一时的军事行动再成功,并不能保障国家利益和安全的真正贯彻,这与军事策略和行动的高明本身并不矛盾。这个世界说复杂太复杂,各种利益勾连各种勾心斗角,但说简单也简单:站在历史的层面来看,真正的国家利益和安全的长期保障,还是来自于超越军事层面的更高的力量,比如经济、文化和制度,称之为“大道”也不为过。
因为真正能改变历史格局和局势的,一定是长期的趋势变化而不是短期的机会主义窗口,而贯穿几十年甚至数百年的综合实力增长且保持基本稳定的,背后一定是相对竞争对手而言更发达的经济,文化和制度的保障。
CES 2026 上黄仁勋发布 Rubin 架构,官方说法是「算力提升 5 倍、推理成本降到 1/10」。但对投资者来说,真正重要的不是参数本身,而是三个问题:成本到底省在了哪里?为什么算力更强却反而不用水冷?以及 Rubin 到底是不是在重新定义“推理硬件”这件事。
先说结论:Rubin 并不只是新一代 GPU,它更接近一台“数据中心级、即开即用的推理机器(Inference Appliance)”。这里的“即用”,不是消费级插电即跑,而是对企业和云厂商而言:买回来上机架、接电接网,就能直接交付稳定、可预期的推理吞吐,而不是一堆还需要长期调优的算力潜力。
为什么推理成本能降到 1/10?关键不在单点技术突破,而在三层效率叠加。
第一层,是有效算力利用率的系统性提升。
过去 GPU 在推理场景下面临一个长期问题:理论算力很高,但真正用上的比例很低,很多时候只有 20–30%。这是通用 GPU 架构的代价——调度复杂、执行路径不确定、缓存命中率不可控。Rubin 的设计明显向 ASIC 思想靠拢,把推理当作第一优先级,通过减少运行时不确定性、强化编译期执行路径,把算力利用率显著拉高。只要“可用算力 / 理论算力”这个比值翻倍,所谓“5 倍性能提升”在工程上就完全站得住。
第二层,是单位能耗下吞吐能力的提升。
推理本身比训练稳定得多,再叠加低精度计算、固定算子路径和更平滑的功耗曲线,同样的电力可以完成更多 token 的推理。这一点非常关键:推理成本的核心并不是单卡功耗,而是“每度电能完成多少有效推理任务”。当这个指标大幅改善,能源成本自然被摊薄。Rubin吸收了大量ASIC的思想,Rubin 并没有变成像比特币矿机那样只能算一个算法的 ASIC,但它在处理 Transformer 和类似架构时,其数据路径变得极其“直连”。它减少了大量为了兼容性而存在的冗余电路,将晶体管全部堆在算力核心和超宽带宽上。过去 GPU 推理像是在繁忙的十字路口调度随机车流,由于长尾延迟(Tail Latency)存在,系统必须预留大量冗余;而 Rubin 通过 ASIC 化的确定性调度,把推理变成了一条‘真空管道’,彻底消灭了算力闲置。
第三层,是系统级成本的下降。
Rubin 走的是明确的“整机售卖”路线,这一点往往被低估。整机意味着 NVIDIA 不再只卖芯片,而是深度介入服务器结构、散热设计、互联方式和运维边界。本质上,它交付的是一个完成度极高的推理节点,而不是一堆需要客户自行拼装和长期调优的硬件组件。这直接压缩了运维、人力和基础设施成本,也是推理总成本下降的重要组成部分。
这也解释了另一个常被误解的问题:为什么算力更强,却反而“不用水冷”?
不用水冷并不意味着功耗低,而是意味着热密度和功耗曲线更可控。训练场景下功耗波动极大,峰值频繁触顶,水冷几乎是刚需;而 Rubin 面向推理,负载稳定,再加上更偏 ASIC 化的执行模型,显著减少功耗尖峰,使得风冷 + 整机级热设计在工程上变得可行。这不是“违背物理规律”,而是系统效率提升后的自然结果。全球 80% 的存量机房并非为液冷设计,Rubin 对风冷的回归,意味着 NVIDIA 绕过了昂贵的新型液冷机房建设周期,直接吞噬存量通用机房的货架空间。这是一次为了快速出货、快速占领推理市场**而做的极其精明的工程妥协。
从竞争格局看,这一步对 TPU 的意义在于:NVIDIA 正在把 TPU 的优势,复制进自己的生态。TPU 的核心竞争力从来不是单点算力,而是推理效率和成本控制。Rubin 并不是要正面“消灭 TPU”,但它会明显压缩 TPU 在推理性价比上的独占空间,尤其是对不在 Google 生态里的客户而言,Rubin 提供了一个无需迁移软件栈的现实选择。
那对光模块意味着什么?
传统的TPU时代,光模块互联大量TPU,价值巨大,但是Rubin这种高度集成、更多互联被内化,确实会让单位算力对应的外部光模块数量下降,尤其是在推理集群中。但这并不等于需求消失,而是需求结构变化:从“拼数量”,转向“拼高速、低延迟和系统适配能力”。这是产业链逻辑的转移,而不是简单的利空。
最后一个绕不开的问题:大厂会不会把 H100 换掉?比如 xAI。
答案很清楚:不会“一刀切替换”,但新增推理算力的采购,会明显向 Rubin 倾斜。H100、Blackwell 仍然是训练侧的核心资产,不可能被快速淘汰;但在推理侧,尤其是新建集群、扩容和成本敏感场景,Rubin 作为“即用型推理机器”,会成为更优解。未来的数据中心,很可能出现更清晰的分工:训练用训练卡,推理用推理系统,而不再是一张卡试图覆盖所有场景。
从更宏观的角度看,Rubin 的意义在于一件事:
AI 正在从“算力军备竞赛”,进入“推理效率定价”的新阶段。当推理被系统性地做成一种标准化、可交付、可定价的能力,AI 才真正具备向更广泛行业和应用扩散的基础。这一步,可能比单纯算力翻几倍,更重要。
一大早被网友来信塞满了,都在问内存还能不能上、硬盘为什么涨、Baba 为何失血。Rubin 架构的诞生,不只是一场技术迭代,它正在重写 AI 投资的底层定价逻辑。
1. 为什么“内存”是全场最硬的利好? Rubin 带来的推理成本 1/10 降幅,核心就在于对**“确定性计算”的追求。这意味着算力不再空转,单位时间内对数据的搬运频率呈几何倍数增长。Rubin 吸收了 Groq 的近存计算思想,让 HBM4 甚至更先进的存算一体技术变成了“算力心脏”的血液。算力是引擎,内存就是油管,油管必须加粗再加粗。至于硬盘(SSD)**,作为二级缓存和冷数据底座,受内存价格普涨的成本传导和 Physical AI 海量数据存储的需求叠加,补涨是必然的物理反馈。
2. 为什么光模块和 TPU 感受到了冷意?
