
If you believed this actually works you would have been caching the entire DNS in your host.txt file, the original way people did DNS until they realized they need a structured network... but you know it doesnt work so you don't.
This a misunderstanding about DHTs.
1. You don't need to run a node, you can ask for data in a client mode, just go to Pkarr repo and run the examples, start the process make the query close the process, in and out less than the time to open an average Web page.
2. No one said don't use relays to cache data from many people's queries, no one said don't gossip and cache long term on top... what we are saying is; we need a source of truth that scales and we can fallback to when data is not available in your private cache that you got from your friend on a USB stick.
First; DNS currently is not used by most people, let alone bots.
Secondly It doesnt matter what are you willing to download, the question is how on earth am I supposed to know that you have the data I am looking for?
Thirdl, if your solution is " always download and horde everything that anyone publishes" then I personally and many more will start spamming the hell out of you until most nodes give up and churn, just to troll or to use you as a free storage system.
And that is before getting to the freshness of data.
My point is, claiming that you can have a full replication of open data with redundancy is just false, you either have to sacrifice redundancy (centralisation) or sacrifice full replication or sacrifice openess (make it paid like bitcoin).
And as soon as full replication fails, you are back to; who has the data i am looking for? I have a URL, where is the server, the only way to do this reliably is structured networks, not gossip.
I mean, Nostr is very small, and very centralised (most people read and write from and to small set of servers) and STILL full replication is not the case, so unresolvable links are common.
And this is the best case (the social media), where lazy gossip is natural, try doing this for cold queries like curl
What do you see in the future that makes this better not worse?
Lightning is literally a network of mutually trusting nodes, directly or indirectly through a payment channel.
It is not a gossip network trying to store and retrieve ever growing set of data reliably and performantly.
I want to remind you that I suggested RBSR paper to Hoytech and helped with Negentropy, but it doesn't work for what you want to use it for. It works for passively replicating data you are interested in, it doesn't magically make all the data available to everyone, and if the data is jot available to everyone, then you again have to deal with the question of ; how to find who has the subset i am looking for in less than 500ms
The answers we know of are;
1. A structured network (DNS/DHT)
2. Small set of servers (like ten popular relays)
If you are happy with (2), fine, but then you have to explain what incentives do they have to serve the entire web (costs a lot).
But what you can't do is claim that you can either have full replication of an ever growing data across thousands or millions of nodes, OR claim that you can have partial replication across 1000s of unstructured nodes and have fast queries.
At least not with extraordinary proof. So maybe start building and let's poke at it and see what happens. Or run a simulation or something.
Bittorrent isn't at all what you are describing, when. Peers are gossiping they are not sharing an ever growing dataset, it is a static file, and if it was a changing data set they would necessarily be discarding portions of it because they don't have infinite storage. In fact most seeders Immediately delete the static data as soon as they are done with it.
You can try to slow down the data growth as much as you want, but the best you can do is make it as expensive as a bitcoin transaction and make it take half an hour to hashcash an update, but ignoring the awful UX of that, the data still grows, forever.
How many nodes do you expect dedicating 100 gigabytes for that? Definitely not millions or thousands... definitely not as many as bitcoin nodes since it is not as profitable or necessary to store the full ever growing set.
And then these few nodes have to serve the entire Internet, and they become easier to control or attack because they are few.
You will never be able to have the full dataset, you will have to discard data, and the moment you start doing that, you will realise that people trying to read need to find out who has the parts they need, and they can't because there is no structure. So they will have to ask everyone, and that is exactly what a DHT is meant to make scalable; how to ask log20(n) nodes instead of n nodes.
Anyways, just build it, and see if you can survive spam without degenerating into a handful of nodes like an abandoned Bittorrent infohash.
Please tag me when you build the system that you think is simpler than a DHT, so i can poke at it. For now what I have is DHTs that work in theory and in practice. I claim that gossip persistent replication will always degenerate to centralisation, and have long list of historical case studies, and nothing would make more excited than trying to break another attempt, and failing.
Bittorrent had 15 years to develop a system where the gossip part can't be spammed/bused and where sharing data is fair, and nothing came up better than good old trackers.
