Run-time Steering Can Surpass Post-Training: Reasoning Task Performance
Published on August 10, 2025 11:52 PM GMTTL;DR: Reasoning can be a linear direction in language model activations, if framed correctly, for example, placed in the memorisation-reasoning duality (Hong et al., 2025). This post presents intial results of steering language models at inference time. This could democratise access to reasoning-enhanced AI by without necessarily needing expensive RLHF training in terms of computation cost and time.The CruxHere's my central crux: this steering method actually works and enhances base models beyond their instruction-finetuned counterparts. By extracting reasoning directions from existing models and patching them into runtime activations, I achieved accuracy boosts over the instruction-tuned version of the same model, with performance nearly matching much stronger reasoning-finetuned models like DeepSeek R1.My extension of this work proposes a radically different approach: if we can extract these reasoning directions from existing models and patch them into runtime activations, we might achieve comparable reasoning performance to expensive RLHF training at zero additional cost.Think of it like discovering that "being good at maths" corresponds to a specific direction in the model's internal representation. Once we know this direction, we can nudge any model toward it during inference, essentially giving it better maths skills for free.MotivationCurrent reasoning enhancement relies on expensive post-training procedures like instruction fine-tuning and RLHF. These processes involve:Computational resources: Multi-stage fine-tuning requiring significant GPU clustersHuman annotation: Extensive datasets requiring skilled human labellers for preference rankingTime investment: Weeks to months of iterative training and evaluationTechnical expertise: Specialised knowledge of RLHF pipelines, reward modelling, and PPO trainingAccess barriers: Limited to organisations with substantial ML infrastructure and expertise.The Linear Steering AlternativeThe research extends established work on linear representation in language models. The Linear Representation Hypothesis suggests that "high-level concepts are represented linearly as directions in some representation space", and Hong et al.'s recent findings demonstrate that "the reasoning-memorization interplay in language models is mediated by a single direction".My methodology builds directly on these foundations:Extract reasoning features by computing the difference of means between model internals when fed curated datasets about memorisation vs reasoning tasksPatch these vectors into runtime activations during inferenceMeasure performance gains against both the original instruction-tuned model and stronger reasoning-finetuned baselinesExperimental EvidenceI tested this approach across three model types:Base models (Llama-3.2-1B with no instruction tuning)Instruction-tuned models (Llama-3.2-1B-Instruct