光模块: NVIDIA 正在通过 Rubin 强推“整机一体化”,通过内部硅光和铜缆互联,把原本属于外购光模块的利润“内敛”进了自己的机柜。推理侧的互联模式从“皮肤”转入“骨架”,逻辑变了,溢价自然收缩。
TPU: 谷歌的护城河一直是推理性价比,而 Rubin 通过 ASIC 化的手段,把 NVIDIA 这种通用霸主变成了“推土机级的推理怪兽”,直接杀进了 TPU 的价格腹地。
3. 为什么 Baba 还在跌? 资本是极其势利的,它永远在追逐当下最性感的“增量资产”。目前市场在深度博弈 Rubin 带来的物理层革命(能源、半导体、HBM),这些是“热钱中心”。Baba 业务基本面虽然稳,但在这一轮**“硬核物理约束”**的概念中缺乏爆发性的对冲点。在存量博弈的市场,热点吸金必然导致蓝筹失血,这在投资上叫“机会成本的挤压”。
4. 错过行情,怎么上车? 内存依然有空间,具体操作比较复杂,每个人都有自己观点,我没法直接指导,我自己的策略就是两个,买入正股,同时补一个卖call,防止回撤;或者卖出put,同时补一个put,节约保证金,具体股东大会会详细讲解。。
CES 2026 上黄仁勋发布 Rubin 架构,官方说法是「算力提升 5 倍、推理成本降到 1/10」。但对投资者来说,真正重要的不是参数本身,而是三个问题:成本到底省在了哪里?为什么算力更强却反而不用水冷?以及 Rubin 到底是不是在重新定义“推理硬件”这件事。
先说结论:Rubin 并不只是新一代 GPU,它更接近一台“数据中心级、即开即用的推理机器(Inference Appliance)”。这里的“即用”,不是消费级插电即跑,而是对企业和云厂商而言:买回来上机架、接电接网,就能直接交付稳定、可预期的推理吞吐,而不是一堆还需要长期调优的算力潜力。
为什么推理成本能降到 1/10?关键不在单点技术突破,而在三层效率叠加。
第一层,是有效算力利用率的系统性提升。
过去 GPU 在推理场景下面临一个长期问题:理论算力很高,但真正用上的比例很低,很多时候只有 20–30%。这是通用 GPU 架构的代价——调度复杂、执行路径不确定、缓存命中率不可控。Rubin 的设计明显向 ASIC 思想靠拢,把推理当作第一优先级,通过减少运行时不确定性、强化编译期执行路径,把算力利用率显著拉高。只要“可用算力 / 理论算力”这个比值翻倍,所谓“5 倍性能提升”在工程上就完全站得住。
第二层,是单位能耗下吞吐能力的提升。
推理本身比训练稳定得多,再叠加低精度计算、固定算子路径和更平滑的功耗曲线,同样的电力可以完成更多 token 的推理。这一点非常关键:推理成本的核心并不是单卡功耗,而是“每度电能完成多少有效推理任务”。当这个指标大幅改善,能源成本自然被摊薄。Rubin吸收了大量ASIC的思想,Rubin 并没有变成像比特币矿机那样只能算一个算法的 ASIC,但它在处理 Transformer 和类似架构时,其数据路径变得极其“直连”。它减少了大量为了兼容性而存在的冗余电路,将晶体管全部堆在算力核心和超宽带宽上。过去 GPU 推理像是在繁忙的十字路口调度随机车流,由于长尾延迟(Tail Latency)存在,系统必须预留大量冗余;而 Rubin 通过 ASIC 化的确定性调度,把推理变成了一条‘真空管道’,彻底消灭了算力闲置。
第三层,是系统级成本的下降。
Rubin 走的是明确的“整机售卖”路线,这一点往往被低估。整机意味着 NVIDIA 不再只卖芯片,而是深度介入服务器结构、散热设计、互联方式和运维边界。本质上,它交付的是一个完成度极高的推理节点,而不是一堆需要客户自行拼装和长期调优的硬件组件。这直接压缩了运维、人力和基础设施成本,也是推理总成本下降的重要组成部分。
这也解释了另一个常被误解的问题:为什么算力更强,却反而“不用水冷”?
不用水冷并不意味着功耗低,而是意味着热密度和功耗曲线更可控。训练场景下功耗波动极大,峰值频繁触顶,水冷几乎是刚需;而 Rubin 面向推理,负载稳定,再加上更偏 ASIC 化的执行模型,显著减少功耗尖峰,使得风冷 + 整机级热设计在工程上变得可行。这不是“违背物理规律”,而是系统效率提升后的自然结果。全球 80% 的存量机房并非为液冷设计,Rubin 对风冷的回归,意味着 NVIDIA 绕过了昂贵的新型液冷机房建设周期,直接吞噬存量通用机房的货架空间。这是一次为了快速出货、快速占领推理市场**而做的极其精明的工程妥协。
从竞争格局看,这一步对 TPU 的意义在于:NVIDIA 正在把 TPU 的优势,复制进自己的生态。TPU 的核心竞争力从来不是单点算力,而是推理效率和成本控制。Rubin 并不是要正面“消灭 TPU”,但它会明显压缩 TPU 在推理性价比上的独占空间,尤其是对不在 Google 生态里的客户而言,Rubin 提供了一个无需迁移软件栈的现实选择。
那对光模块意味着什么?
传统的TPU时代,光模块互联大量TPU,价值巨大,但是Rubin这种高度集成、更多互联被内化,确实会让单位算力对应的外部光模块数量下降,尤其是在推理集群中。但这并不等于需求消失,而是需求结构变化:从“拼数量”,转向“拼高速、低延迟和系统适配能力”。这是产业链逻辑的转移,而不是简单的利空。
最后一个绕不开的问题:大厂会不会把 H100 换掉?比如 xAI。
答案很清楚:不会“一刀切替换”,但新增推理算力的采购,会明显向 Rubin 倾斜。H100、Blackwell 仍然是训练侧的核心资产,不可能被快速淘汰;但在推理侧,尤其是新建集群、扩容和成本敏感场景,Rubin 作为“即用型推理机器”,会成为更优解。未来的数据中心,很可能出现更清晰的分工:训练用训练卡,推理用推理系统,而不再是一张卡试图覆盖所有场景。
从更宏观的角度看,Rubin 的意义在于一件事:
AI 正在从“算力军备竞赛”,进入“推理效率定价”的新阶段。当推理被系统性地做成一种标准化、可交付、可定价的能力,AI 才真正具备向更广泛行业和应用扩散的基础。这一步,可能比单纯算力翻几倍,更重要。
一大早被网友来信塞满了,都在问内存还能不能上、硬盘为什么涨、Baba 为何失血。Rubin 架构的诞生,不只是一场技术迭代,它正在重写 AI 投资的底层定价逻辑。
1. 为什么“内存”是全场最硬的利好? Rubin 带来的推理成本 1/10 降幅,核心就在于对**“确定性计算”的追求。这意味着算力不再空转,单位时间内对数据的搬运频率呈几何倍数增长。Rubin 吸收了 Groq 的近存计算思想,让 HBM4 甚至更先进的存算一体技术变成了“算力心脏”的血液。算力是引擎,内存就是油管,油管必须加粗再加粗。至于硬盘(SSD)**,作为二级缓存和冷数据底座,受内存价格普涨的成本传导和 Physical AI 海量数据存储的需求叠加,补涨是必然的物理反馈。
2. 为什么光模块和 TPU 感受到了冷意?
光模块: NVIDIA 正在通过 Rubin 强推“整机一体化”,通过内部硅光和铜缆互联,把原本属于外购光模块的利润“内敛”进了自己的机柜。推理侧的互联模式从“皮肤”转入“骨架”,逻辑变了,溢价自然收缩。
TPU: 谷歌的护城河一直是推理性价比,而 Rubin 通过 ASIC 化的手段,把 NVIDIA 这种通用霸主变成了“推土机级的推理怪兽”,直接杀进了 TPU 的价格腹地。
3. 为什么 Baba 还在跌? 资本是极其势利的,它永远在追逐当下最性感的“增量资产”。目前市场在深度博弈 Rubin 带来的物理层革命(能源、半导体、HBM),这些是“热钱中心”。Baba 业务基本面虽然稳,但在这一轮**“硬核物理约束”**的概念中缺乏爆发性的对冲点。在存量博弈的市场,热点吸金必然导致蓝筹失血,这在投资上叫“机会成本的挤压”。
4. 错过行情,怎么上车? 内存依然有空间,具体操作比较复杂,每个人都有自己观点,我没法直接指导,我自己的策略就是两个,买入正股,同时补一个卖call,防止回撤;或者卖出put,同时补一个put,节约保证金,具体股东大会会详细讲解。。
CES 2026 上黄仁勋发布 Rubin 架构,官方说法是「算力提升 5 倍、推理成本降到 1/10」。但对投资者来说,真正重要的不是参数本身,而是三个问题:成本到底省在了哪里?为什么算力更强却反而不用水冷?以及 Rubin 到底是不是在重新定义“推理硬件”这件事。
先说结论:Rubin 并不只是新一代 GPU,它更接近一台“数据中心级、即开即用的推理机器(Inference Appliance)”。这里的“即用”,不是消费级插电即跑,而是对企业和云厂商而言:买回来上机架、接电接网,就能直接交付稳定、可预期的推理吞吐,而不是一堆还需要长期调优的算力潜力。
为什么推理成本能降到 1/10?关键不在单点技术突破,而在三层效率叠加。
第一层,是有效算力利用率的系统性提升。
过去 GPU 在推理场景下面临一个长期问题:理论算力很高,但真正用上的比例很低,很多时候只有 20–30%。这是通用 GPU 架构的代价——调度复杂、执行路径不确定、缓存命中率不可控。Rubin 的设计明显向 ASIC 思想靠拢,把推理当作第一优先级,通过减少运行时不确定性、强化编译期执行路径,把算力利用率显著拉高。只要“可用算力 / 理论算力”这个比值翻倍,所谓“5 倍性能提升”在工程上就完全站得住。
第二层,是单位能耗下吞吐能力的提升。
推理本身比训练稳定得多,再叠加低精度计算、固定算子路径和更平滑的功耗曲线,同样的电力可以完成更多 token 的推理。这一点非常关键:推理成本的核心并不是单卡功耗,而是“每度电能完成多少有效推理任务”。当这个指标大幅改善,能源成本自然被摊薄。Rubin吸收了大量ASIC的思想,Rubin 并没有变成像比特币矿机那样只能算一个算法的 ASIC,但它在处理 Transformer 和类似架构时,其数据路径变得极其“直连”。它减少了大量为了兼容性而存在的冗余电路,将晶体管全部堆在算力核心和超宽带宽上。过去 GPU 推理像是在繁忙的十字路口调度随机车流,由于长尾延迟(Tail Latency)存在,系统必须预留大量冗余;而 Rubin 通过 ASIC 化的确定性调度,把推理变成了一条‘真空管道’,彻底消灭了算力闲置。
第三层,是系统级成本的下降。
Rubin 走的是明确的“整机售卖”路线,这一点往往被低估。整机意味着 NVIDIA 不再只卖芯片,而是深度介入服务器结构、散热设计、互联方式和运维边界。本质上,它交付的是一个完成度极高的推理节点,而不是一堆需要客户自行拼装和长期调优的硬件组件。这直接压缩了运维、人力和基础设施成本,也是推理总成本下降的重要组成部分。
这也解释了另一个常被误解的问题:为什么算力更强,却反而“不用水冷”?
