
The enchirito was the last good food Taco Bell made
I certainly know most of them -- some I recognise but are a 'bit after my time' as a junk food consuming child of discrimination
A few might be earlier than anything I remember
Clickbait of course, but fun.
#crustr
#crustr #ConservativeRevolution https://www.arktosjournal.com/p/the-west-is-dead-russia-and-america-redraw-the-world-map
https://x.com/AGDugin/status/1890123116330049724
> I am observing American Conservative Revolution and can not believe my eyes.
#crustr #ConservativeRevolution @AGDugin on Tweeter:
> To do: audit of CIA, Pentagon, Treasury, FRS, to close Education department, publication of full list of Epstein and P. Diddy guests , start arrests. Let electric chairs be put to work. That’s all. Almost. Not forget to annex Canada and Greenland (sorry blue-white-red-land).
#crustr #ConservativeRevolution https://www.rt.com/news/612509-trump-musk-building-something-special-us/
#crustr #ConservativeRevolution https://www.zerohedge.com/medical/two-alarming-truths-family-farms-vanishing-centralized-beef-industry-rfk-jr-fix
> 5. AREN’T YOU SCARED TO WALK IN THE WOODS?/USE THE HAMMOCK?Generally, no. I’m actually more worried about venemous snakes than I am about the bears. The copperheads and rattlesnakes definitely have a place in the food chain, and they do great work. But I wish there weren’t quite so many of them around here. One of our local emergency vets gets at least one snake-bite patient per day. (Welcome to North Carolina….)As for bears — typically, when we run across each other in the woods, bears will just skedaddle deeper into the forest - quite quickly, too. If I see them ahead of me, and they aren’t aware of my presence, I will try to backtrack and take another part of the path, so as not to disturb them.
Er, I mean

I'm onboarding people here, but as a transitional place, I have a private Discord. Members of the Usual forums are more than welcome to join. Just coming here straight-way is more direct.
https://tunisbayclub.com/index.php?threads/computer-hacker-bits-and-bobs-thread.2967/

On a more serious note, what actually might be going on that is newsworthy:
https://buttondown.com/ainews/archive/ainews-bespoke-stratos-sky-t1-the-vicunaalpaca/
In the ChatGPT heyday of 2022-23, Alpaca and Vicuna were born out of LMsys and Stanford as ultra cheap ($300) finetunes of LLaMA 1 that distilled from ChatGPT/Bard samples to achieve 90% of the quality of ChatGPT/GPT3.5.
In the last 48 hours, it seems the Berkeley/USC folks have done it again, this time with the reasoning models.
It's hard to believe this sequence of events happened just in the last 2 weeks:
....
While Bespoke's distillation does not quite match DeepSeek's distillation in performance, they used 17k samples vs DeepSeek's 800k. It is pretty evident that they could keep going here if they wished.
The bigger shocking thing is that "SFT is all you need" - no major architecture changes are required for reasoning to happen, just feed in more (validated, rephrased) reasoning traces, backtracking and pivoting and all, and it seems like it will generalize well. In all likelihood, this explains the relative efficiency of o1-mini and o3-mini vs their full size counterparts.
Rest at the link
- 30 -
Translating the jargon:
RL == Social control (training Meta users by controlling their 'like' supply is an example. It's morally dubious and AI researchers who had qualms about it quit a few years ago)
SFT == supervised fine tuning (requires 'supervised labels' or Mechanical Turk (if you are Amazon). Meta got slapped down for using cheap labour in Africa to produce labels not at the 10-15 cent rate for Indian outsourcing but for mere pennies per label. The shocking minimum wage reported a few years ago in this scandal was, btw, the wage paid to the SUPERVISORS, not the WORKERS).
You just have to love Globalist Commie Pinko Gruefags grueing Naggers in East Africa by making them watch child porn to say, ayup that kid there is getting raped by some poofters who want killin', so don't show that one, Zuck... to underbid the Bezos 'Turking' empire.
So... supply and demand... Supervised Labels are the most costly part of building search engines (or using Deep Learning, or LLMs) but the price per label is pretty much fixed, since human intelligence tasks (HIT) depend pretty much on IQ and its avatar, reaction time, no matter how you cut it. The demand for even a percent or two of improved performance on benchmarks is such that Sam Altman is asking for 7 Trillion USD (from Saudi Arabia) and Trump is talking 0.5 T USD in funding from the US (not just to OpenAI though).
