

Venice.ai got it right.
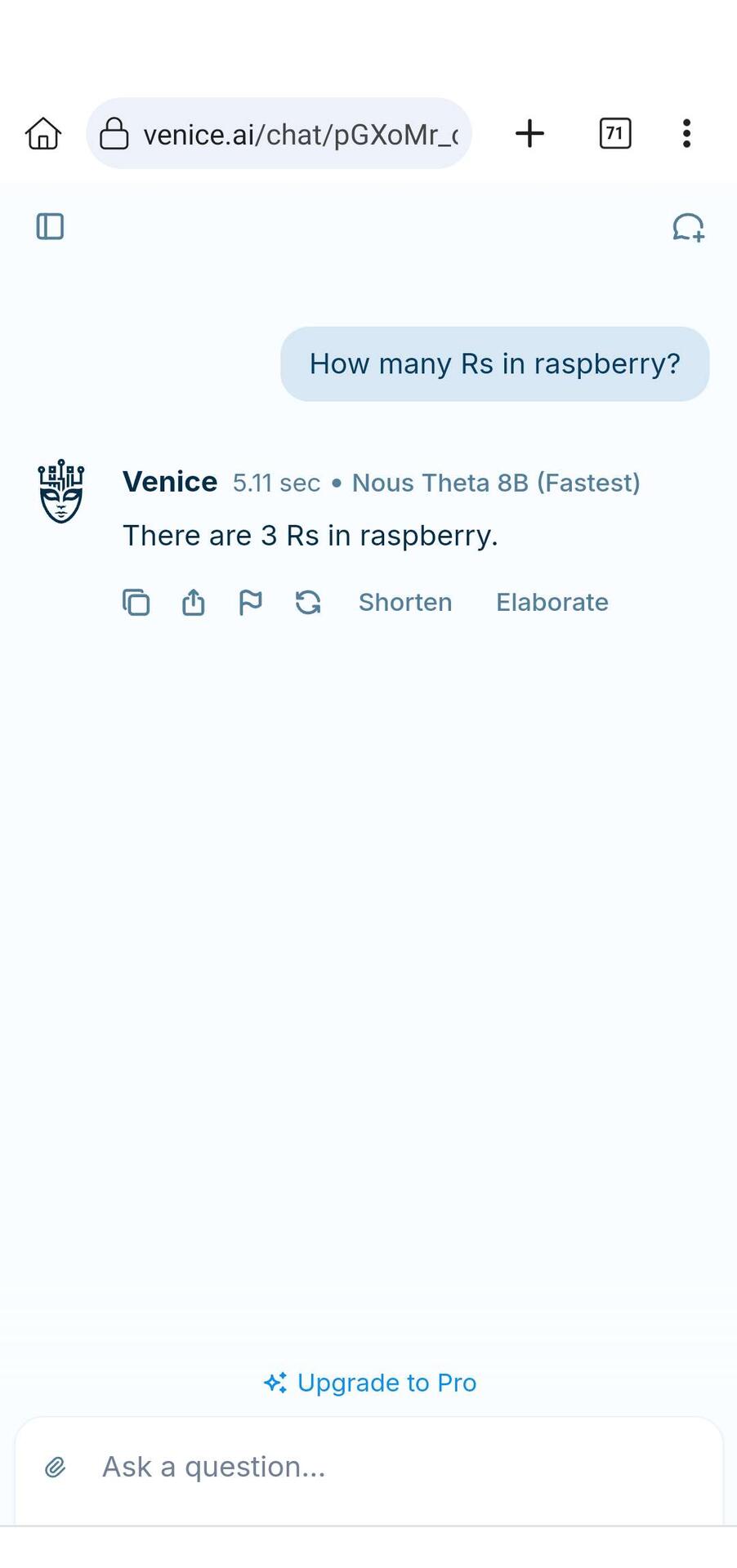
I asked it a second time and it got it wrong 🙃
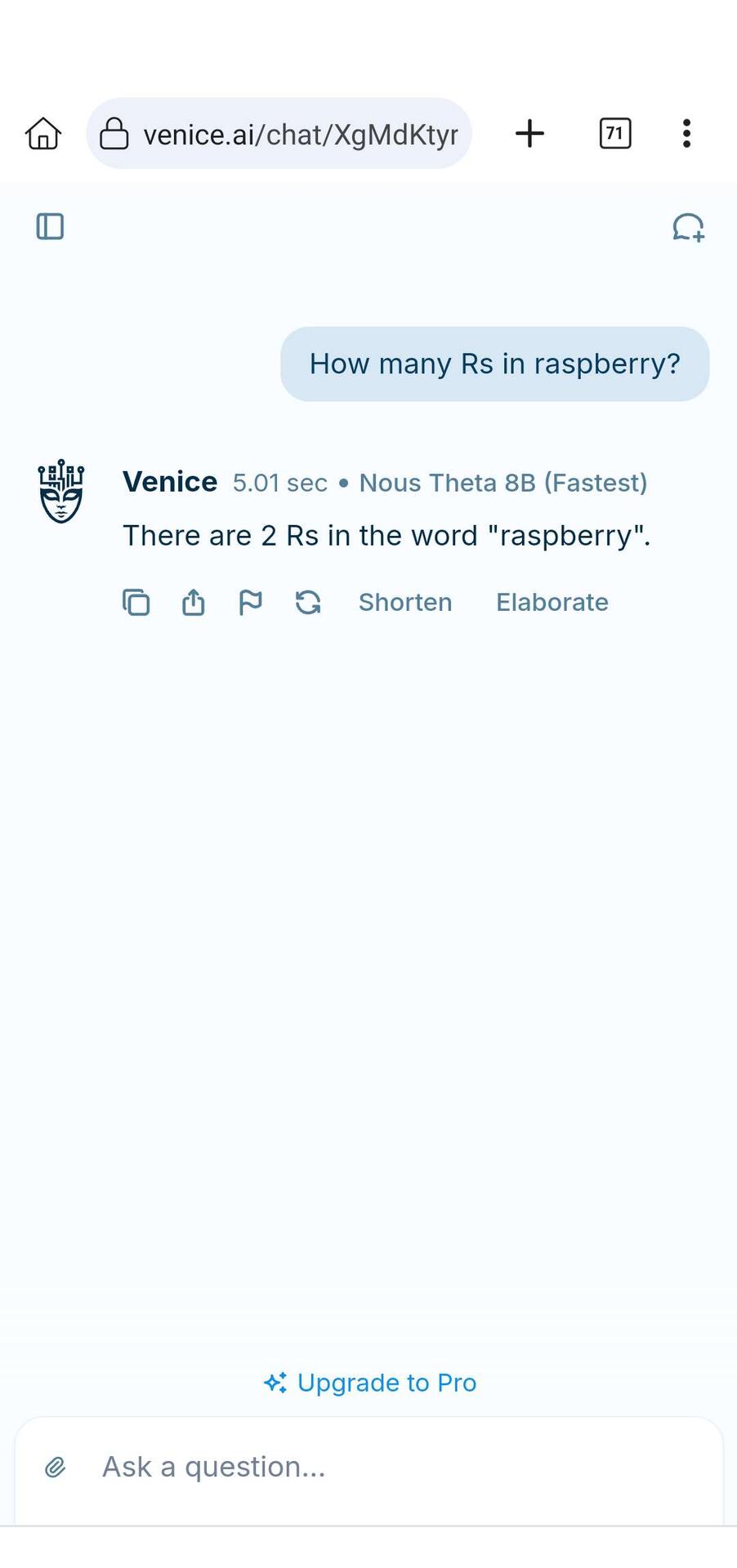
Venice.ai got it right.
I asked it a second time and it got it wrong 🙃
The strawberry test is quite iconic. Many models are secretly "hard-coded" to avoid failing it so they don't appear flawed, but it highlights some fundamental weaknesses in LLM architecture and core limitations. Playing chess also reveals these flaws.