不用水冷并不意味着功耗低,而是意味着热密度和功耗曲线更可控。训练场景下功耗波动极大,峰值频繁触顶,水冷几乎是刚需;而 Rubin 面向推理,负载稳定,再加上更偏 ASIC 化的执行模型,显著减少功耗尖峰,使得风冷 + 整机级热设计在工程上变得可行。这不是“违背物理规律”,而是系统效率提升后的自然结果。全球 80% 的存量机房并非为液冷设计,Rubin 对风冷的回归,意味着 NVIDIA 绕过了昂贵的新型液冷机房建设周期,直接吞噬存量通用机房的货架空间。这是一次为了快速出货、快速占领推理市场**而做的极其精明的工程妥协。
从竞争格局看,这一步对 TPU 的意义在于:NVIDIA 正在把 TPU 的优势,复制进自己的生态。TPU 的核心竞争力从来不是单点算力,而是推理效率和成本控制。Rubin 并不是要正面“消灭 TPU”,但它会明显压缩 TPU 在推理性价比上的独占空间,尤其是对不在 Google 生态里的客户而言,Rubin 提供了一个无需迁移软件栈的现实选择。
那对光模块意味着什么?
传统的TPU时代,光模块互联大量TPU,价值巨大,但是Rubin这种高度集成、更多互联被内化,确实会让单位算力对应的外部光模块数量下降,尤其是在推理集群中。但这并不等于需求消失,而是需求结构变化:从“拼数量”,转向“拼高速、低延迟和系统适配能力”。这是产业链逻辑的转移,而不是简单的利空。
最后一个绕不开的问题:大厂会不会把 H100 换掉?比如 xAI。
答案很清楚:不会“一刀切替换”,但新增推理算力的采购,会明显向 Rubin 倾斜。H100、Blackwell 仍然是训练侧的核心资产,不可能被快速淘汰;但在推理侧,尤其是新建集群、扩容和成本敏感场景,Rubin 作为“即用型推理机器”,会成为更优解。未来的数据中心,很可能出现更清晰的分工:训练用训练卡,推理用推理系统,而不再是一张卡试图覆盖所有场景。
从更宏观的角度看,Rubin 的意义在于一件事:
AI 正在从“算力军备竞赛”,进入“推理效率定价”的新阶段。当推理被系统性地做成一种标准化、可交付、可定价的能力,AI 才真正具备向更广泛行业和应用扩散的基础。这一步,可能比单纯算力翻几倍,更重要。
CES 2026 上黄仁勋发布 Rubin 架构,官方说法是「算力提升 5 倍、推理成本降到 1/10」。但对投资者来说,真正重要的不是参数本身,而是三个问题:成本到底省在了哪里?为什么算力更强却反而不用水冷?以及 Rubin 到底是不是在重新定义“推理硬件”这件事。
先说结论:Rubin 并不只是新一代 GPU,它更接近一台“数据中心级、即开即用的推理机器(Inference Appliance)”。这里的“即用”,不是消费级插电即跑,而是对企业和云厂商而言:买回来上机架、接电接网,就能直接交付稳定、可预期的推理吞吐,而不是一堆还需要长期调优的算力潜力。
为什么推理成本能降到 1/10?关键不在单点技术突破,而在三层效率叠加。
第一层,是有效算力利用率的系统性提升。
过去 GPU 在推理场景下面临一个长期问题:理论算力很高,但真正用上的比例很低,很多时候只有 20–30%。这是通用 GPU 架构的代价——调度复杂、执行路径不确定、缓存命中率不可控。Rubin 的设计明显向 ASIC 思想靠拢,把推理当作第一优先级,通过减少运行时不确定性、强化编译期执行路径,把算力利用率显著拉高。只要“可用算力 / 理论算力”这个比值翻倍,所谓“5 倍性能提升”在工程上就完全站得住。
第二层,是单位能耗下吞吐能力的提升。
推理本身比训练稳定得多,再叠加低精度计算、固定算子路径和更平滑的功耗曲线,同样的电力可以完成更多 token 的推理。这一点非常关键:推理成本的核心并不是单卡功耗,而是“每度电能完成多少有效推理任务”。当这个指标大幅改善,能源成本自然被摊薄。Rubin吸收了大量ASIC的思想,Rubin 并没有变成像比特币矿机那样只能算一个算法的 ASIC,但它在处理 Transformer 和类似架构时,其数据路径变得极其“直连”。它减少了大量为了兼容性而存在的冗余电路,将晶体管全部堆在算力核心和超宽带宽上。过去 GPU 推理像是在繁忙的十字路口调度随机车流,由于长尾延迟(Tail Latency)存在,系统必须预留大量冗余;而 Rubin 通过 ASIC 化的确定性调度,把推理变成了一条‘真空管道’,彻底消灭了算力闲置。
第三层,是系统级成本的下降。
Rubin 走的是明确的“整机售卖”路线,这一点往往被低估。整机意味着 NVIDIA 不再只卖芯片,而是深度介入服务器结构、散热设计、互联方式和运维边界。本质上,它交付的是一个完成度极高的推理节点,而不是一堆需要客户自行拼装和长期调优的硬件组件。这直接压缩了运维、人力和基础设施成本,也是推理总成本下降的重要组成部分。
这也解释了另一个常被误解的问题:为什么算力更强,却反而“不用水冷”?
不用水冷并不意味着功耗低,而是意味着热密度和功耗曲线更可控。训练场景下功耗波动极大,峰值频繁触顶,水冷几乎是刚需;而 Rubin 面向推理,负载稳定,再加上更偏 ASIC 化的执行模型,显著减少功耗尖峰,使得风冷 + 整机级热设计在工程上变得可行。这不是“违背物理规律”,而是系统效率提升后的自然结果。全球 80% 的存量机房并非为液冷设计,Rubin 对风冷的回归,意味着 NVIDIA 绕过了昂贵的新型液冷机房建设周期,直接吞噬存量通用机房的货架空间。这是一次为了快速出货、快速占领推理市场**而做的极其精明的工程妥协。
从竞争格局看,这一步对 TPU 的意义在于:NVIDIA 正在把 TPU 的优势,复制进自己的生态。TPU 的核心竞争力从来不是单点算力,而是推理效率和成本控制。Rubin 并不是要正面“消灭 TPU”,但它会明显压缩 TPU 在推理性价比上的独占空间,尤其是对不在 Google 生态里的客户而言,Rubin 提供了一个无需迁移软件栈的现实选择。
那对光模块意味着什么?