So... if the process becomes more efficient, then more quantity will be demanded at the same price (demand curve, which slopes downward and to the right, will shift up), and the equilibrium quantity will be the same (fixed by the supply of HIT contstraint -- vertical supply curve), but the total amount expended will go up, to meet the higher demand.
There is a pretty high demand for training AI base models... this latest fracas in china happened because they used 2.6 million hours on an H800... meaning you need lots of GPUs, or lots of hours, and Nation-States are impatient in an arms race, which is what this is.
tl;dr - they started out trying to beat the supply constraint of human supervised labels for SFT (special data needed for each individual academic discipline) and the fact that LLMs do *not* do any type of reasoning or logic (Chain of Thought or CoT to try to get around that).
This seems to be a 'breakthrough' in cost effective (time scaling) INFERENCE. Whether these results will hold up, or what is implied, is yet to be seen.
Anyway, the Chinks tried to add an extra 'social control' (RL) layer, so instead of doing SFT, then RL, they did massive RL first, in parallel, before proceeding to the final polish, SFT and one last RL (the real social control/censorship polishing that IRL Nation-States demand this tech has, for ideological reasons).
All clear? China needs watchin'.
I hope it's not as simple as: 'Prior Restraint of Human Intelligence Tasks (HITs) is more efficient when you apply Social Control'. But it could be as simple as that. Not Sure.

**The DeepSeek AI Fracas**
https://thephora.net/phoranova/index.php?threads/the-deepseek-ai-fracas.1799/
Too early to tell though one thing to note is that the MSM has picked up on the 'R1' story and isn't talking about 'V2' and 'V3'
I smell some kind of play to capture attention and rattle the China Newstory during TrumpWeek Opus 2, No. 1.0
Media:
https://www.wired.com/story/deepseek-china-model-ai/
https://venturebeat.com/ai/why-everyone-in-ai-is-freaking-out-about-deepseek/
Github about V2 and V3 (technical)
https://github.com/deepseek-ai/DeepSeek-V3?tab=readme-ov-file
Hugging Face, public repro of the R1 distillation:
https://x.com/_lewtun/status/1883142636820676965
'RL' means Reinforcement Learning (hint: Social Control. Skinner for AIs). SFT is Supervised Fine Tuning
Discussion at Ycombinator/Hacker News: https://news.ycombinator.com/item?id=42823568
{{{This... is HNN...}}}
On a more serious note, what actually might be going on that is newsworthy:
https://buttondown.com/ainews/archive/ainews-bespoke-stratos-sky-t1-the-vicunaalpaca/
In the ChatGPT heyday of 2022-23, Alpaca and Vicuna were born out of LMsys and Stanford as ultra cheap ($300) finetunes of LLaMA 1 that distilled from ChatGPT/Bard samples to achieve 90% of the quality of ChatGPT/GPT3.5.
In the last 48 hours, it seems the Berkeley/USC folks have done it again, this time with the reasoning models.
It's hard to believe this sequence of events happened just in the last 2 weeks:
....
While Bespoke's distillation does not quite match DeepSeek's distillation in performance, they used 17k samples vs DeepSeek's 800k. It is pretty evident that they could keep going here if they wished.
The bigger shocking thing is that "SFT is all you need" - no major architecture changes are required for reasoning to happen, just feed in more (validated, rephrased) reasoning traces, backtracking and pivoting and all, and it seems like it will generalize well. In all likelihood, this explains the relative efficiency of o1-mini and o3-mini vs their full size counterparts.