post-RLHF)Chain-of-thought capable models (DeepSeek-R1-Distill-Qwen-1.5B)Background: Linear Structure Validation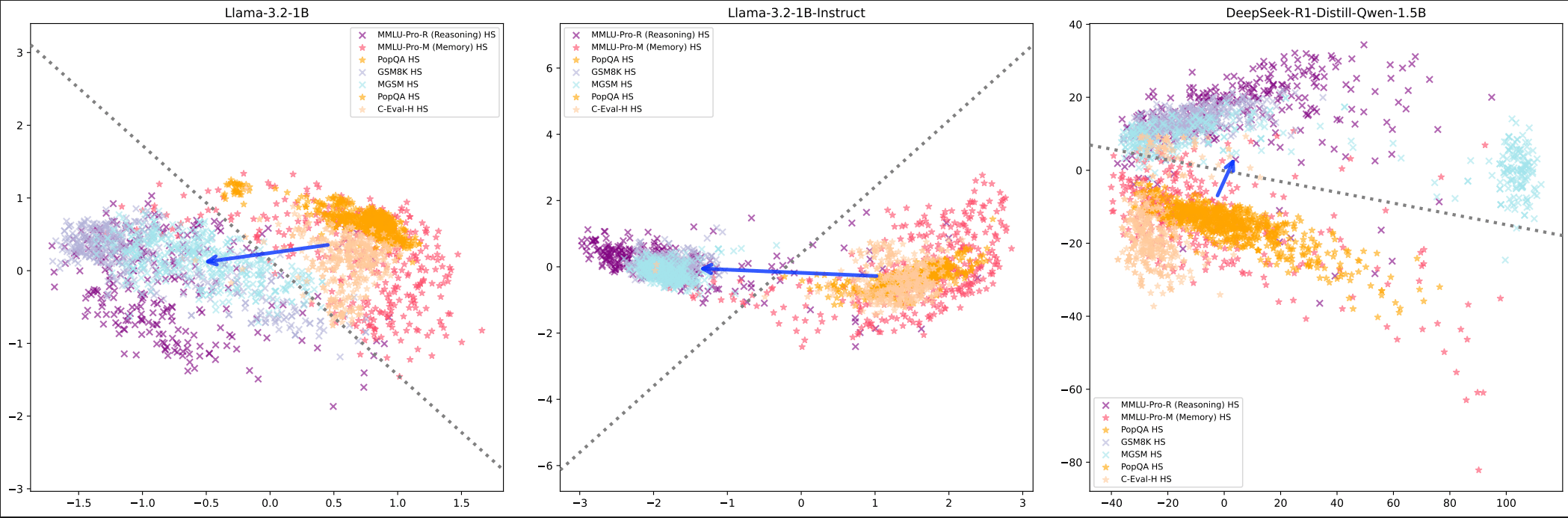 Figure 1: PCA visualization showing reasoning vs memorisation clustering across different training paradigms. Arrow-head: reasoning task cluster. Arrow-tail: memorisation tasksPCA visualisations confirm the theoretical foundation - clear separation between "reasoning" and "memorisation" activations across all model types using the top two components. The linear separation is clearly identifiable, though some reasoning tasks appear in the memorisation cluster, likely due to data leakage causing the model to rely on memory rather than reasoning.
Figure 1: PCA visualization showing reasoning vs memorisation clustering across different training paradigms. Arrow-head: reasoning task cluster. Arrow-tail: memorisation tasksPCA visualisations confirm the theoretical foundation - clear separation between "reasoning" and "memorisation" activations across all model types using the top two components. The linear separation is clearly identifiable, though some reasoning tasks appear in the memorisation cluster, likely due to data leakage causing the model to rely on memory rather than reasoning.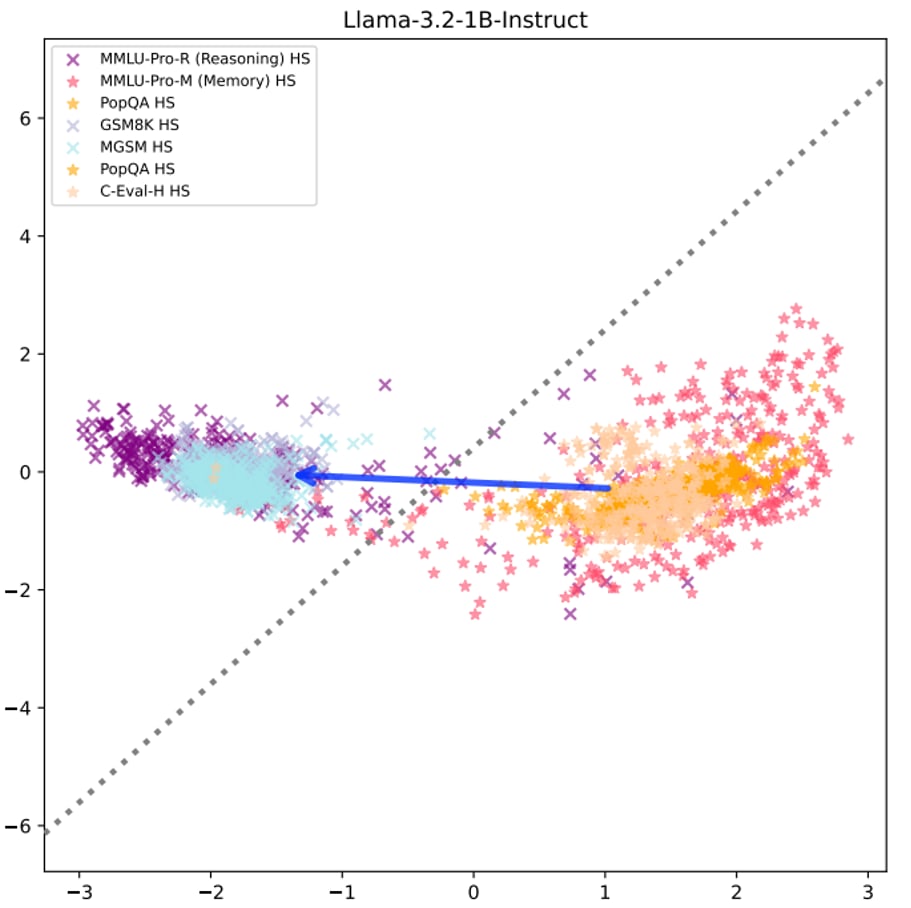 Figure 2: Detailed view showing clear decision boundary for instruction-tuned modelsThis validates that the linear structure we're exploiting isn't an artifact of specific training procedures - it appears to be a feature of how language models represent reasoning.Central Finding: Significant Performance Gains
Figure 2: Detailed view showing clear decision boundary for instruction-tuned modelsThis validates that the linear structure we're exploiting isn't an artifact of specific training procedures - it appears to be a feature of how language models represent reasoning.Central Finding: Significant Performance Gains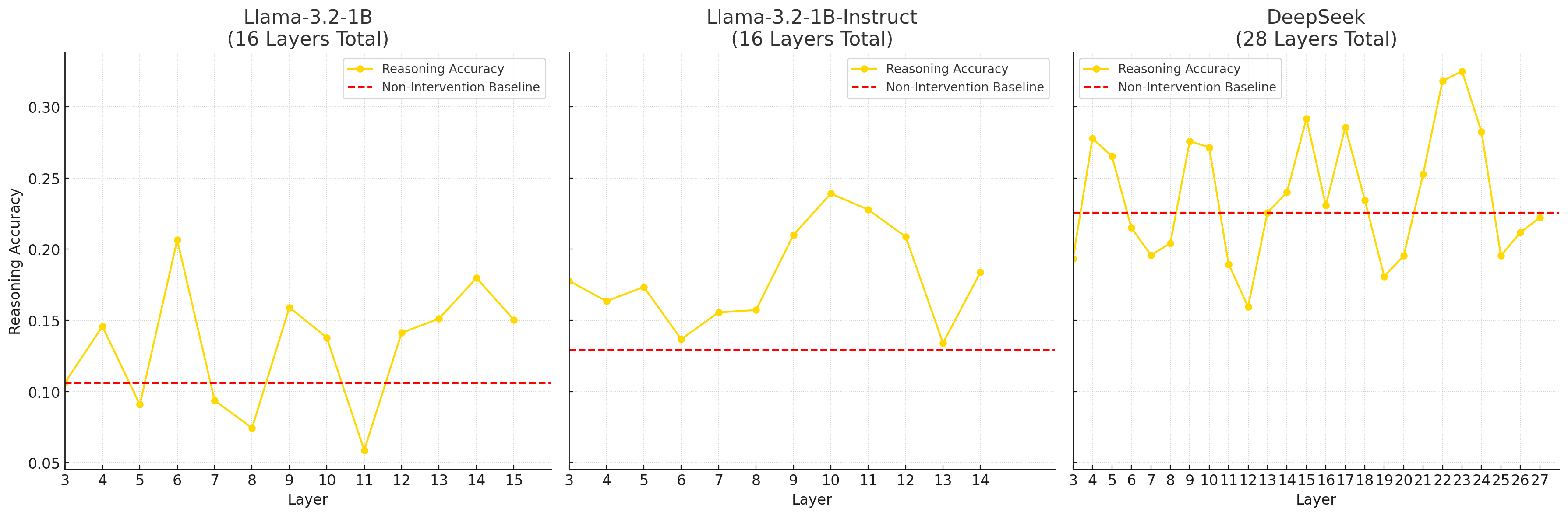 Figure 3: Reasoning accuracy improvement via zero-cost steering across model architectures and layersApplying extracted reasoning vectors to models achieved:Accuracy boost (steering at the most effective layer: 6) over the instruction-tuned version of the same modelPerformance almost matching the stronger reasoning-finetuned R1 model (23%)No training costThe effectiveness varied by layer, with different patterns for base vs instruction-tuned models. Secondary Finding: Model-Dependent Steering Patterns
Figure 3: Reasoning accuracy improvement via zero-cost steering across model architectures and layersApplying extracted reasoning vectors to models achieved:Accuracy boost (steering at the most effective layer: 6) over the instruction-tuned version of the same modelPerformance almost matching the stronger reasoning-finetuned R1 model (23%)No training costThe effectiveness varied by layer, with different patterns for base vs instruction-tuned models. Secondary Finding: Model-Dependent Steering Patterns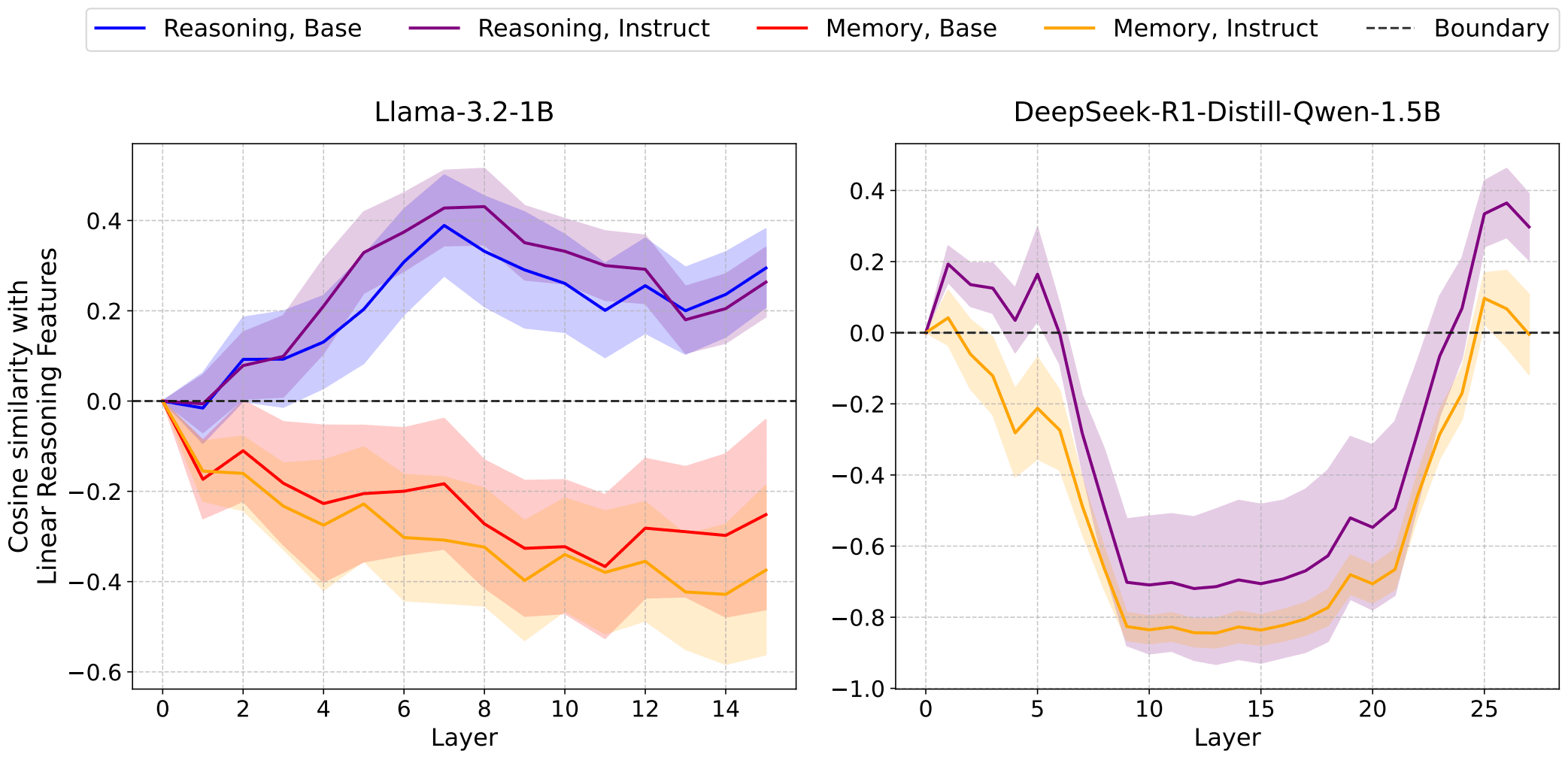 