传统的TPU时代,光模块互联大量TPU,价值巨大,但是Rubin这种高度集成、更多互联被内化,确实会让单位算力对应的外部光模块数量下降,尤其是在推理集群中。但这并不等于需求消失,而是需求结构变化:从“拼数量”,转向“拼高速、低延迟和系统适配能力”。这是产业链逻辑的转移,而不是简单的利空。
最后一个绕不开的问题:大厂会不会把 H100 换掉?比如 xAI。
答案很清楚:不会“一刀切替换”,但新增推理算力的采购,会明显向 Rubin 倾斜。H100、Blackwell 仍然是训练侧的核心资产,不可能被快速淘汰;但在推理侧,尤其是新建集群、扩容和成本敏感场景,Rubin 作为“即用型推理机器”,会成为更优解。未来的数据中心,很可能出现更清晰的分工:训练用训练卡,推理用推理系统,而不再是一张卡试图覆盖所有场景。
从更宏观的角度看,Rubin 的意义在于一件事:
AI 正在从“算力军备竞赛”,进入“推理效率定价”的新阶段。当推理被系统性地做成一种标准化、可交付、可定价的能力,AI 才真正具备向更广泛行业和应用扩散的基础。这一步,可能比单纯算力翻几倍,更重要。
CES 2026 上黄仁勋发布 Rubin 架构,官方说法是「算力提升 5 倍、推理成本降到 1/10」。但对投资者来说,真正重要的不是参数本身,而是三个问题:成本到底省在了哪里?为什么算力更强却反而不用水冷?以及 Rubin 到底是不是在重新定义“推理硬件”这件事。
先说结论:Rubin 并不只是新一代 GPU,它更接近一台“数据中心级、即开即用的推理机器(Inference Appliance)”。这里的“即用”,不是消费级插电即跑,而是对企业和云厂商而言:买回来上机架、接电接网,就能直接交付稳定、可预期的推理吞吐,而不是一堆还需要长期调优的算力潜力。
为什么推理成本能降到 1/10?关键不在单点技术突破,而在三层效率叠加。
第一层,是有效算力利用率的系统性提升。
过去 GPU 在推理场景下面临一个长期问题:理论算力很高,但真正用上的比例很低,很多时候只有 20–30%。这是通用 GPU 架构的代价——调度复杂、执行路径不确定、缓存命中率不可控。Rubin 的设计明显向 ASIC 思想靠拢,把推理当作第一优先级,通过减少运行时不确定性、强化编译期执行路径,把算力利用率显著拉高。只要“可用算力 / 理论算力”这个比值翻倍,所谓“5 倍性能提升”在工程上就完全站得住。
第二层,是单位能耗下吞吐能力的提升。
推理本身比训练稳定得多,再叠加低精度计算、固定算子路径和更平滑的功耗曲线,同样的电力可以完成更多 token 的推理。这一点非常关键:推理成本的核心并不是单卡功耗,而是“每度电能完成多少有效推理任务”。当这个指标大幅改善,能源成本自然被摊薄。Rubin吸收了大量ASIC的思想,Rubin 并没有变成像比特币矿机那样只能算一个算法的 ASIC,但它在处理 Transformer 和类似架构时,其数据路径变得极其“直连”。它减少了大量为了兼容性而存在的冗余电路,将晶体管全部堆在算力核心和超宽带宽上。过去 GPU 推理像是在繁忙的十字路口调度随机车流,由于长尾延迟(Tail Latency)存在,系统必须预留大量冗余;而 Rubin 通过 ASIC 化的确定性调度,把推理变成了一条‘真空管道’,彻底消灭了算力闲置。
第三层,是系统级成本的下降。
Rubin 走的是明确的“整机售卖”路线,这一点往往被低估。整机意味着 NVIDIA 不再只卖芯片,而是深度介入服务器结构、散热设计、互联方式和运维边界。本质上,它交付的是一个完成度极高的推理节点,而不是一堆需要客户自行拼装和长期调优的硬件组件。这直接压缩了运维、人力和基础设施成本,也是推理总成本下降的重要组成部分。
这也解释了另一个常被误解的问题:为什么算力更强,却反而“不用水冷”?
不用水冷并不意味着功耗低,而是意味着热密度和功耗曲线更可控。训练场景下功耗波动极大,峰值频繁触顶,水冷几乎是刚需;而 Rubin 面向推理,负载稳定,再加上更偏 ASIC 化的执行模型,显著减少功耗尖峰,使得风冷 + 整机级热设计在工程上变得可行。这不是“违背物理规律”,而是系统效率提升后的自然结果。全球 80% 的存量机房并非为液冷设计,Rubin 对风冷的回归,意味着 NVIDIA 绕过了昂贵的新型液冷机房建设周期,直接吞噬存量通用机房的货架空间。这是一次为了快速出货、快速占领推理市场**而做的极其精明的工程妥协。
从竞争格局看,这一步对 TPU 的意义在于:NVIDIA 正在把 TPU 的优势,复制进自己的生态。TPU 的核心竞争力从来不是单点算力,而是推理效率和成本控制。Rubin 并不是要正面“消灭 TPU”,但它会明显压缩 TPU 在推理性价比上的独占空间,尤其是对不在 Google 生态里的客户而言,Rubin 提供了一个无需迁移软件栈的现实选择。
那对光模块意味着什么?
传统的TPU时代,光模块互联大量TPU,价值巨大,但是Rubin这种高度集成、更多互联被内化,确实会让单位算力对应的外部光模块数量下降,尤其是在推理集群中。但这并不等于需求消失,而是需求结构变化:从“拼数量”,转向“拼高速、低延迟和系统适配能力”。这是产业链逻辑的转移,而不是简单的利空。
最后一个绕不开的问题:大厂会不会把 H100 换掉?比如 xAI。
答案很清楚:不会“一刀切替换”,但新增推理算力的采购,会明显向 Rubin 倾斜。H100、Blackwell 仍然是训练侧的核心资产,不可能被快速淘汰;但在推理侧,尤其是新建集群、扩容和成本敏感场景,Rubin 作为“即用型推理机器”,会成为更优解。未来的数据中心,很可能出现更清晰的分工:训练用训练卡,推理用推理系统,而不再是一张卡试图覆盖所有场景。
从更宏观的角度看,Rubin 的意义在于一件事:
AI 正在从“算力军备竞赛”,进入“推理效率定价”的新阶段。当推理被系统性地做成一种标准化、可交付、可定价的能力,AI 才真正具备向更广泛行业和应用扩散的基础。这一步,可能比单纯算力翻几倍,更重要。
窃喜202011:我也想收到电话。。。。。
26-1-7 09:52 来自北京
梁斌penny
:案值大才收到电话,案值小都是短线。。。收到电话有什么好啊
26-1-7 09:56 来自江苏
尧舜禹主任司马启
:回复@梁斌penny:段永平收电话嘛,他不是移民了嘛
26-1-7 10:14 来自广东
叶开_____:梁博讲讲什么门槛才会收到电话[允悲]
26-1-7 10:03 来自浙江
梁斌penny
:目测案值要超过500万。。
26-1-7 10:27 来自江苏
麻麻说长长的网名才够囧:回复@梁斌penny:案值[允悲]
26-1-7 16:22 来自江苏
22年被你逃掉了,从23年开始计算,你赚了,总比我这个25年底最后几天收到电话的要强。。
@神棍敌人杰
最终还是收到了税务局的电话。
一大早醒来好多网友来信,错过内存行情,还能不能上车,怎么上车;硬盘怎么也涨了,baba怎么还跌了,我一会写一个长微博来阐述我方观点。。给我点时间啊。
最近同志们给我纷纷上课大熊的情况,拉黑我的不少。。。
@李成东
东哥怎么看小米和大熊年框合作风波?
十五年前就认识大熊和徐洁云了,大熊是派代热门派友(我是论坛运营),徐洁云是第一财经日报记者(我是电商行业分析师)。
大熊最早的影响力是从派代发电商帖起来!这也正常,当时互联网最热门的行业就是电商,且公关战炮火连天!
后来我去了企鹅做战略和投资,大熊去了360做产品,徐洁云去了小米做公关。这是内容从业者,成功华丽转型。作为电商行业专家,当时认识的记者多数转做公关的最多,也有个别成功转型做投资的。比如腾讯科技的赵楠去祥峰投资,因为成功投资了摩拜单车升级为合伙人。还有网易的牛立熊去了经纬,投资了几乎所有教育独角兽(但运气不佳)。做投资的需要运气,我入行的时候嘉程资本李黎(趣店)和弘章资本翁怡诺(蓝月亮,家家悦),也还是媒体从业者,现在应该是最成功的早期消费投资人,还创办了自己的基金。
还认识几个转型做投资的科技媒体记者,但后来也没什么接触了。过去的四五年,风险投资行业也是失业重镇。
东哥怎么评价合作引发粉丝强烈反弹的舆论风波?