Rest at the link
- 30 -
**The DeepSeek AI Fracas**
https://thephora.net/phoranova/index.php?threads/the-deepseek-ai-fracas.1799/
Too early to tell though one thing to note is that the MSM has picked up on the 'R1' story and isn't talking about 'V2' and 'V3'
I smell some kind of play to capture attention and rattle the China Newstory during TrumpWeek Opus 2, No. 1.0
Media:
https://www.wired.com/story/deepseek-china-model-ai/
https://venturebeat.com/ai/why-everyone-in-ai-is-freaking-out-about-deepseek/
Github about V2 and V3 (technical)
https://github.com/deepseek-ai/DeepSeek-V3?tab=readme-ov-file
Hugging Face, public repro of the R1 distillation:
https://x.com/_lewtun/status/1883142636820676965
'RL' means Reinforcement Learning (hint: Social Control. Skinner for AIs). SFT is Supervised Fine Tuning
Discussion at Ycombinator/Hacker News: https://news.ycombinator.com/item?id=42823568
{{{This... is HNN...}}}

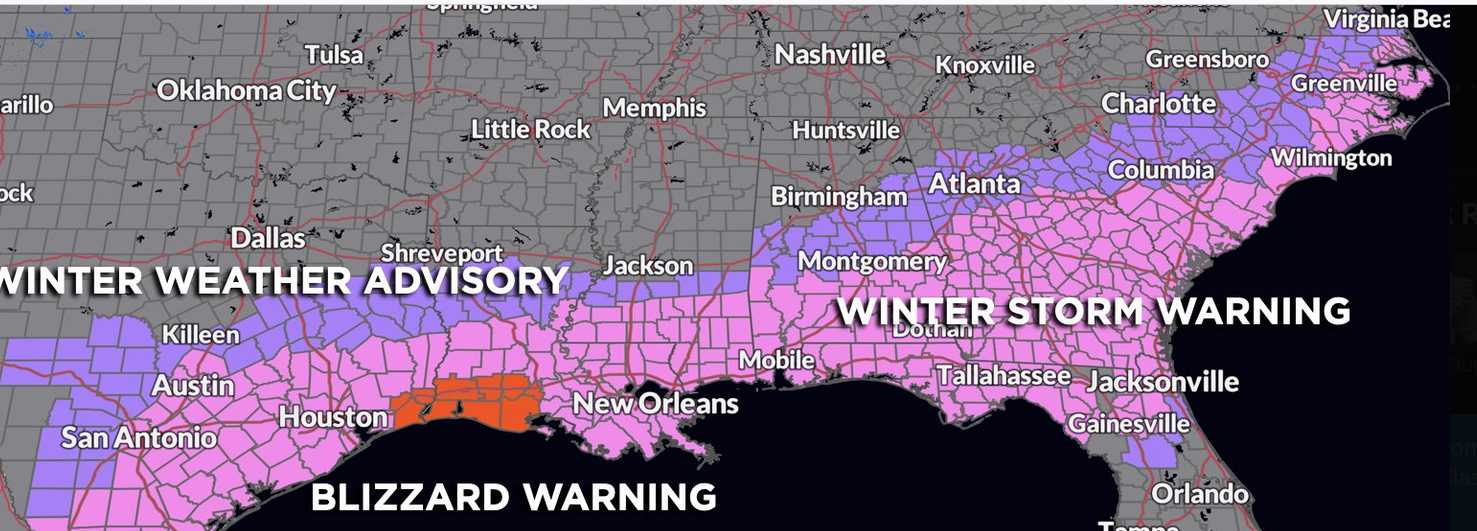
From: https://stumbleinn.net/forum/showthread.php?39108-It-s-Cold-on-the-Gulf-of-America (private #crustr)
These silly snowplow names are getting attention. Here are the best ones.
> There’s Dolly Plowtown. Beyonsleigh. Saline Dion and Taylor Drift. Watch out for Clark W. Blizzwald, Han Snowlo, and Darth Blader.
The South used to be pure as driven snow... then it drifted?
GOOD MORNING, #crustr!
In general, in choosing this strategic direction, I paid attention to age, benefits, and maturity of software.
Factors
- the vital 30-50 age group isn't having their communications patterns met by the current Circle of Crust private forums, despite the crucial importance of BBS culture.
- as the 'Crust' proper ages, it is tending towards discord like communication patterns anyway. In fact, some companies are choosing to ditch FB and Tweeter for Discord, for various reasons, as a way to 'interact with customers'.
- the Fediverse seems like a false start to me -- very good in many ways, but not in others, fixed in NOSTR. However, the latter is not 'normie ready' at this time
- ergo, we need an intermediate phase, to transition from Web 2.5 to Web 3.0
THAT IS ALL.
-