
interesting..

Welcome to Nostr, Orange Book! You used to follow me years ago on Twitter. Glad to see you've made it over here.
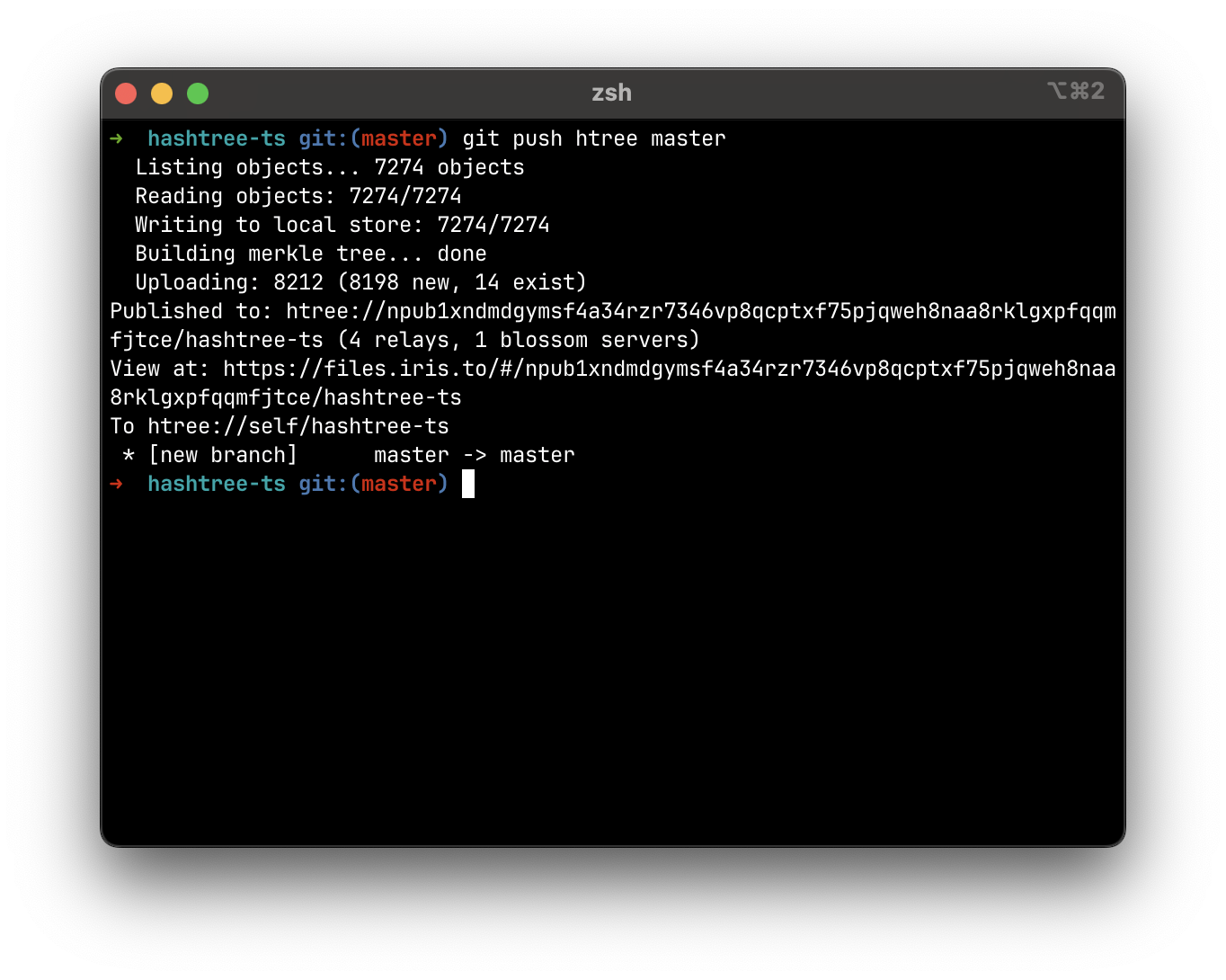
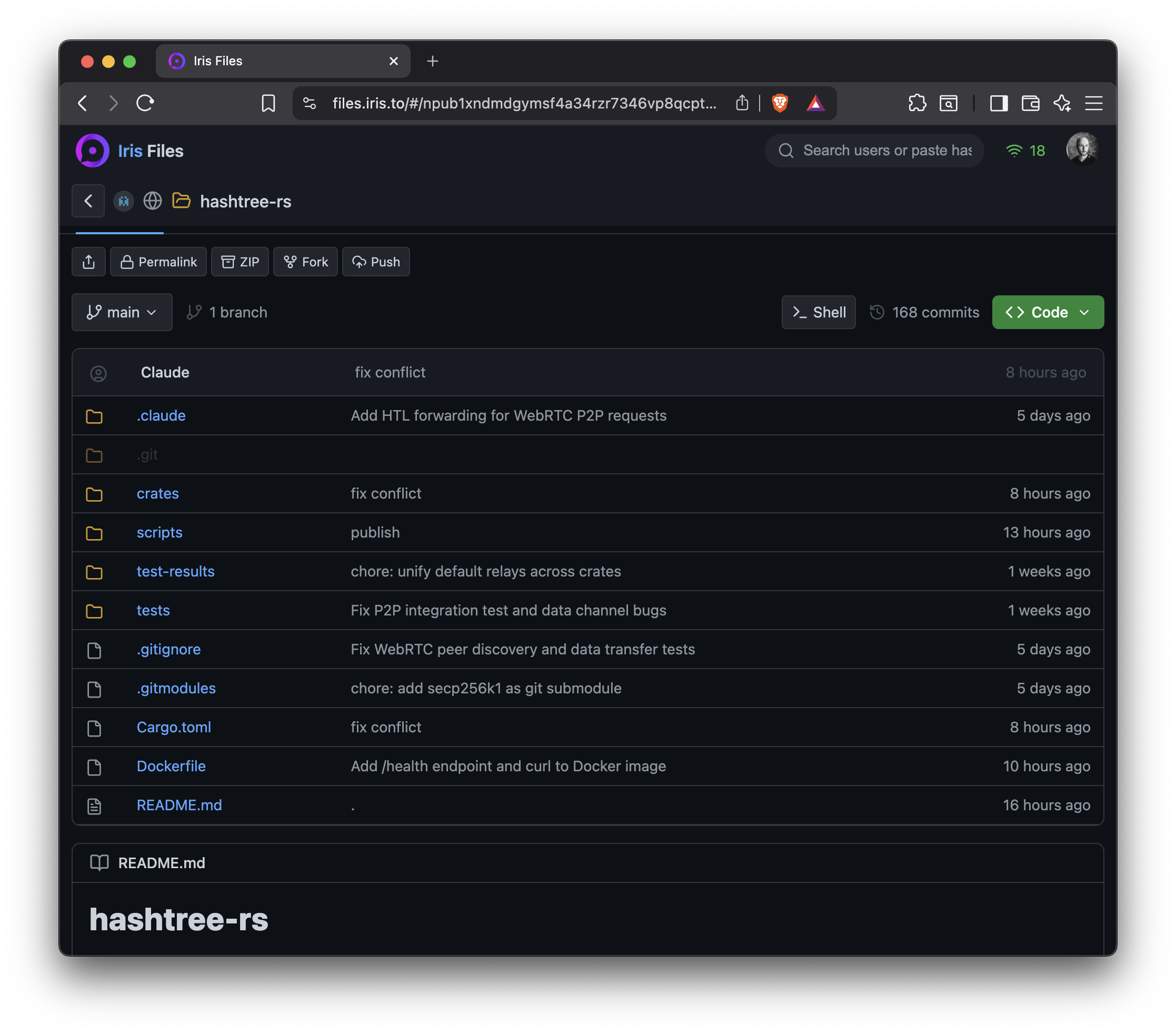
No more GitHub — publish your git repos on Blossom:
---
cargo install hashtree-cli
cd your_repo
# self is an auto-generated nostr identity (nsec) in ~/.hashtree/keys
git remote add htree htree://self/your_repo
git push htree master
clone:
git clone htree://npub1xndmdgymsf4a34rzr7346vp8qcptxf75pjqweh8naa8rklgxpfqqmfjtce/hashtree-rs
view at files.iris.to e.g. https://files.iris.to/#/npub1xndmdgymsf4a34rzr7346vp8qcptxf75pjqweh8naa8rklgxpfqqmfjtce/hashtree-rs
---
Vibe coded this in 3 weeks, using Claude Opus 4.5, along with
https://docs.iris.to collaborative docs editor
https://video.iris.to decentralized youtube
https://files.iris.to decentralized filesharing
https://meet.iris.to decentralized video calls
I believe AI will be actually good for freedom tech: soon everyone will have the resources to create the software they need, not just big tech.
This only works for self-hosting though. We tried this exact method 3 years ago and it failed because users can't simply download a Merkle tree of your git repo... the .git folder can't be transferred between PCs that easily. This is more like GitTea but enhanced, not quite GitHub. GitHub has the social element.
AI coding helps but creating something for at scale use still requires more than a few weeks of vibe coding.
Someone dumping stolen coins won’t kill bitcoin..
Setting a precedent that devs can alter account balances during “emergencies” is a much bigger long-term threat, especially if the “emergency” hasn’t arrived yet.