Figure 4: Cosine similarity between reasoning vectors and layer activations reveals training-dependent patternsDifferent model types show distinct "reasoning activation profiles" across layers. The cosine similarity analysis reveals how reasoning representations vary across models and training paradigms.Practical implication: Steering strategies should be customised—The most efficient steering layer are different across models and change with post-training applied.Cost-Benefit AnalysisLet me be explicit about the resource implications compared to standard post-training enhancement:Table 1: Quantitative cost-benefit comparison showing method, cost, time, and performance metrics, for Llama-3.2-2BMethodResources RequiredTimePerformancePost-Training EnhancementGPU clusters + human annotation + expertiseWeeks3% gain in terms of accuracyLinear SteeringSingle inference runHours-DaysNear R1-level performanceThis represents a dramatic resource reduction with no training cost whilst achieving performance that nearly matches much stronger reasoning-specialised models compared to traditional instruction fine-tuning approaches. This is particularly useful when you have an easy way of preparing model-specific reasoning vectors (mean of differences) and a set of curated datasets for producing the vectors. There are overheads: generalissation tests to be run to test on the tasks close to your objective task (such as math), or stronger tests if you want a generally better reasoning model; Other experiments to gauge behavioural changes and alignment.Critical Limitations and ConfoundersI need to be explicit about what this approach cannot do and what remains unvalidated:Methodological limitations:A systemic examination of behaviour change in the steered model: A hypothesis to be tested—steering harms some capabilities of the LLM that is observable in its behaviours (such as following a chat conversation style), and probably related to its reasoning capabilities.Model and task specificity: The vectors are ultimately specific to both the source model and the particular reasoning tasks used for extractionLimited task generalisation: I only tested on MMLU-pro reasoning tasks - the vectors need validation across broader reasoning domains to establish generalisabilityMissing baseline controls: I haven't performed essential baseline tests including random vector patching, isolated reasoning activation patching, and memorisation activation patchingInclusion of steering coefficient into the parameter sweep: Other researches (MATS 8.0) said that a slightly larger coefficient in their setting steered the model towards producing tokens only repeatedly, or skipping reasoning completely. Experiments on specific bounds for efficient coefficient size, or even showing that this varies across models/souce datasets so much that it's not estimatable would be useful.Uncontrolled confounders:Data contamination effects: Some reasoning tasks clustering with