对小米来说,水能载舟亦能覆舟。
对大熊来说,争议有流量,日常激怒/羞辱得罪一个群体未必是好事儿。#东哥笔记#
美国以贩毒名义抓捕马杜罗,那干嘛还抓人家夫人呢?这个合法性在哪里呢?罪犯家属不应该天然是罪犯吧,人权标兵怎么看待这个问题的呢?
感觉有点重了,也说明真的是严肃处理了。。//@赏味不足:[流鼻血][流鼻血]//@囧鸽:[哆啦A梦吃惊][哆啦A梦吃惊][哆啦A梦吃惊]//@卢伟冰:转发微博
@小米公司发言人
昨天关于团队与相关KOL接触一事,公司立刻启动了专项调查,有了初步结论,公关部总经理徐洁云当晚就向大家同步决定:相关接触已立即终止,且承诺未来不会合作。
今天,正式调查结果出来,经过管理层讨论,认为该事件严重违背公司原则,也严重伤害米粉朋友们的感情,属于严重违规,按公司制度做出如下处罚:
一、涉事负责经办人员,做辞退处罚。
二、集团副总裁兼CMO许斐和集团公关部总经理徐洁云承担管理失职责任,予以通报批评,扣除2025年相关绩效成绩,并取消2025年度奖金。
“因为米粉,所以小米”,米粉的信任和支持,是小米不断前行的基石。
我们深知,今天小米所有成绩都源于米粉朋友们不离不弃的支持。我们再次道歉,欢迎大家继续监督。
小米公司发言人
2026年1月6日
感觉不是第一次这么干[允悲]
@看看新闻Knews
【自带的茅台全被调包!男子一摸酒瓶:温度不对】#男子自带3瓶茅台全被服务员调包#近日,市民王先生自带三瓶飞天茅台到饭店宴请亲友,可开席时,细心的王先生却发现餐桌上的三瓶“茅台”好像都不是他带来的,而此前包厢服务员严某上菜之前多次动了这三瓶酒。接到报警,属地派出所民警赶到这家饭店,通过调阅公共视频和现场调查,服务员严某很快承认了自己用网购的假茅台调包真茅台的犯罪事实。当日严某发现茅台后,趁人不备,将三瓶真茅台转移到酒水车,随后借口离开至隔壁备菜间,取出提前藏好的三瓶假酒。据严某交代,她网购的假茅台,每瓶只有两三百元。