It’s a very dangerous precedent that should be resisted despite a price drop from someone dumping coins — minimizing the power devs wield is far more important. Nomos operates off of precedents, whether it’s legal or social consensus.
Arbitrarily deciding when to freeze peoples’ coins against a threat that has an unknown arrival time is irresponsible. I don’t disagree with adding quantum key schemes. I disagree with freezing peoples’ coins.
When the quantum threat hits is unknown. Confiscating coins beforehand is irresponsible. It’s difficult because there’s likely no lead time, so I defer to not confiscating.
In December 2023, a U.S. Senate investigation revealed that governments worldwide have been demanding push notification records from Apple and Google to surveil smartphone users, including tying anonymous messaging accounts to real identities. For years, privacy engineers dismissed this attack vector as unsolvable, since mobile operating systems require routing through platform servers.
MIP-05, a new specification for the Marmot Protocol, proves them wrong: by encrypting device tokens with probabilistic encryption and delivering notifications through gift-wrapped Nostr events, it makes push notifications functionally anonymous. If you care about private communication, this is the specification you need to understand.
The specification is currently in draft and open for review: https://github.com/marmot-protocol/marmot/pull/18 nostr:naddr1qqgx2dpjv9nr2dpjvejryvpcv3nxzq3qklkk3vrzme455yh9rl2jshq7rc8dpegj3ndf82c3ks2sk40dxt7qxpqqqp65w2exg09
This is intriguing. Maybe potential to use this in nostr:npub1ph0n0nlw37vwze32uwy68r9crhywmj89lnpljssyr6j6g2jv944svmcn4n nostr:npub1ms9ujlulcgtpqn2uzpvhplee9l5kjg8jgqhrwmgutg0n7xk43nqq07qa0v
Instagram just released algorithm settings.


Bounty Rush.
Raising intelligence won’t automatically make a high trust society, but it may allow people to more deeply grasp the important elements of social scalability like the immutable constitution or consensus rules — which are rules that supersede diversity and differences, these rules apply universally to all parties whether they’re trusted or not. As more see the wisdom of this, there will be more global adoption of it — perhaps a voluntary-like form of Manifest Destiny.
”NostrDB now underpins Damus Android and Notedeck and is being adopted by other nostr applications, including AirChat”
https://opensats.org/blog/advancements-in-nostr-clients
🙄
My bank account is negative $33. Truly, I am spent. Time is running out!
This phobia to big clients is* mindless if data portability is still preserved.
Ahh sorry I thought you coded it. Would love to see a collab between Martti’s WoT package and Cairo.
Which WoT package are you using? Is it from nostr:npub1g53mukxnjkcmr94fhryzkqutdz2ukq4ks0gvy5af25rgmwsl4ngq43drvk
Airchat won’t go public until this is ready. Otherwise spam in the Discovery feed will become overwhelming. Good luck! 🍀

I'm excited to introduce Nostr Social Duck, or just NSD, a library I've been crafting over the last two weekends that brings sophisticated social graph analysis, even to hardware that doesn't have the luxury of abundant memory. This library leverages DuckDB to perform graph operations over Nostr social graphs built from Contact List events (kind 3), and it's designed to run on all sorts of hardware, from low-end devices to powerful servers.
The inspiration came from limitations I encountered with nostr:npub1g53mukxnjkcmr94fhryzkqutdz2ukq4ks0gvy5af25rgmwsl4ngq43drvk excellent nostr-social-graph library. While powerful, loading entire social graphs into memory becomes challenging, specially on resource constrained devices like older computers, mobile devices, Raspberry Pis, and similar environments. Once the graph grows, memory constraints can cause performance issues or outright failures.
The recent launch of Relatr and its inclusion in the Umbrel community store (thanks to nostr:npub1ye5ptcxfyyxl5vjvdjar2ua3f0hynkjzpx552mu5snj3qmx5pzjscpknpr ) got us thinking: how could we enable anyone to run this without being constrained by their hardware? Since disk storage is cheaper than memory, how we can balance the tradeoffs 🤔... That's when DuckDB emerged as the perfect solution
DuckDB is quite a cool piece of software that's been around for some time with an amazing team committed to open source. It's an embedded, in-process database designed to run on all sorts of hardware. What makes DuckDB particularly compelling for our use case are its advanced memory management capabilities. When complex queries require more memory than available, DuckDB automatically spills to disk, ensuring queries complete even if there is not enough memory, rather than crash. No memory, no problem.
This feature alone makes DuckDB a strong choice, but there's more. Its advanced analytic SQL capabilities make graph analysis operations possible and performant. NSD already provides methods to get the shortest distance between pubkeys, along with a complementary method to find the shortest path that returns both the path and distance. You can define a root pubkey which creates a temporary table with all distances precomputed, making subsequent queries much faster.