My point is, the only system we know of where gossip works at scale for persistent data is bitcoin, and that is because you have to pay fees to gatekeepers who themselves have to pay in a verifiable scarce resource.
And it seems you are reinventing that by thinking in the direction of hashcash, where a proof of work entitles you to store your data.
The problem is, hash cash was already invented to solve the centralisation of email by countering spam, and it failed miserably, and will fail again every time, I bet.

And the blocks are not even full, and everyone is using a custodial LN wallets.
Massive lists are cheap to store and cheap to search through. And the somehow is a question of ownership, we know how to make collaborative lists managed by owners/moderators.
I don't think there is any evidence that any leadership could have done better, certainly I wouldn't, and no one here would have, not sure who do you have in mind who could have done a better job.
Got it, this is usual gossip vs DHT question.
I think you are underestimating how vulnerable to spam this gossip network will be, and how expensive it will be.
There is an inverse relationship between cost of nodes and their decentralisability, and I claim that in a system with no fees for creating new inputs, the only stable configuration is a consortium of small mutually trusting servers, basically like Email.
But of course if that is not convincing, we can always try things in practice.
I agreed with most of this until the end, the question is how often are you going to make a query to something that you haven't cached before. I call this the cold lookup.
And the answer to that is the vast majority of the time for two reasons;
1. There are more URLs on the Web and more endpoints than you can cache, and if you want to replace ICANN DNS, and not just contact list in a social app, then you should expect that most URLs are seen for the first time or it was evicted from your limited cache.
2. You want to support stateless clients, so caching at relays is much more reliable than expecting every client to start with it's own equivalent of host.txt of the entire web
Again, we already know what works for the general purpose, and it is not local host.txt.
But I am not saying you shouldn't use local caches if you can, you should, and Pkarr encourages that, but it is just one layer of caching, and without the falling back to the DHT, the UX really doesn't work, you can't take a step backwards from the status quo, especially when you are already asking users to do the hard thing of managing their own keys, you can't add to that URLs that have a 10% chance of working and "depends".
Is replacing DNS (structured network) with manual gossip a step forward or backward?
Mainline DHT has millions of nodes, so for any given moment in time there is a capacity for billions of small packets.
When you introduce a caching layer (relays) on top, you get the structured (yet flatter) hierarchy of DNS, where the DHT is the alternative to root servers.
You combine that with the natural semantics of DNS, especially TTL, and these relays now can know when to check the DHT again.
Then you only need the DHT to contain your data only often enough for relays to pick it up.
It is not about efficency or correctness, it is about the UX and DX and reliability of the system... remeber that DNS started with manual gossip of host.txt contents... this didn't scale, why try it again?
Worst case scenario that just makes centralised mining pools even more profitable vs miners that are only getting transactions from the mempool.
Best case scenario, another gossip network emerges, with simple enough code base that miners don't mind running in parallel to Bitcoin Core to hear about non standard transactions. Even if they don't trust it they can firewall it one way or another.
If people keep pretending the mempool is a gatekeeper, people will start submitting transactions to mining pools directly like popular Nostr relays... is that how you keep bitcoin mining permissionless and decentralised?
Bluesky metrics are steadily declining, and that is the network that has the best chance of going mainstream.
It is time to stop caring about global feeds and just make our small-worlds web better and more sovereign and be happy with that.
You can't fight physics, all centralised social media will have to deal with this, and I don't think you can make a non-centralised social media, unless you redefine social media to; chatt apps that feel like twitter but have the same reach as a telegram group.

OP_RISCV
So Bluesky has just banned some guy exclusively on Turkey only because the Turkish government asked.
