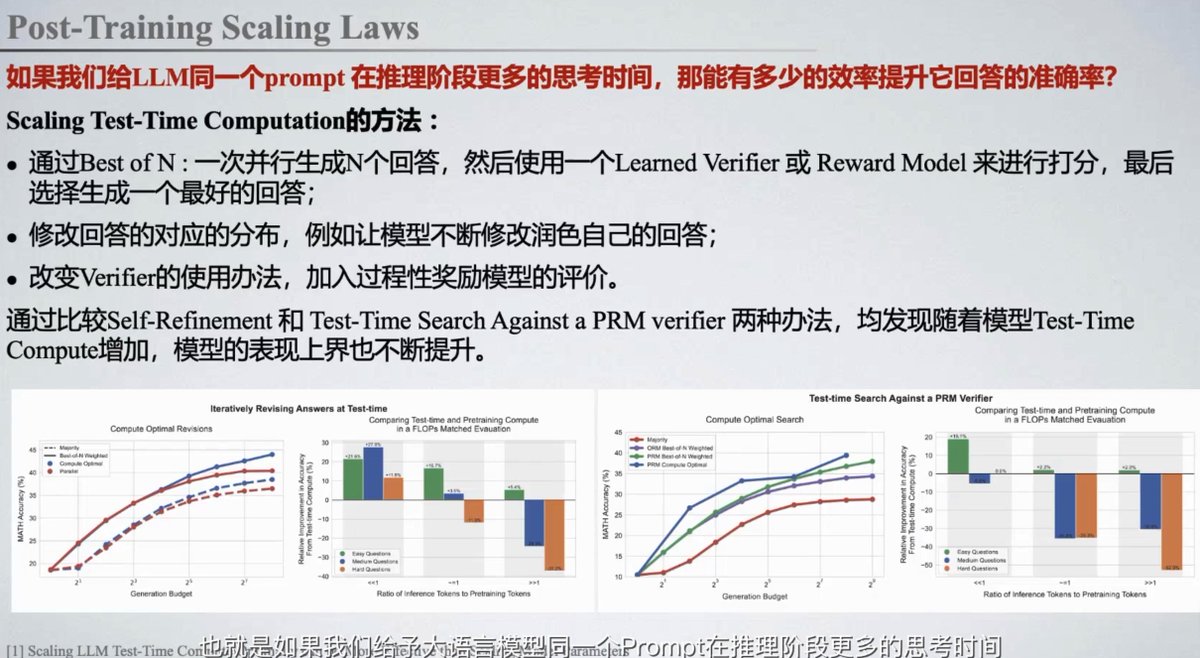
刷B站,居然看到了一个post-training(专指test-time) scaling law的讨论。
这人介绍了DeepMind的一篇paper,讲OpenAI的o1,可能是一次并行生成N个回答,
然后有一个reward model(比GPT-4小很多,专门给答案提供reward,等于一个判卷老师),从里面挑10%的好回答。
(原paper里比较了三种方法, 但都是那PaLM做的,可以不看: https://t.co/xGbfNQMxA7)
看起来这批人的post-training scaling law想法,跟我几乎是完全不同。