it sounds very shitty.
I like that the URLs allow for file extensions. That will save us a lot of headache.