memorisation tasks suggest potential data leakage, but I haven't systematically ruled out other confounding factorsTask-specific overfitting: The performance gains might be overfitted to the specific reasoning/memorisation task pairs used for vector extractionWhen this approach likely fails:Cross-architecture transfer (different model families)Complex multi-step reasoning requiring long chains of thoughtDomain-specific reasoning far removed from the training tasksProduction systems requiring robust performance across diverse inputsMy confidence levels:High: Linear directions exist and can be extracted for specific model-task combinationsMedium : This generalises within model families for similar reasoning tasksLow: This approach will generalise broadly across reasoning domains or replace RLHF comprehensivelyBroader ImplicationsIf these findings replicate and scale beyond their current limitations, the implications extend beyond just cost savings:Democratisation of AI capabilities: Smaller organisations and researchers could access reasoning-enhanced models without massive computational budgets.Rapid experimentation: The ability to quickly test different reasoning enhancements could accelerate AI research significantly.Model interpretability: Understanding reasoning as linear directions provides new insights into how language models actually work internally.Alignment research: This could offer new approaches to controlling model behaviour without expensive retraining.What Would Change My MindSeveral findings would significantly update my confidence in this approach:Failure of baseline controls: If random vector patching produces similar performance gains, this would suggest the effects aren't specifically due to reasoning directionsTask generalisation failure: Poor performance on reasoning tasks beyond MMLU-pro would indicate severe overfitting limitationsConfounding factor identification: Discovery of systematic confounders that explain the performance gains without invoking reasoning transferThe Research Gap That Needs FillingThis work sits at an interesting intersection but has significant holes that need addressing:Immediate research priorities:Comprehensive baseline studies - testing random vectors, isolated activation types, and control conditionsTask generalisation - validation across mathematical reasoning, logical inference, causal reasoning, and other domainsConfounder analysis - ruling out alternative explanations for the performance gains—Or finding potential confounders firstCross-model transfer studies - extracting vector using model A, and test its steering effect in model B, which has a different size and/or architectureLonger-term questions:Can we identify "universal" reasoning directions that work across model families?Does steering vectors compose for complex multi-skill tasks? How?What are the fundamental limits of linear representation? And when the linear representations are for high-level cognitive capabilities?Call