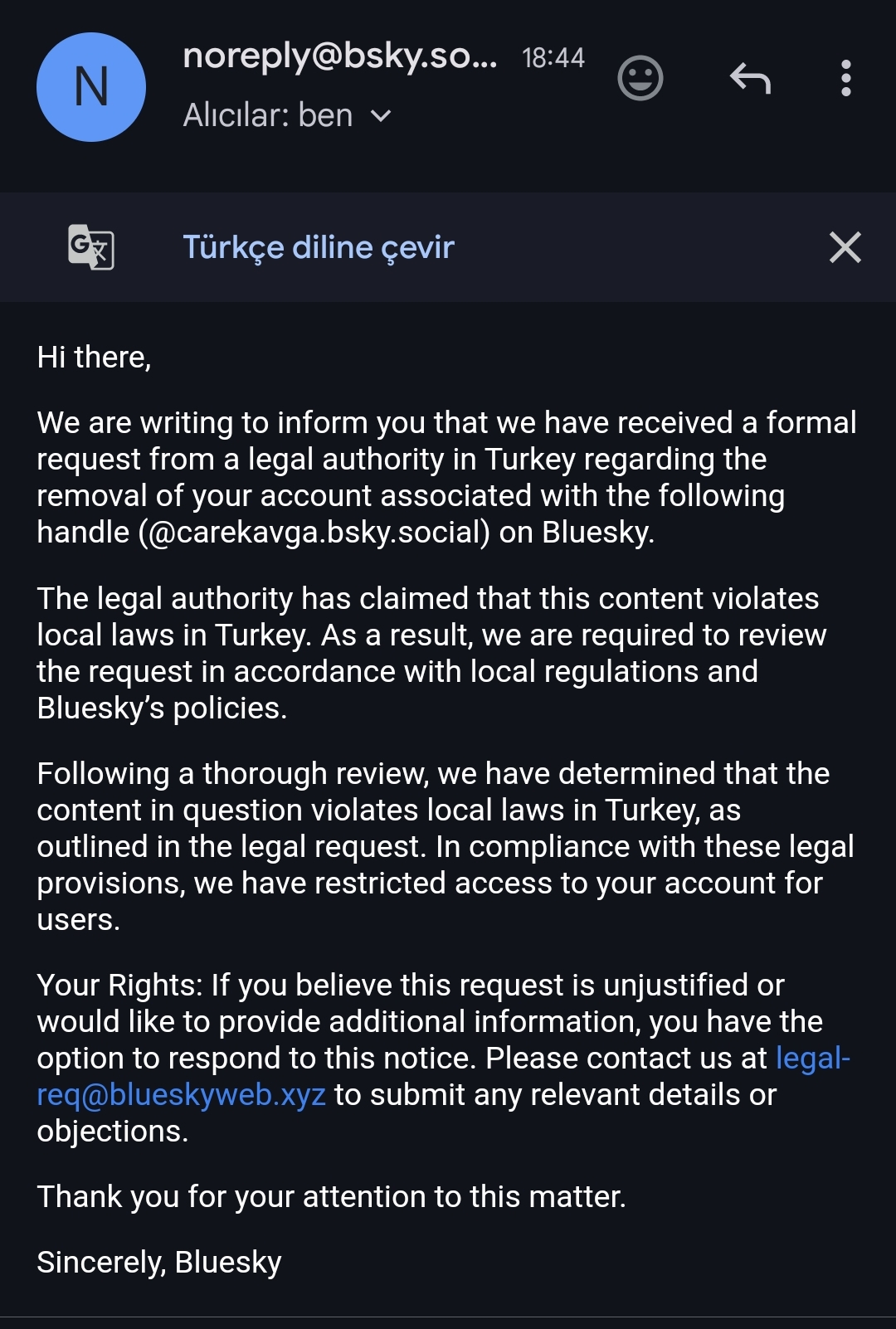
(from https://x.com/aliskorkut/status/1912191854939943362, this is the profile: https://bsky.app/profile/carekavga.bsky.social)
This can and will (if worth it at all) happen to any Pubky indexers or Nostr relays that capture majority of eye balls. And when they comply, because they must, it will be effectively the same as shadow banning.
Play search engine games, win censorship prize.
If you don't want to deal with censorship, don't get big, and don't work on problems that requires big servers to solve them, or build a blockchain and make each post cost $20.
There sincerely no third options.