而王先生之所以发现了猫腻,是因为酒瓶上的生产日期、批次与自己带来的酒完全不符,连酒瓶温度都有差异。目前,严某因涉嫌盗窃罪已被闵行警方依法采取刑事强制措施。
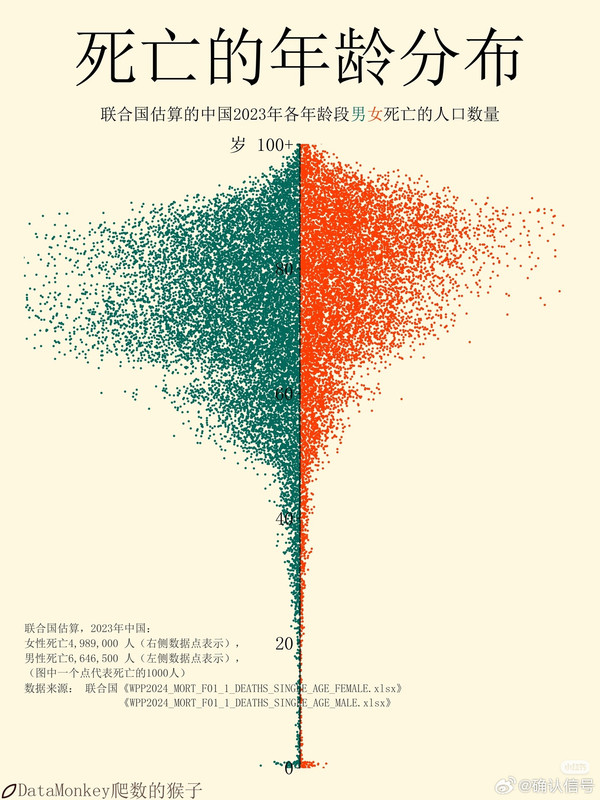
男性46岁以后突然就危险了,我正好是这个岁数[泪]//@程序员邹欣://@子陵在听歌:这个图很有意思,我查了一下,原来这是绝对死亡人数,而不是人口死亡率。60岁出现的死亡高峰并非因为该年龄死亡率突然激增,而是受人口基数驱动的统计现象:2023年处于60岁的人群出生于1963年(中国历史上的出生人口最高峰),庞大的人口基数导致即便死亡率正常,其死亡绝对人数也会显著多于出生人口较少的65岁群体。另外,60岁左右正处于生物学上的剧烈衰老转折点,这恰是一项重要研究的结果(微博正文 )。生理机能的波动与退休带来的生活环境变化叠加,使该年龄段成为健康风险的一个集中爆发区。
@确认信号
隔壁看到的一个有意思数据[思考][思考]
老马抓到以后,委石油抢到手,通胀能下来,降息就是必然了。//@李一汤:疯牛市要来了!!。。。#李一汤#。。。
@财联社APP
#美联储理事认为应降息超100个基点#【美联储理事米兰:美联储今年应降息超过100个基点】财联社1月6日电,美联储理事米兰表示,预计后续经济数据将继续支持“降息是合适的”这一政策方向。美联储今年应降息超过100个基点。美联储政策显然是限制性的,阻碍了经济发展。还没和总统谈过美联储主席一职的事。
这个市场整体上有些吃beta,比如买指数,有些是吃alpha,买自己熟悉的好股票,长期持有,也有吃theta,吃波动。不大可能有一种完美的策略,否则就会成为一个黑洞吞掉所有的钱。找到合适自己,合适当前市场的,是最好的。
经常有网友拿着300%收益率说自己的策略是最好的,这说明不了什么,等你有10亿美金,你无论如何也做不到300%收益率的,相信我,任何一个转身都可怕的足以扰动市场。