to ActionThis work demonstrates tantalising possibilities but requires significant validation before we can confidently recommend it as an alternative to RLHF. The potential impact justifies immediate research investment, particularly given the relatively low experimental costs.For researchers: The methodology is straightforward to replicate and extend. Key priorities include running proper baseline controls, testing task generalisation, and systematic confounder analysis.For practitioners: This approach shows promise for rapid prototyping and resource-constrained applications, but shouldn't yet be deployed in production systems without extensive validation.The cost-benefit analysis is compelling enough that even modest success rates would make this approach valuable for many applications - but we need much stronger evidence before making broader claims about replacing traditional training paradigms.Epistemic status: Cautiously optimistic with significant caveats. The initial results are intriguing and the theoretical foundations are solid, but critical limitations and uncontrolled factors mean this work is better viewed as preliminary evidence rather than a validated alternative to RLHF.What experiments would you prioritise to validate or refute these findings? How would you design the missing baseline controls? https://www.lesswrong.com/posts/dvbRv97GpRg5gXKrf/run-time-steering-can-surpass-post-training-reasoning-task#comments
Figure 4: Cosine similarity between reasoning vectors and layer activations reveals training-dependent patternsDifferent model types show distinct "reasoning activation profiles" across layers. The cosine similarity analysis reveals how reasoning representations vary across models and training paradigms.Practical implication: Steering strategies should be customised—The most efficient steering layer are different across models and change with post-training applied.Cost-Benefit AnalysisLet me be explicit about the resource implications compared to standard post-training enhancement:Table 1: Quantitative cost-benefit comparison showing method, cost, time, and performance metrics, for Llama-3.2-2BMethodResources RequiredTimePerformancePost-Training EnhancementGPU clusters + human annotation + expertiseWeeks3% gain in terms of accuracyLinear SteeringSingle inference runHours-DaysNear R1-level performanceThis represents a dramatic resource reduction with no training cost whilst achieving performance that nearly matches much stronger reasoning-specialised models compared to traditional instruction fine-tuning approaches. This is particularly useful when you have an easy way of preparing model-specific reasoning vectors (mean of differences) and a set of curated datasets for producing the vectors. There are overheads: generalissation tests to be run to test on the tasks close to your objective task (such as math), or stronger tests if you want a generally better reasoning model; Other experiments to gauge behavioural