
Got "file upload" working with the latest Llama models.
Also, it seems the smallest Llama 1b (fine-tuned) model performs even better with more context.
Which is really good because that one is really fast even on a medium-spec device. 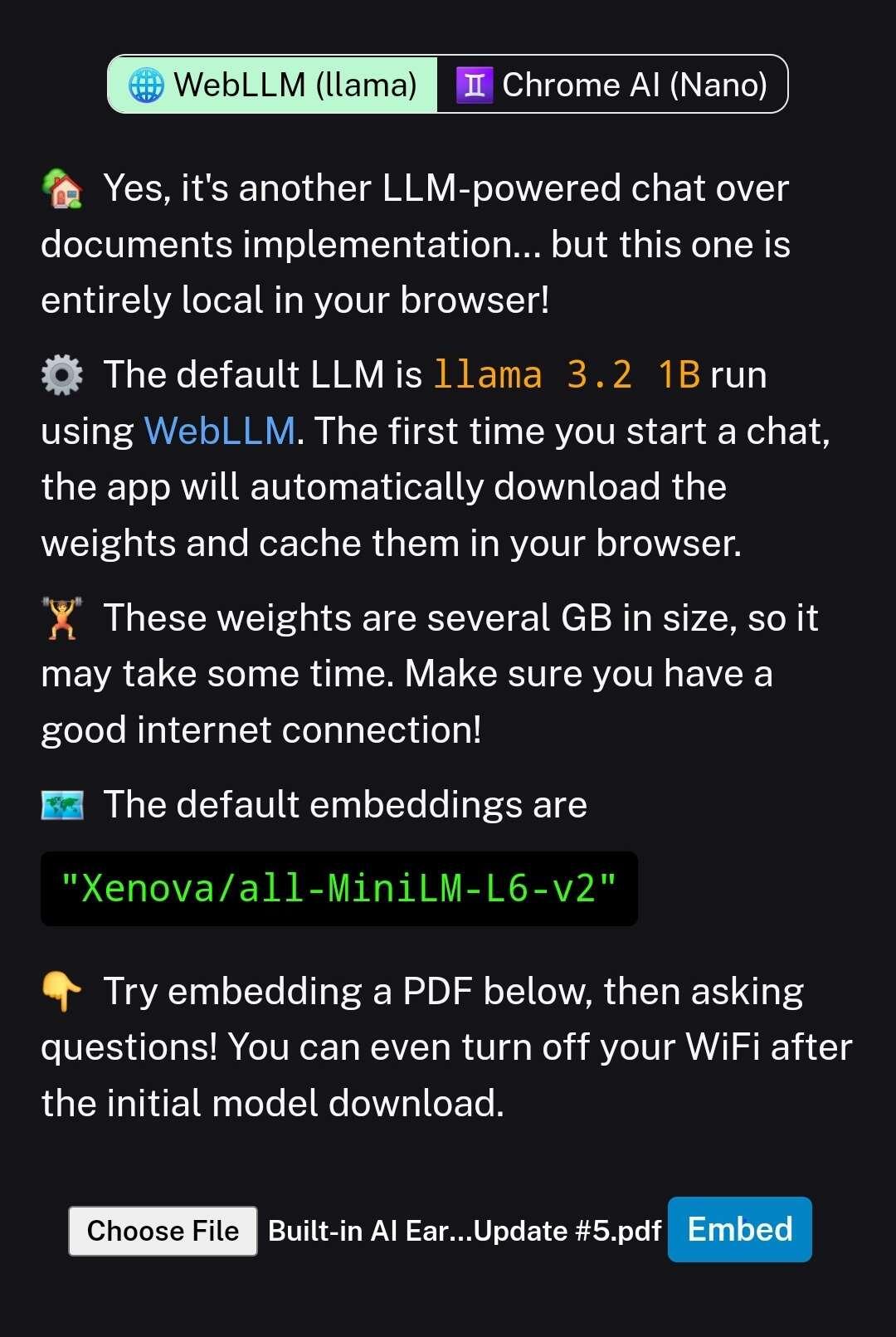
Building a private AI assistant for truly private chat and personal data processing (e.g., notes, PDFs).
Planning to create a PWA web app that allows users to run any LLM model, including the latest LLaMA 3.2-1B, locally on any device or OS, even offline.
Users will simply select the model, and the app will automatically download, cache, and store it for future use. The next time, loading will be much faster.
The MLC-LLM library makes implementation straightforward, supporting all platforms and leveraging WebGPU for maximum performance.
Coming soon, meanwhile check there library repo. They have lots of examples.
MLC library repo: https://llm.mlc.ai/docs/deploy/webllm.html

Got "file upload" working with the latest Llama models.
Also, it seems the smallest Llama 1b (fine-tuned) model performs even better with more context.
Which is really good because that one is really fast even on a medium-spec device.