我搞股东大会的目的也不是证明我多牛逼,核心内容接近50页PPT还是讲AI方向的内容,讲的是alpha方向的内容,附带讲一些theta,beta的内容,扩大一些视野也是好的,毕竟并不是所有人都了解。。
距离1月10日梁博首届股东大会还有几天了,按照计划有2-3份实操讲解。其中最重要的是这个经典策略,是我本人长期摸索的,原以为是原创,没想到暗合了教科书上的期权轮动策略,这个部分估计要花30-40分钟讲透。 不过这个策略是需要有较多保证金,有一定门槛。
另外两份经典策略还在写,都会由@梁博第二助理 分发,谢谢。目前已经没有线下参会名额了,之前没有报名线下的,只能看下这些资料了,其实也一样因为写的已经很清楚了。
当然了,还是那句话,毕竟水平不高,有些不足的地方,大家多包含,独立思考,批评学习哈。
最近大模型大厂都大搞Agent了,我们这边数据调用量也井喷,我有一种预感,公司天花板可能比想象中还要高10倍,努力吧。今天刚花了120万买机器,还需要继续买。。
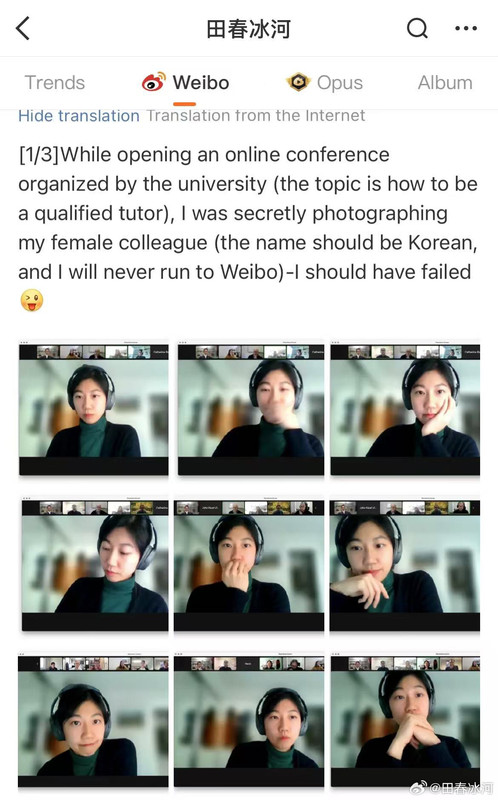
[4/3] 话说尼泊尔姑娘有每天写英文日记(然后每年换一个本子)的习惯,现在已经抛弃了她原先的破圆珠笔,对我送的金笔爱不释手。回想飞机临降落时她突然问我何时返回堪培拉(她在悉尼某医院里做护工),我知道她有些依依不舍,但不想透露实情,就只说自己要放个长假不知道何时返澳,然后她就不知道怎么回应了。我明白她的意思,于是掏出纸来留下了自己的名字和苹果邮箱(Gmail 主邮箱在国内不能用),说是如有电脑相关问题可以找我。她很高兴,也给我留下了她的。回到家以后还没等我主动发邮件给她,她就先联系我了。其实我在飞机上跟邻座的姑娘萍水相逢的事情不止一次,但最后留不留联系方式也要看情况的。要没这些烂事的话,等我返澳以后可能她真的会从悉尼跑来看我,或者我终于有理由去一趟悉尼市区看看了……