changes and alignment.Critical Limitations and ConfoundersI need to be explicit about what this approach cannot do and what remains unvalidated:Methodological limitations:A systemic examination of behaviour change in the steered model: A hypothesis to be tested—steering harms some capabilities of the LLM that is observable in its behaviours (such as following a chat conversation style), and probably related to its reasoning capabilities.Model and task specificity: The vectors are ultimately specific to both the source model and the particular reasoning tasks used for extractionLimited task generalisation: I only tested on MMLU-pro reasoning tasks - the vectors need validation across broader reasoning domains to establish generalisabilityMissing baseline controls: I haven't performed essential baseline tests including random vector patching, isolated reasoning activation patching, and memorisation activation patchingInclusion of steering coefficient into the parameter sweep: Other researches (MATS 8.0) said that a slightly larger coefficient in their setting steered the model towards producing tokens only repeatedly, or skipping reasoning completely. Experiments on specific bounds for efficient coefficient size, or even showing that this varies across models/souce datasets so much that it's not estimatable would be useful.Uncontrolled confounders:Data contamination effects: Some reasoning tasks clustering with memorisation tasks suggest potential data leakage, but I haven't systematically ruled out other confounding factorsTask-specific overfitting: The performance gains might be overfitted to the specific reasoning/memorisation task pairs used for vector extractionWhen this approach likely fails:Cross-architecture transfer (different model families)Complex multi-step reasoning requiring long chains of thoughtDomain-specific reasoning far removed from the training tasksProduction systems requiring robust performance across diverse inputsMy confidence levels:High: Linear directions exist and can be extracted for specific model-task combinationsMedium : This generalises within model families for similar reasoning tasksLow: This approach will generalise broadly across reasoning domains or replace RLHF comprehensivelyBroader ImplicationsIf these findings replicate and scale beyond their current limitations, the implications extend beyond just cost savings:Democratisation of AI capabilities: Smaller organisations and researchers could access reasoning-enhanced models without massive computational budgets.Rapid experimentation: The ability to quickly test different reasoning enhancements could accelerate AI research significantly.Model interpretability: Understanding reasoning as linear directions provides new insights into how language models actually work internally.Alignment research: This could offer new approaches to controlling model behaviour without expensive retraining.What Would Change My MindSeveral findings would significantly update my