揭开AI智能问答的秘密:如何通过嵌入模型实现精准回答!
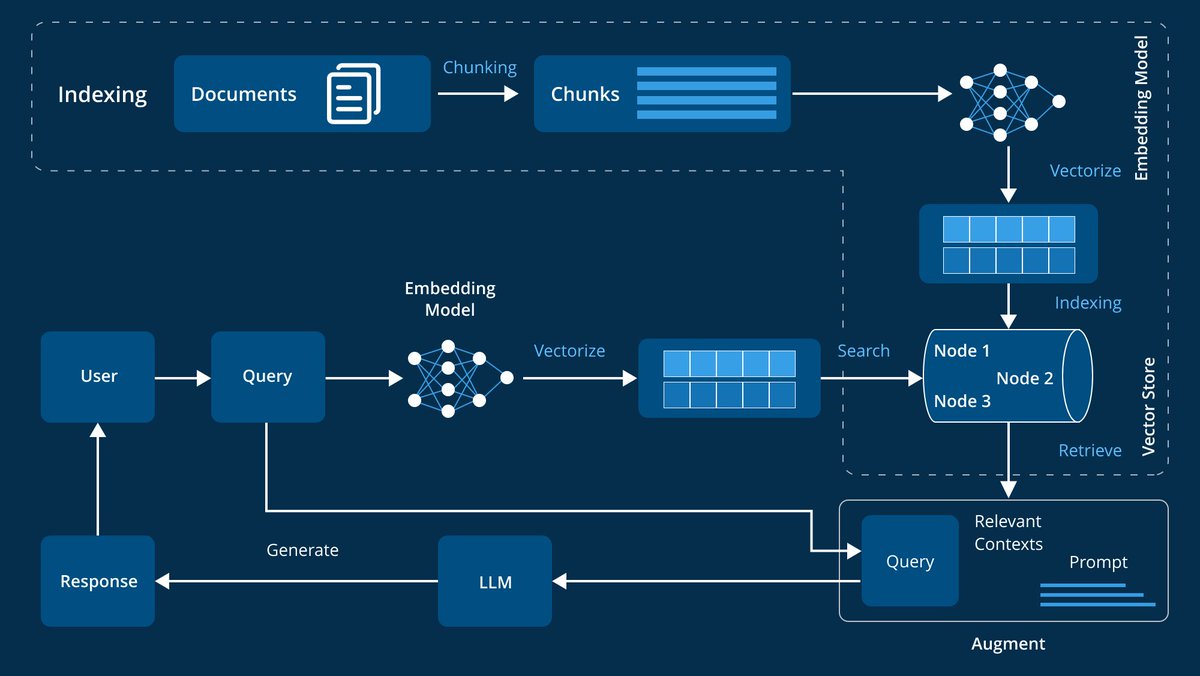
这张图展示了一个基于嵌入模型(Embedding Model)的智能问答系统的工作流程。我们将通过一个具体的例子来详细解析各个步骤。
1. 文档索引(Indexing)
- 文档(Documents):首先,系统需要处理大量的文档。这些文档可以是书籍、文章、研究报告等。
- 分块处理(Chunking):将文档分成多个较小的块(Chunks),便于后续处理。
2. 嵌入模型(Embedding Model)
- 向量化(Vectorize):使用嵌入模型将这些块转换为高维向量。这些向量捕捉了文本的语义信息。
- 索引存储(Indexing & Vector Store):将这些向量存储在一个矢量存储库中,形成节点(Node 1, Node 2, Node 3)以便快速检索。
3. 用户查询与检索
- 用户查询(Query):用户输入一个问题,比如“比特币的价格趋势如何?”。
- 嵌入模型向量化(Vectorize with Embedding Model):系统将用户的查询也转换为高维向量。
- 搜索与检索(Search & Retrieve):在矢量存储库中搜索与查询最相关的上下文信息。
4. 增强查询与生成响应
- 增强查询(Augment Query):将检索到的相关上下文信息整合进原始查询,形成一个更具上下文关联性的提示(Prompt)。
- 生成响应(Generate Response with LLM):利用大型语言模型(LLM),根据增强后的提示生成最终响应。
举个例子
假设你是一位投资者,想要了解最新的比特币市场动态,你在系统中输入了以下问题:“比特币目前市场表现如何?”
1. 系统会先将你的问题转化为高维向量。
2. 接着,在矢量存储库中搜索与“比特币市场表现”相关的内容,比如最近的市场分析报告、价格走势数据等。
3. 然后,将这些相关内容作为上下文,整合进你的原始问题中。
4. 最后,利用大型语言模型生成一个详尽且有价值的回答,比如:“根据最新的数据,比特币在过去一周内上涨了5%,主要受到机构投资者增持和市场情绪回暖的影响。”
这个智能问答系统通过嵌入模型和矢量存储技术,不仅能够理解用户的问题,还能从大量的数据中快速提取最相关的信息,再结合大型语言模型生成准确且有深度的回答。这种技术不仅提升了用户体验,还大大提高了信息获取和处理的效率,真正实现了智能化的信息服务。