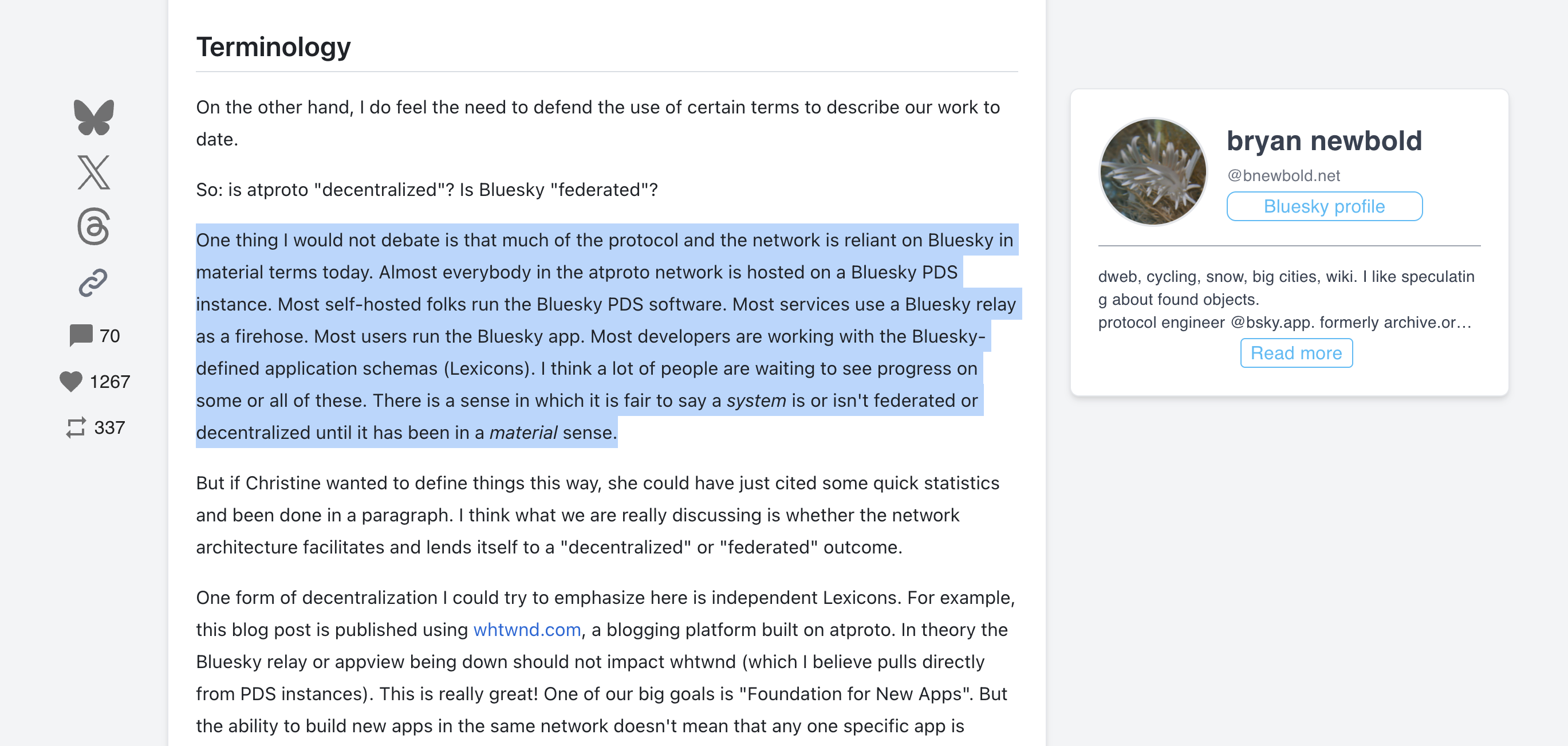
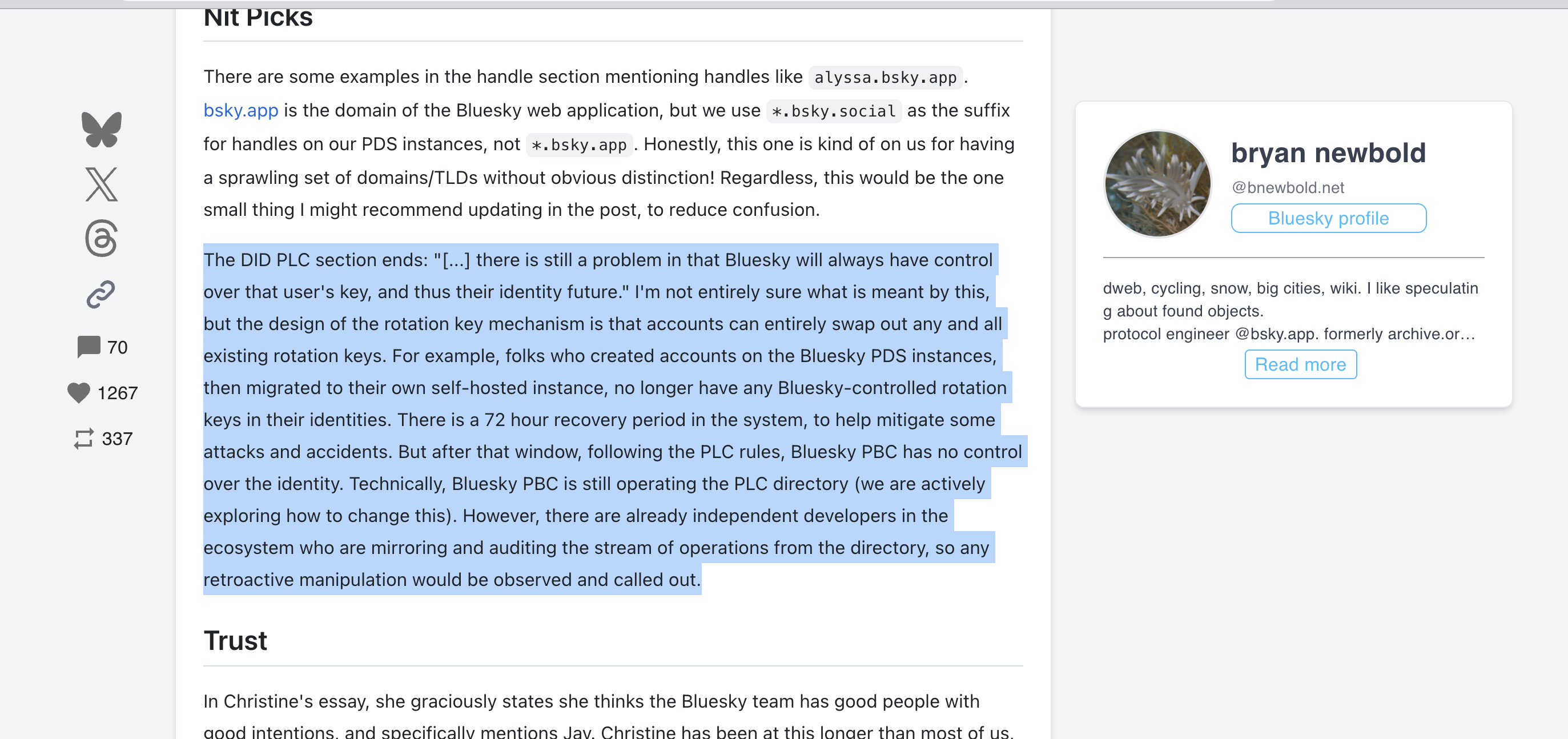
You literally posted him lying by ommission, he is pretending that people Mirroring the centralised directory means anything different from just a TLD. That is a LIE. If you sit down and analyse it you should be able to see why this key rotation and DID is just a circus without a Blockchain like Bitcoin.
But the real issue here is, no matter what I say, it won't matter, because everyone decided to believe this bullshit no matter what and pretend that the nice people because they are nice achieved the impossible.
Ok fine.
I have to admit, every time I see a screenshot or link from Mastodon I get envious of the quality of people and conversations there.
This can very well be a selection bias, but I might cave in and create a Mastodon account.
I just wish Mastodon was using Pkarr, so I neither have to setup a server nor worry about who is the first server I sign up to.
Matrix we looked at but Nostr events and relays are about as complicated as we want things to get, and this is also more of a Kind1 play. This https://bettermode.com/ is an example of one we were asked to pitch against the other week.
Our pitch is if you're going to be brave, pass over the other guy and take things in house, then you're going to want the most dead simple thing possible. Nostr is pretty dead simple.
The reason to stick with Nostr is getting grants from Nostr enthusiasts... but if you need that more than flexibility to address your market, then you are doomed anyways in my opinion.