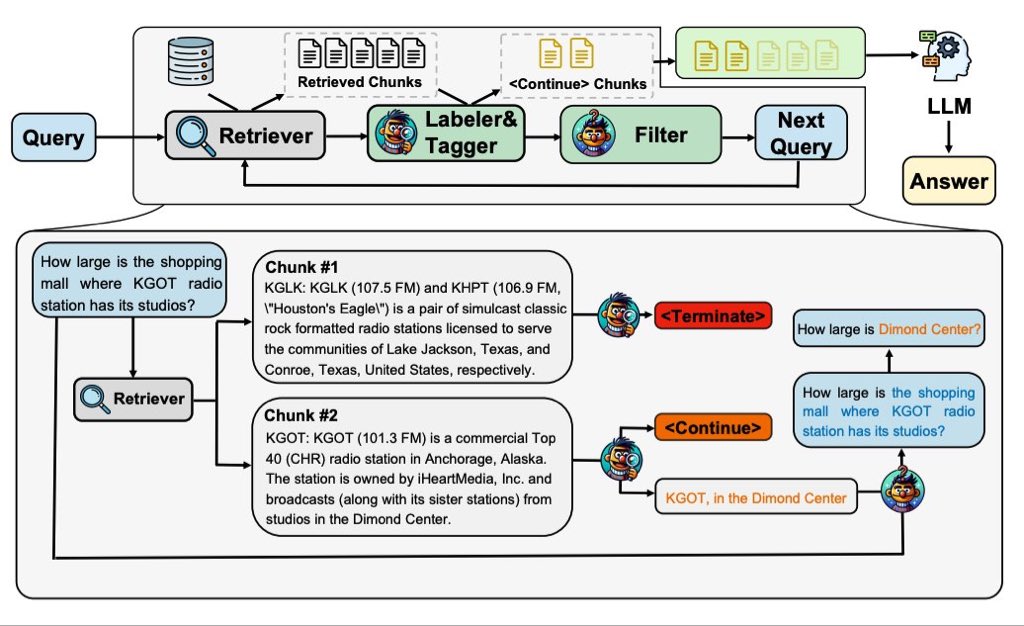
高效多跳问答:增强检索生成(RAG)系统的新突破”
据https://t.co/St5O59lOHV分析,这种RAG系统的改进方法通过两个核心组件提高了效率:
1. 自动编码器标签系统:它训练一个自动编码器语言模型(LM)来标记数据块,识别出哪些信息是终止点(
2. 迭代过滤模型:该模型根据原始问题和先前的注释来制定下一步查询。这个过程会不断迭代,直到所有的数据块被标记为终止,或达到最大迭代次数。
通过这样的设计,该系统有效地减少了多次调用大型语言模型(LLM)的需求,从而提高了回答复杂问题的准确性和效率。同时,通过使用LLM生成的合成数据来训练标签和过滤模型,进一步优化了信息的聚合和无关数据的筛选。
场景:在需要精确解答复杂、多层次问题的场合,如学术研究、技术支持等,此系统能够快速聚合相关知识,提高响应质量。
这种方法不仅提升了效率,还显著减少了不必要的信息干扰,为用户提供更精准、更清晰的答案。更多信息可参考以下链接:https://t.co/6gWz4kdHB4。