
Might be faster to scan over the utxo set instead
2.4 million distinct mainnet taproot outputs with amounts greater than 500K sats (at least once), in the last year.
Proof that I own one of them **, and a key image to prevent reuse, size 2.9kB and verified in 64ms!
The keyset takes up 155MB, but half that if binary.
Scanning raw blocks using RCasatta's tool:
https://github.com/RCasatta/blocks_iterator
... takes minutes but not too bad. Creating the proof is slow, I estimate 5-8 minutes on my laptop. Can def be improved.
Work continues at https://github.com/AdamISZ/aut-ct
** (Ok, i cheated and inserted a key of my own into the list, instead of creating a new utxo. Sue me!)
Discussion
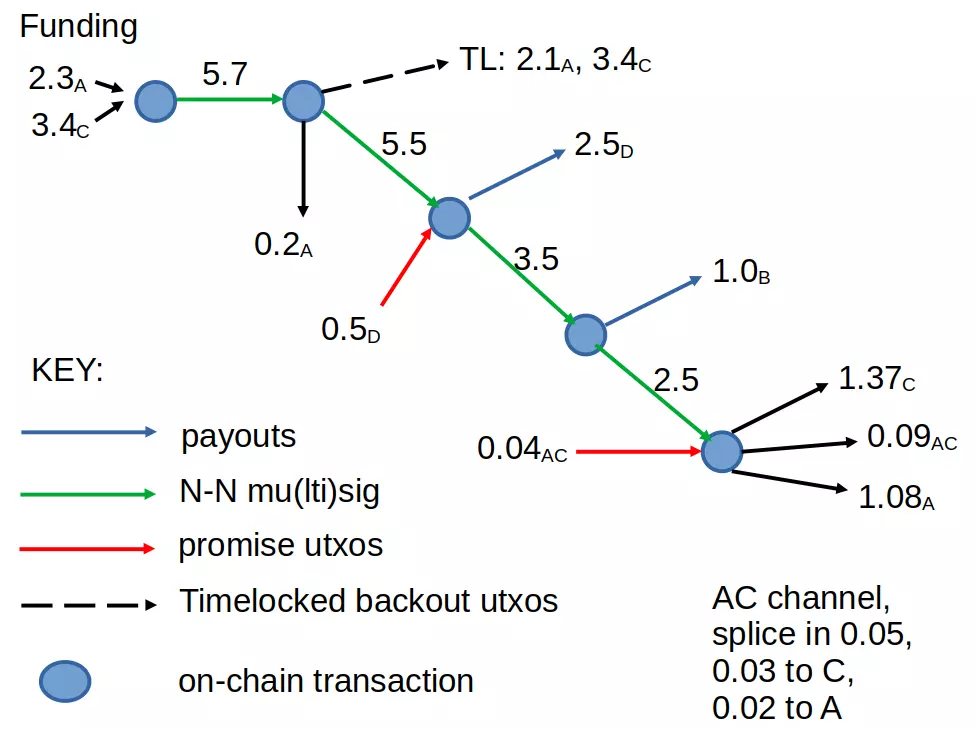
Yeah, though there are different options, that is for sure one, and i should prob focus more on it. Buy I'm less worried about scanning in the keys from a filter, more about making sure that constructing proofs is not impractically slow, which is mostly about constructing the curve tree itsel, intelligently.