OpenAI的o1模型是如何“思考”的?——揭秘推理token的魔力
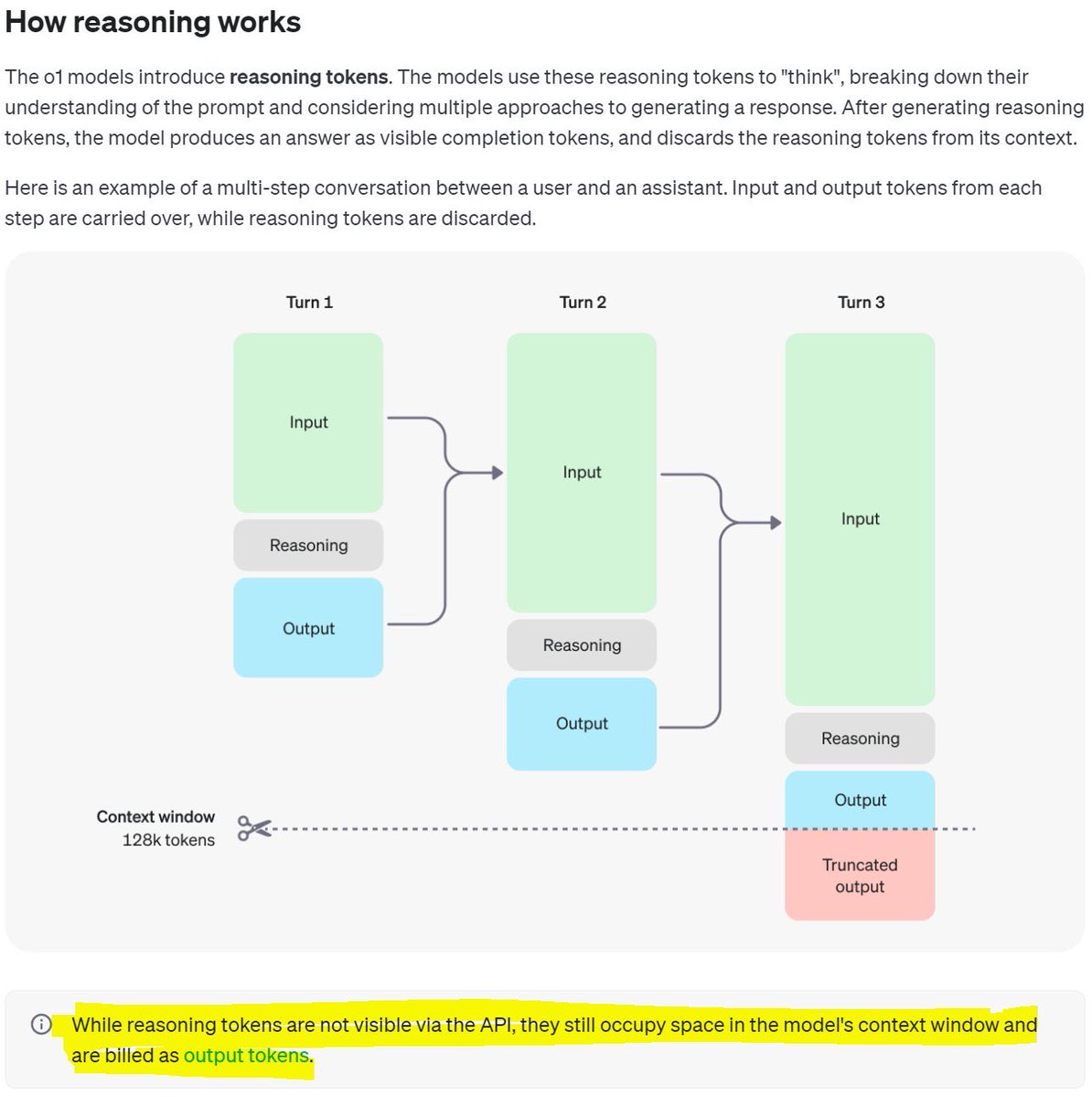
这个图展示了o1模型如何利用“推理令牌”来进行多步骤的对话。简单来说,当你输入一个问题(Input),模型会先用推理令牌(Reasoning)来“思考”,然后生成输出结果(Output)。在每一步对话中,输入和输出会被保留,但推理令牌会被丢弃。
换句话说,推理token是模型在幕后进行复杂计算和分析的工具,虽然它们不会出现在API的可见结果中,但它们仍然占用模型的上下文空间,并被计入输出token
让我们详细解读这张图,逐步解释每个步骤:
第一步:输入阶段(Turn 1)
1. Input(输入):用户向模型输入一个问题或请求。这是模型开始处理的初始数据。
2. Reasoning(推理):模型内部使用“推理令牌”来理解和分析输入。推理令牌是模型在幕后进行复杂计算和推理的工具。
3. Output(输出):经过推理后,模型生成一个可见的输出结果,并将其返回给用户。
第二步:第二轮对话(Turn 2)
1. Input(输入):在第二轮对话中,用户再次输入新的问题或继续之前的问题。此时,前一轮的输入和输出信息被保留。
2. Reasoning(推理):模型再次使用推理令牌来处理新的输入。它会结合上下文信息进行更深入的分析和理解。
3. Output(输出):模型生成新的输出结果,并将其返回给用户。
第三步:第三轮对话(Turn 3)
1. Input(输入):用户继续对话,输入新的问题或请求。前两轮的输入和输出信息继续被保留,以便提供上下文。
2. Reasoning(推理):模型再一次使用推理令牌进行分析和计算。这些推理令牌虽然不可见,但在后台占用模型的上下文空间。
3. Output(输出):模型生成最终的输出结果,并将其返回给用户。如果对话变得过长,一些早期的信息可能会被截断。
关键点总结
- Context Window (上下文窗口): 模型有一个128k令牌的上下文窗口,用于存储对话中的所有输入、输出和推理过程。
- Reasoning Tokens (推理令牌): 推理令牌用于模型内部计算和分析,不会显示在最终的API结果中,但它们仍然占用上下文空间,并计入最终的输出令牌。
通过这种方式,o1模型能够在多步骤对话中保持高效且精准的回答能力,同时确保每一步都基于之前的信息进行合理分析。这使得o1不仅能处理复杂的问题,还能在连续对话中提供一致性和上下文相关性更高的回答。