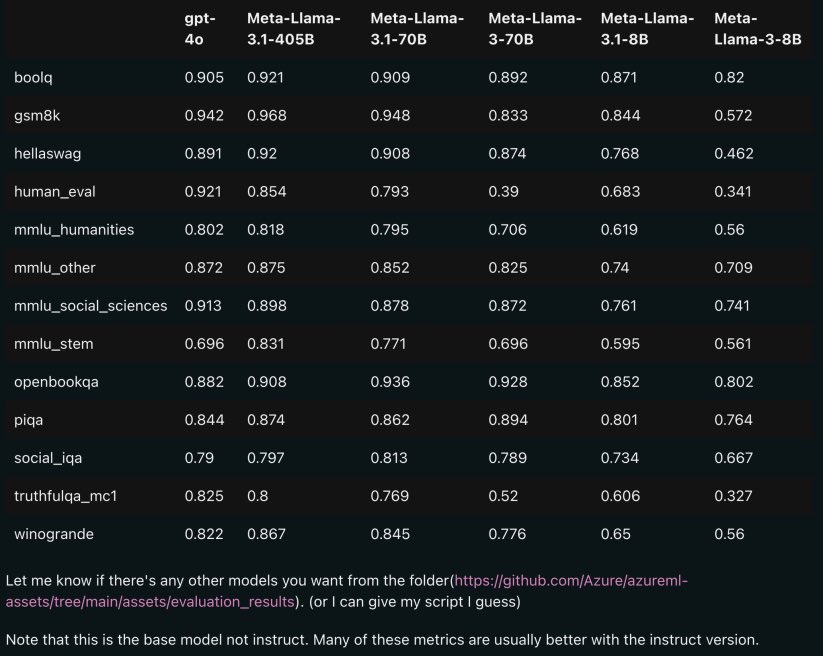
这个图显示了多个大型语言模型(LLM)在不同基准测试上的性能比较,涵盖了GPT-4o、Meta-Llama-3.1-405B、Meta-Llama-3.1-70B、Meta-Llama-3-70B、Meta-Llama-3.1-8B和Meta-Llama-3-8B等模型。每个基准测试的分数越高,模型的表现越好。以下是具体解读:
核心信息
1. 不同基准测试:
- boolq: 一个问答基准测试,用于评估模型的理解能力。
- gsm8k: 数学问题基准测试,评估模型的数学推理能力。
- hellaswag: 评估模型对常识推理的理解。
- human_eval: 人类评价的编程基准测试,评估模型的代码生成能力。
- mmlu_humanities: 人文科学领域的多项选择基准测试。
- mmlu_other: 其他领域的多项选择基准测试。
- mmlu_social_sciences: 社会科学领域的多项选择基准测试。
- mmlu_stem: STEM(科学、技术、工程、数学)领域的多项选择基准测试。
- openbookqa: 开放性问题回答基准测试。
- piqa: 物理常识基准测试。
- social_iqa: 社会常识基准测试。
- truthfulqa_mc1: 评估模型回答问题的真实性。
- winogrande: 评估模型在解决具有歧义性语言问题上的表现。
2. 模型性能:
- GPT-4o 在各个基准测试中的表现普遍较好,尤其是在human_eval、gsm8k和mmlu_social_sciences等基准测试中表现突出。
- Meta-Llama-3.1-405B 在大多数基准测试中表现最佳,是目前最强的模型之一。
- Meta-Llama-3.1-70B 和 Meta-Llama-3-70B 的表现也很强,尤其是在openbookqa和hellaswag等测试中表现优异。
- Meta-Llama-3.1-8B 和 Meta-Llama-3-8B 的性能较低,尤其在人文科学和STEM领域的基准测试中表现不佳。
重要性
- 算力和数据的重要性:这个图表显示了算力和数据对大语言模型性能的决定性影响。更强大的硬件和更丰富的数据可以显著提升模型的表现。
- 模型规模与性能:模型的规模(参数量)与其性能之间存在正相关关系。更大的模型(如Meta-Llama-3.1-405B)在多数基准测试中表现更佳。
- 多样性评估:使用多种基准测试评估模型的多方面能力,包括数学、常识、编程和人文科学等,提供了全面的性能比较。
- "看这些模型比拼,就像看一场AI奥运会!Meta-Llama-3.1-405B毫无疑问地拿下了金牌!"
- "GPT-4o在human_eval中表现不俗,看来这小家伙在编程方面真是个天才!"
- "Meta-Llama-3.1-8B有点像是来凑数的,但也别小看它,毕竟每个选手都在为团队争光呢。"
总的来说,这个图表展示了当前AI领域不同大型语言模型在各种基准测试上的竞争态势,帮助我们更好地理解这些模型的优势和局限。