
GM ☕️
That programming software consumes so quickly. Claude code?
GM ☕️
That programming software consumes so quickly. Claude code?
Shakespeare. I told the team but I’m not sure they believe me there’s an issue. If you get it stuck in a loop it’ll eat through $20 in 2 minutes … so you really have to monitor it closely.
Something is wrong with the way it passes or accumulates context. I tried explaining it.
Shakespeare is cool but it always ran up a bill for me too. I've used it to get some base code before then switch to cursor or Claude.
Yeah it’s not configured to pass context correctly. I wish nostr:npub1q3sle0kvfsehgsuexttt3ugjd8xdklxfwwkh559wxckmzddywnws6cd26p would investigate it more closely.
It's not correctness... if it's really so cheap on other software, they're either not doing as much, have a custom solution, or they're footing the bill. Compare Shakespeare's price to Goose.
Nah, there is clearly a bug in how it handles context. It doubles it under certain conditions and that shouldn’t be happening.
Karnage did you see this? If you use Claude through openrouter then at a certain point of context they start charging double. The solution is to reset the chat or use Claude through Shakespeare AI because we prevent that (but we cant control it through other providers)
Even resetting there’s still a bug. I reset every prompt almost. Any time it goes over $5 I’ll reset
Oh wow. What provider and model are you using?
I think there’s a problem where if it doesn’t fix an issue, it takes the entire context of all previous files and adds that to the context window, essentially doubling tokens every time until the next unresolved “oops, I made a mistake”
Here it’s going from 40k tokens to 268k tokens in one second.
Why on earth would it need to do that?

I'm not reproducing that. My guess is it read a giant file and we didn't prevent it from doing so. I'm seeing the mkstack context be at about 16k tokens.
Nothing is hidden from you. Look at your message history.
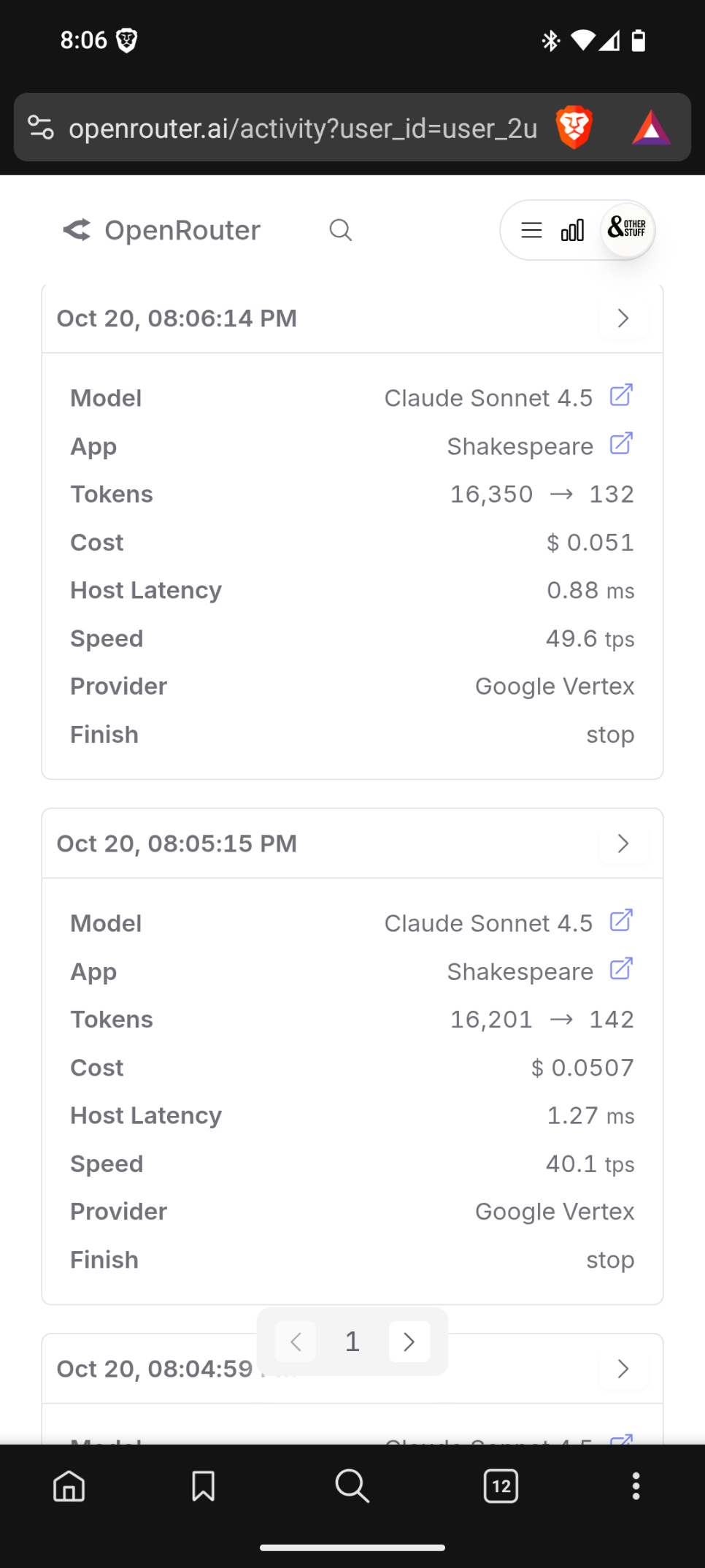
Did you see the screenshot where it went from 40k to 268k? Does that sound like normal behavior?
Absolutely if you had a file that's 228k tokens long and it used the "view file" tool.
Why would you have a file that big? Does Shakespeare not create smaller sub files and only check for the ones it needs to? This is probably the issue …
It shouldn't. What project was this happening in?
If you’re passing it instructions, it should probably also be to keep things in components and not build giant files
In this case, the developer's application probably handled the context incorrectly. If you can choose a model, choose Haiku 4.5, which is one-third the price of Sonnet. Haiku is very fast. I use Claude Code in the terminal. The way I manage context is to open a new terminal when there is only about 10% of the conversation left. Copy the unfinished task conversation to the new conversation. It is accurate and efficient. I don't use Claude Code's automatic conversation compression function. Automatic conversation compression always causes many problems, the context connection is also very poor, and it is very slow.
nostr:npub1q3sle0kvfsehgsuexttt3ugjd8xdklxfwwkh559wxckmzddywnws6cd26p found that it was trying to read console errors and ballooning costs but I’ll tag him here just in case there’s some useful info.
Claude code or stick your dick in a blender