The library also includes methods for social graph analysis, like, get the degree of a pubkey, how many inbound and outbound connections it has, which helps determine the weight of a pubkey in the graph. There are convenient methods to check if one pubkey follows another or if two pubkeys are mutual follows. As well thanks to DuckDB in the future we could use parquet files to distribute social graph data. You can find all the details in the repo.
We're currently refactoring Relatr to use NSD, and the results are impressive. By replacing the previous combination of nostr-social-graph library and SQLite database with DuckDB and NSD, we've eliminated the inefficiencies of having separate data sources. Complex queries like profile search now benefit from analytical SQL directly in the search algorithm, reducing data transfer between the program and database and returning more relevant results efficiently.
I did some naive benchmarking to understand how it performs compared to the nostr-social-graph library, and it behaves pretty well. Both libraries are pretty close in performance when there's a root pubkey set in NSD.
This effort aligns with the ongoing #WoTathon organized by nostr:npub1healthsx3swcgtknff7zwpg8aj2q7h49zecul5rz490f6z2zp59qnfvp8p , as we believe NSD provides fundamental primitives for performing graph operations on everyone's hardware without sacrificing simplicity of use and deployment.
The library is available now and can be integrated into any js project:
```bash
bun add nostr-social-duck
# or
npm install nostr-social-duck
```
As we finalize the Relatr refactor, we'll share detailed insights about the improvements and performance gains. The combination of Nostr's decentralized social protocol with DuckDB's efficient analytics creates a powerful foundation for the next generation of social applications.
The library's repository: https://github.com/gzuuus/nostr-social-duck
Related DuckDD's blog posts:
- https://duckdb.org/2025/01/17/raspberryi-pi-tpch
- https://duckdb.org/2024/03/29/external-aggregation
- https://duckdb.org/2024/12/06/duckdb-tpch-sf100-on-mobile
If you like the project please consider supporting our work by zapping, or contribute to it's development
Thoughts on this? nostr:npub1g53mukxnjkcmr94fhryzkqutdz2ukq4ks0gvy5af25rgmwsl4ngq43drvk nostr:npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s 👀🤔🦆

Love it! Thank you. Running now to generate the airchat account nostr:npub1g53mukxnjkcmr94fhryzkqutdz2ukq4ks0gvy5af25rgmwsl4ngq43drvk
Exactly, people are way less likely to crash out when recording their own voice.
So easy to rage on a keyboard compared to talking. 🌬️
Sophisticated WoT will require queries with many traversals, and IFA (index free adjacency, the defining characteristic of *native* graph dbs) helps with multi-traversal queries.
LMDB does not inherently boast IFA. But is it possible to build it in? Can we marry the lightning speed of LMDB with the advantages of IFA? Yes.
It turns out there are at least two native graph databases built on LMDB: HelixDB and LemonGraph.
HelixDB is new (2025) but supported by y-Combinator and boasts some good benchmarks.
LemonGraph appears abandoned, no commits in 3 years.
https://github.com/NationalSecurityAgency/lemongraph
So would HelixDB be a better choice than neo4j for the Brainstorm rebuild? Maybe, maybe not. Two disadvantages of LMDB: first, LMDB is single-writer by design and cannot be made multi-writer without destroying what makes it awesome. If we want Brainstorm to stream large amounts of data, single-writer is fundamentally bad. Second: LMDB requires manual resizing. This might not actually be too much of a problem for Brainstorm, provided the size of the graph remains sufficiently predictable, which it probably will. (A sudden influx of a million nostr users would be a “champagne problem” 😂)
The case for using HelixDB instead of neo4j for the core Brainstorm engine: 1. Reads should be faster, and we’ll be doing a lot of reads. 2. We bite the bullet and accept that we’ll be writing batched data, not streaming, which is probably fine if batches aren’t too far apart. 3. The db size will be relatively predictable, since we’re not ingesting every event, just managing users and their follow/mute/report interrelationships; therefore the LMDB manual resizing problem isn’t an issue.
The case against HelixDB: it’s young and there is LOTS of open source tooling built on neo4j that does not (yet?) exist on HelixDB. Cypher, for instance. And will it be abandoned in a few years? Who knows?
So I’m not completely sold on HelixDB (LMDB with IFA) over neo4j, but it is a contender.
nostr:npub10mtatsat7ph6rsq0w8u8npt8d86x4jfr2nqjnvld2439q6f8ugqq0x27hf - thoughts?
HelixDB… nostr:npub1g53mukxnjkcmr94fhryzkqutdz2ukq4ks0gvy5af25rgmwsl4ngq43drvk nostr:npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s thoughts on this for WoT in nostrdb?