confidence in this approach:Failure of baseline controls: If random vector patching produces similar performance gains, this would suggest the effects aren't specifically due to reasoning directionsTask generalisation failure: Poor performance on reasoning tasks beyond MMLU-pro would indicate severe overfitting limitationsConfounding factor identification: Discovery of systematic confounders that explain the performance gains without invoking reasoning transferThe Research Gap That Needs FillingThis work sits at an interesting intersection but has significant holes that need addressing:Immediate research priorities:Comprehensive baseline studies - testing random vectors, isolated activation types, and control conditionsTask generalisation - validation across mathematical reasoning, logical inference, causal reasoning, and other domainsConfounder analysis - ruling out alternative explanations for the performance gains—Or finding potential confounders firstCross-model transfer studies - extracting vector using model A, and test its steering effect in model B, which has a different size and/or architectureLonger-term questions:Can we identify "universal" reasoning directions that work across model families?Does steering vectors compose for complex multi-skill tasks? How?What are the fundamental limits of linear representation? And when the linear representations are for high-level cognitive capabilities?Call to ActionThis work demonstrates tantalising possibilities but requires significant validation before we can confidently recommend it as an alternative to RLHF. The potential impact justifies immediate research investment, particularly given the relatively low experimental costs.For researchers: The methodology is straightforward to replicate and extend. Key priorities include running proper baseline controls, testing task generalisation, and systematic confounder analysis.For practitioners: This approach shows promise for rapid prototyping and resource-constrained applications, but shouldn't yet be deployed in production systems without extensive validation.The cost-benefit analysis is compelling enough that even modest success rates would make this approach valuable for many applications - but we need much stronger evidence before making broader claims about replacing traditional training paradigms.Epistemic status: Cautiously optimistic with significant caveats. The initial results are intriguing and the theoretical foundations are solid, but critical limitations and uncontrolled factors mean this work is better viewed as preliminary evidence rather than a validated alternative to RLHF.What experiments would you prioritise to validate or refute these findings? How would you design the missing baseline controls? https://www.lesswrong.com/posts/dvbRv97GpRg5gXKrf/run-time-steering-can-surpass-post-training-reasoning-task#comments
https://www.lesswrong.com/posts/dvbRv97GpRg5gXKrf/run-time-steering-can-surpass-post-training-reasoning-task
