
This is very cool. Fast image generation is nice, but imagine you can send 24x24x2 bytes = 1152 bytes and you can share a photo.
Applications: super low bandwidth projects such as radio transmission. Send a map or a photo of a location. Or a family photo.
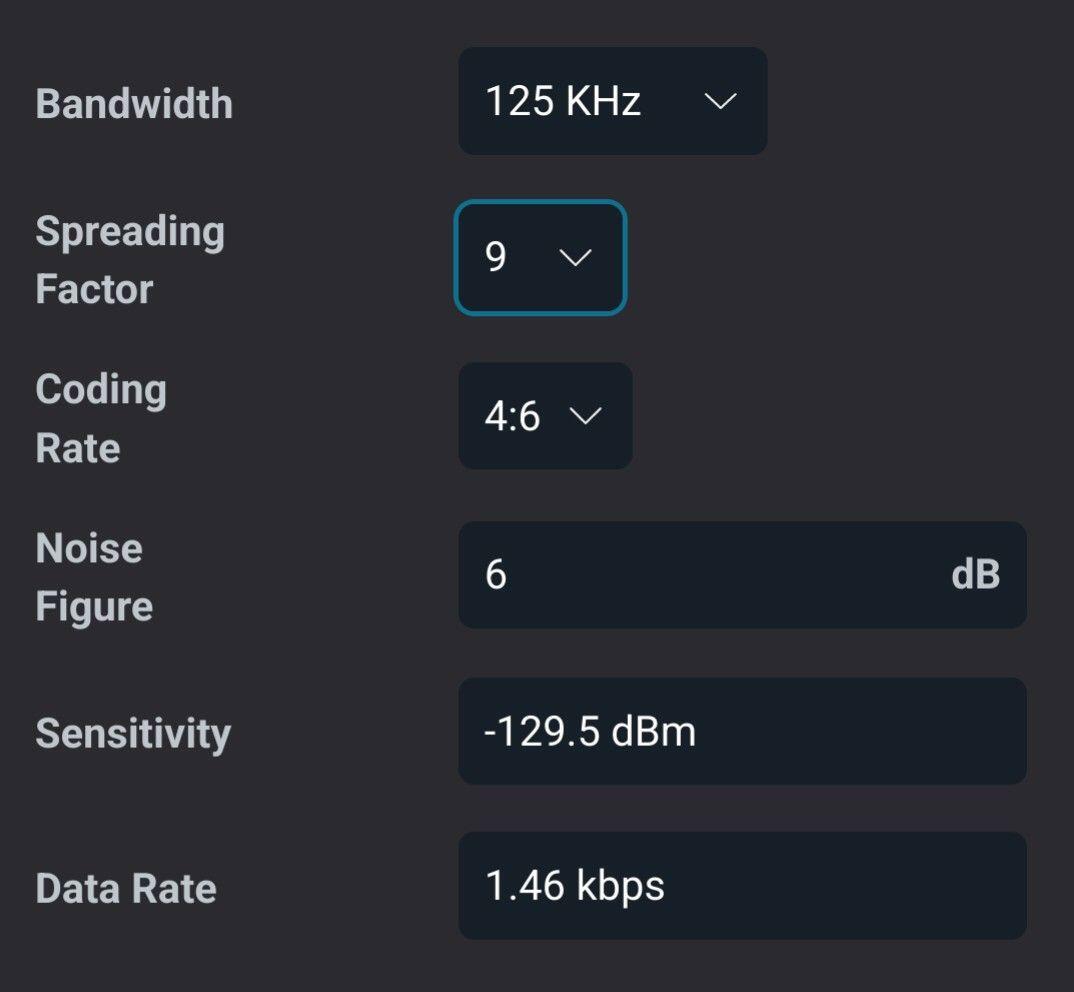
For example with the settings on the picture, you can realistically send the image in 8 seconds (plus encoding and decoding on the phone).
Imagine that you could do the same with audio messages with sound ai models. I think there are very interesting data compression implications of these advanced statistical models.
Considering a duty cycle is also important. For Lora to work, a 1% on air transmission is enforced, so if you broadcast for 8 seconds, you should be silent for 792 seconds. Of course you can have different LoRa parameters that make it even more feasible. 9Kbps is feasible. You can play with your Lora parameters here:
https://unsigned.io/articles/2022_05_05_understanding-lora-parameters.html
Stable Cascade here:
https://github.com/Stability-AI/StableCascade
 #m=image%2Fjpeg&dim=1074x992&blurhash=%3B25%3D9G%7EX-p-%3D.8M%7BIAM%7BM%7Bt7kCt7f6WCt7WBRjj%5BoLWBM%7BayWBM%7BRjofofayWBWBWVoJWAa%7DofjtRPRjkCWAoKt7ozofofo0WBNGofoLWBayofofRjWBfQayWBofofayayRkj%40t7WBbHt7ofayWB&x=cd7e895e45592c6b6d57bd9b57d9ec7563b2c4d307b8b1af6d36270808dd0821
#m=image%2Fjpeg&dim=1074x992&blurhash=%3B25%3D9G%7EX-p-%3D.8M%7BIAM%7BM%7Bt7kCt7f6WCt7WBRjj%5BoLWBM%7BayWBM%7BRjofofayWBWBWVoJWAa%7DofjtRPRjkCWAoKt7ozofofo0WBNGofoLWBayofofRjWBfQayWBofofayayRkj%40t7WBbHt7ofayWB&x=cd7e895e45592c6b6d57bd9b57d9ec7563b2c4d307b8b1af6d36270808dd0821