https://postimg.cc/gallery/gXKjWX0


王卓然bill:要不您俩去杰维斯湾见[doge]。风景优美,离你俩都远
26-1-5 14:50 来自澳大利亚
田春冰河
:只要你肯打钱,我直接去尼泊尔看她。
26-1-5 14:51 来自辽宁
[4/3] 话说尼泊尔姑娘有每天写英文日记(然后每年换一个本子)的习惯,现在已经抛弃了她原先的破圆珠笔,对我送的金笔爱不释手。回想飞机临降落时她突然问我何时返回堪培拉(她在悉尼某医院里做护工),我知道她有些依依不舍,但不想透露实情,就只说自己要放个长假不知道何时返澳,然后她就不知道怎么回应了。我明白她的意思,于是掏出纸来留下了自己的名字和苹果邮箱(Gmail 主邮箱在国内不能用),说是如有电脑相关问题可以找我。她很高兴,也给我留下了她的。回到家以后还没等我主动发邮件给她,她就先联系我了。其实我在飞机上跟邻座的姑娘萍水相逢的事情不止一次,但最后留不留联系方式也要看情况的。要没这些烂事的话,等我返澳以后可能她真的会从悉尼跑来看我,或者我终于有理由去一趟悉尼市区看看了……
https://postimg.cc/gallery/gXKjWX0
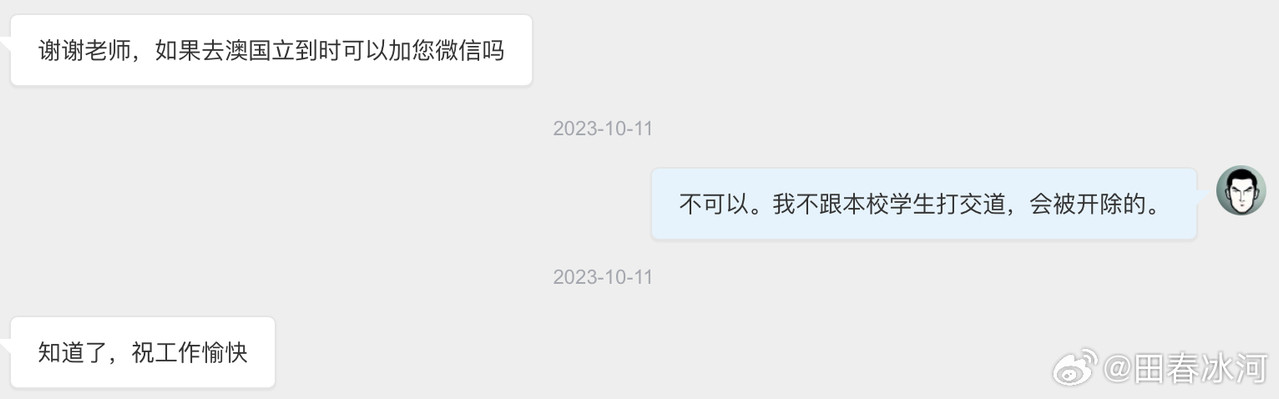
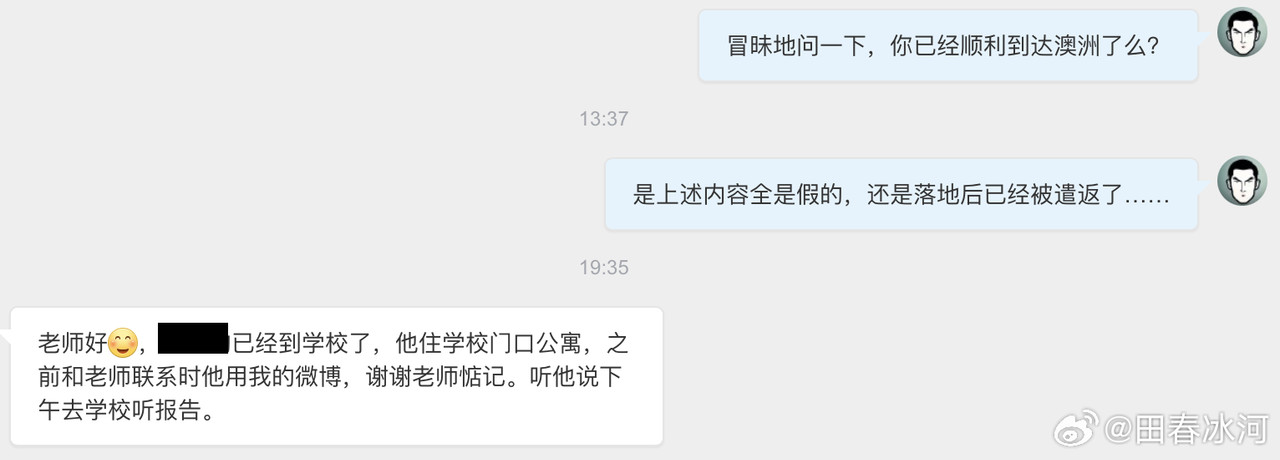
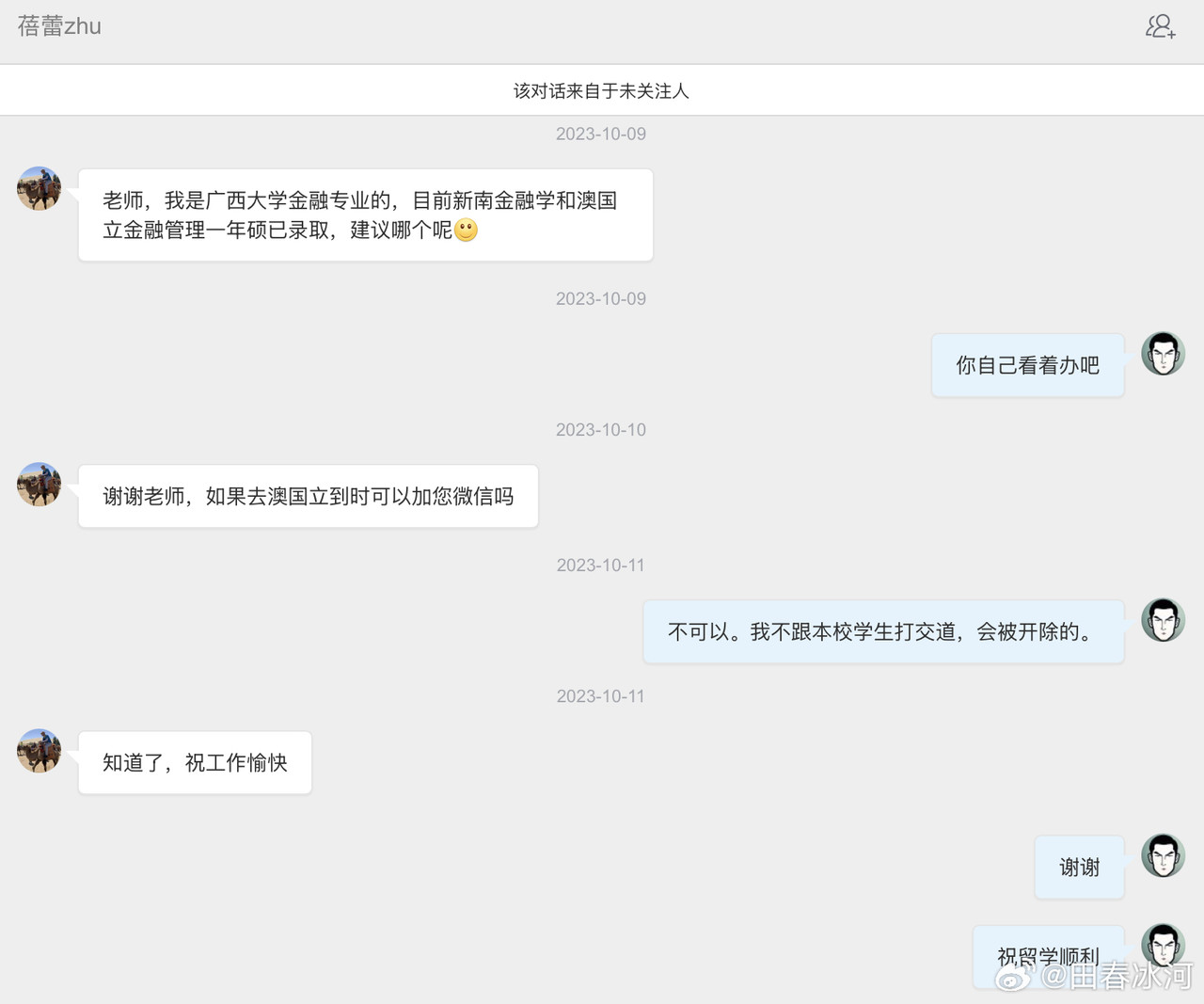
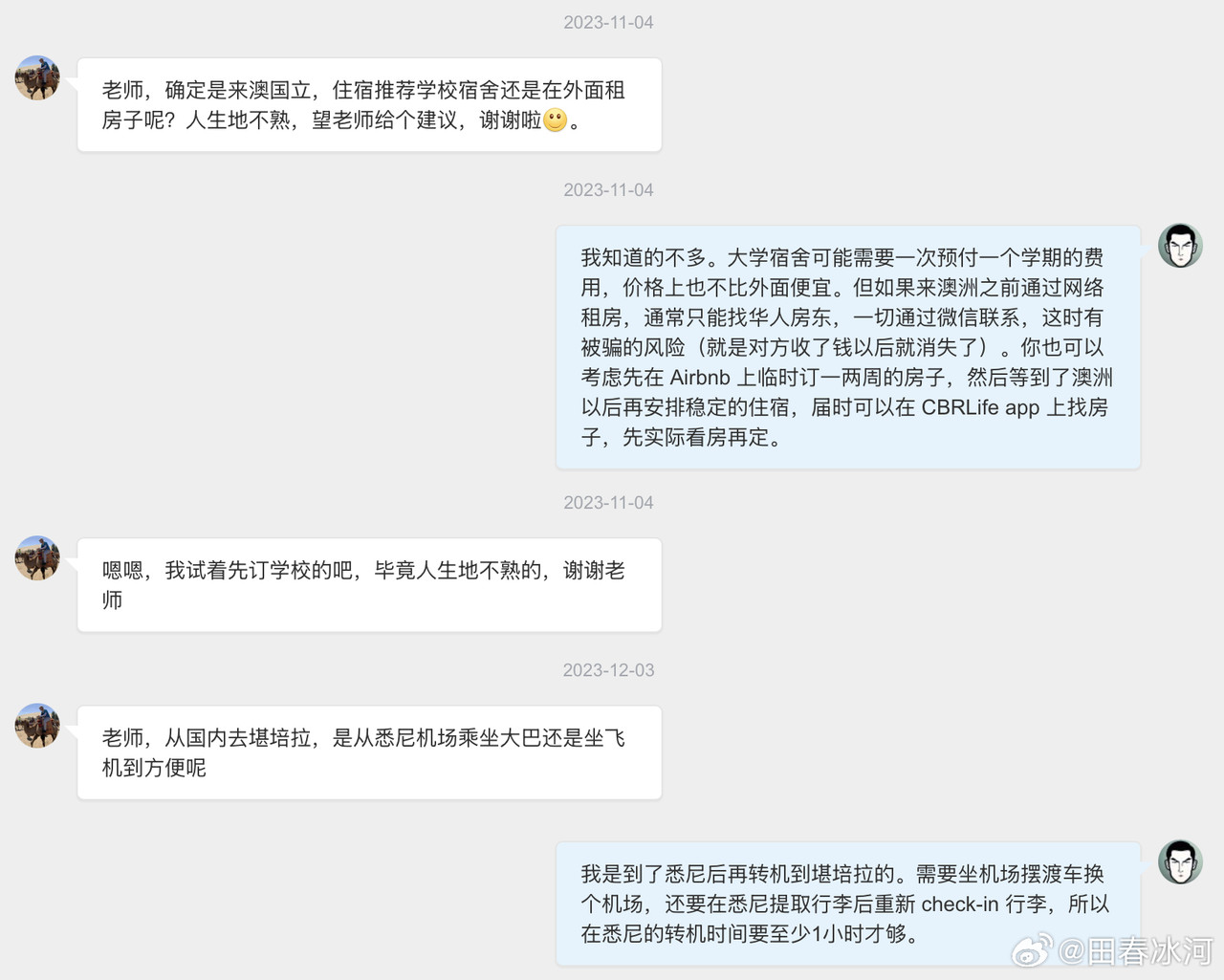
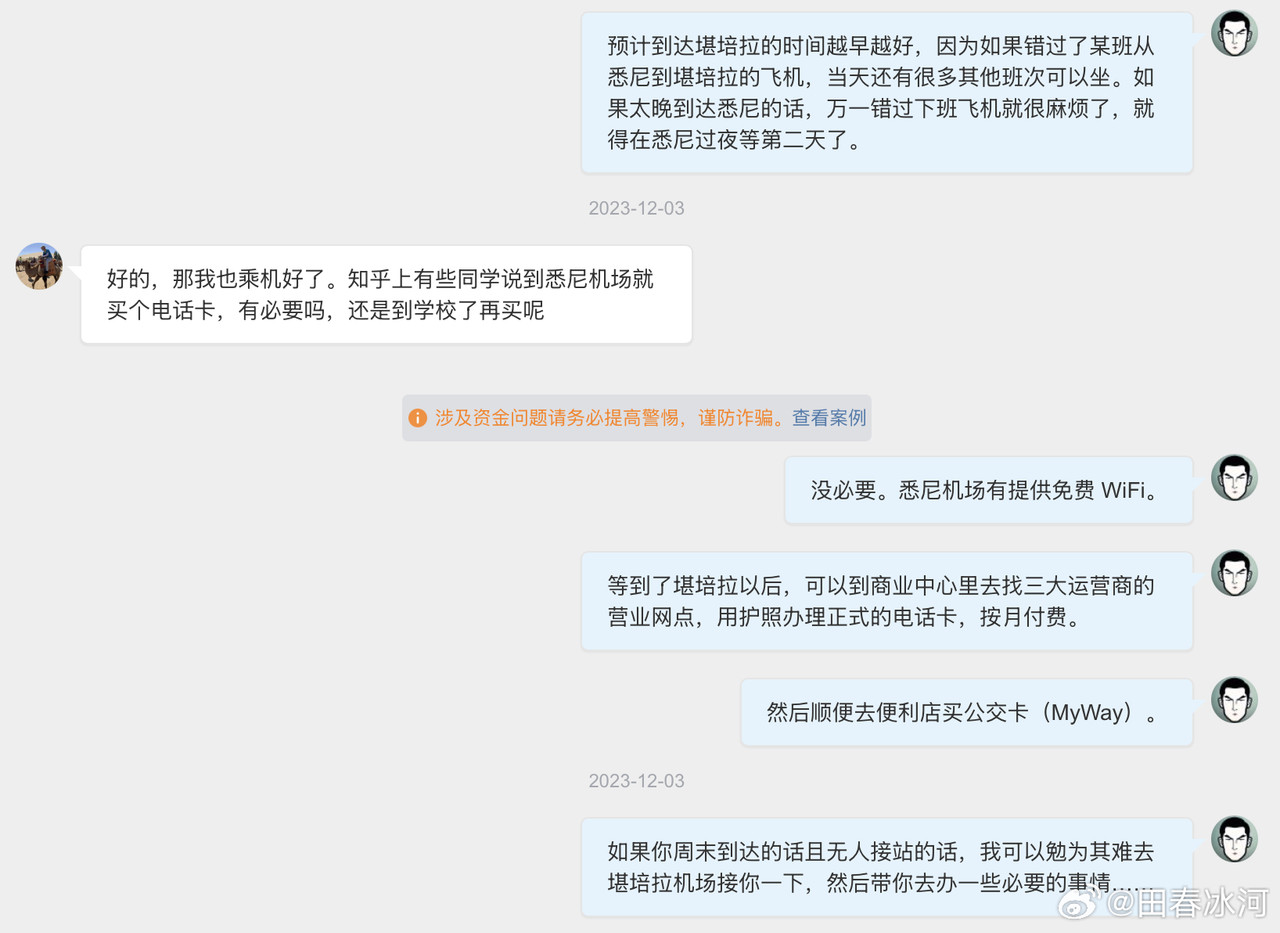
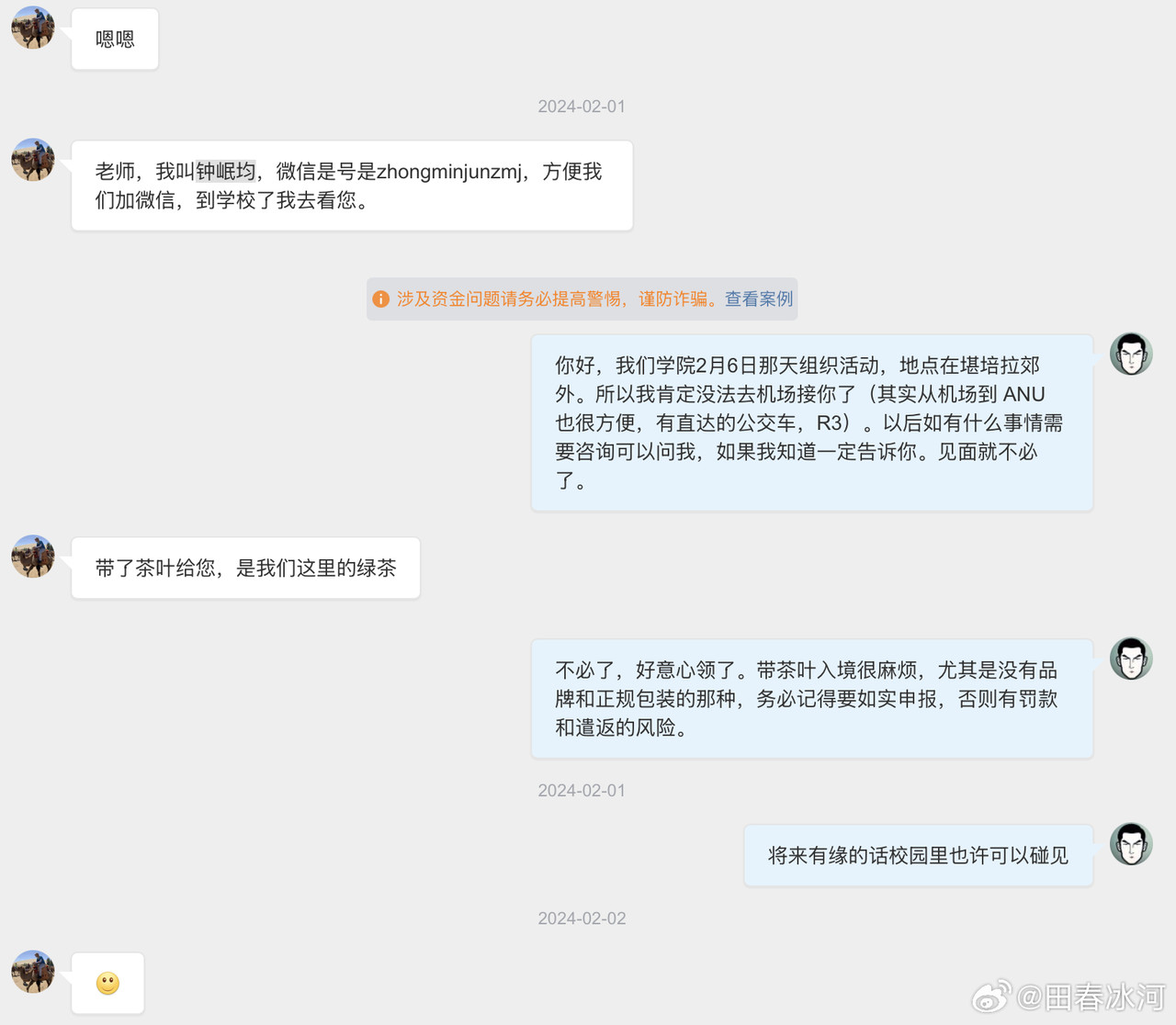
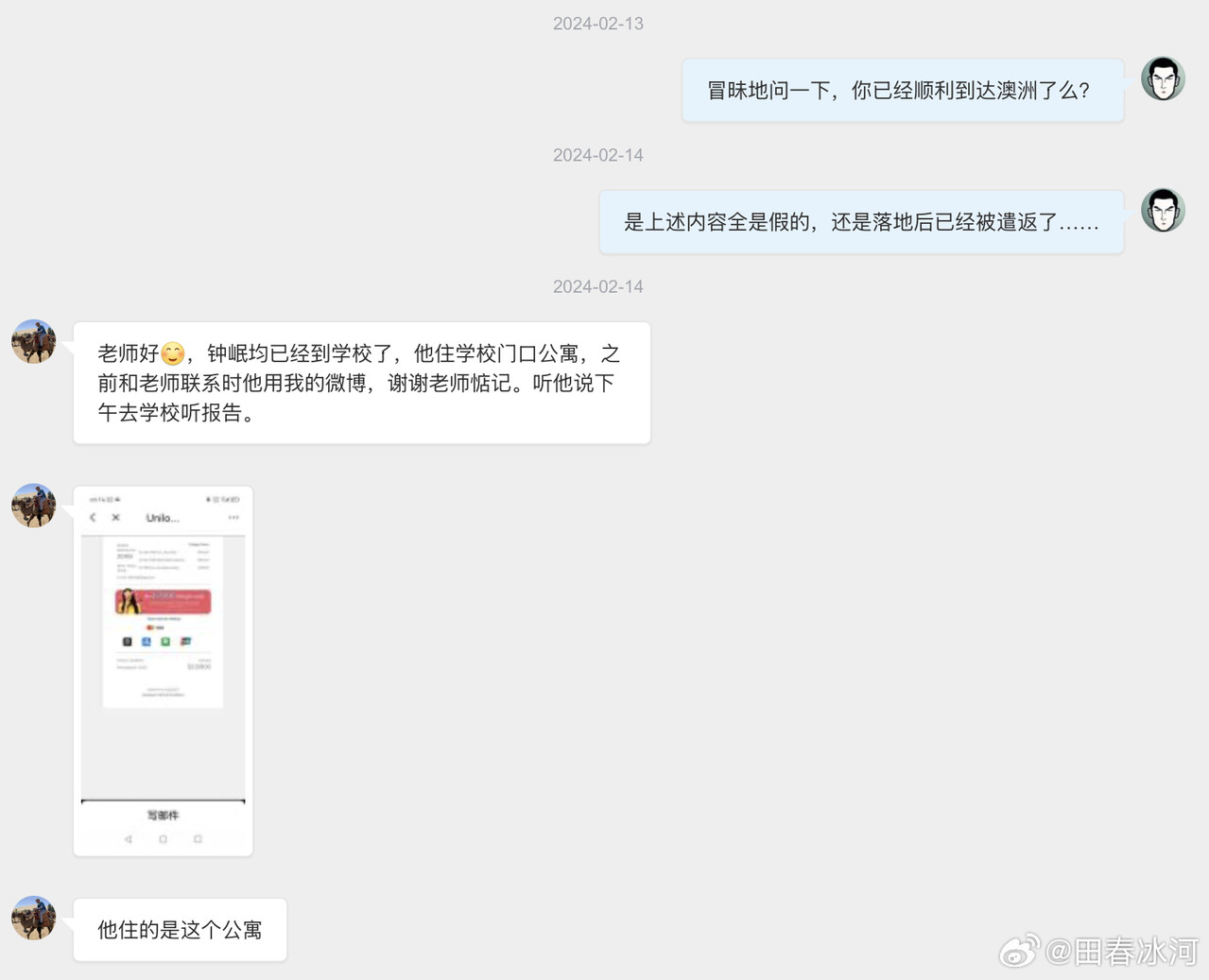
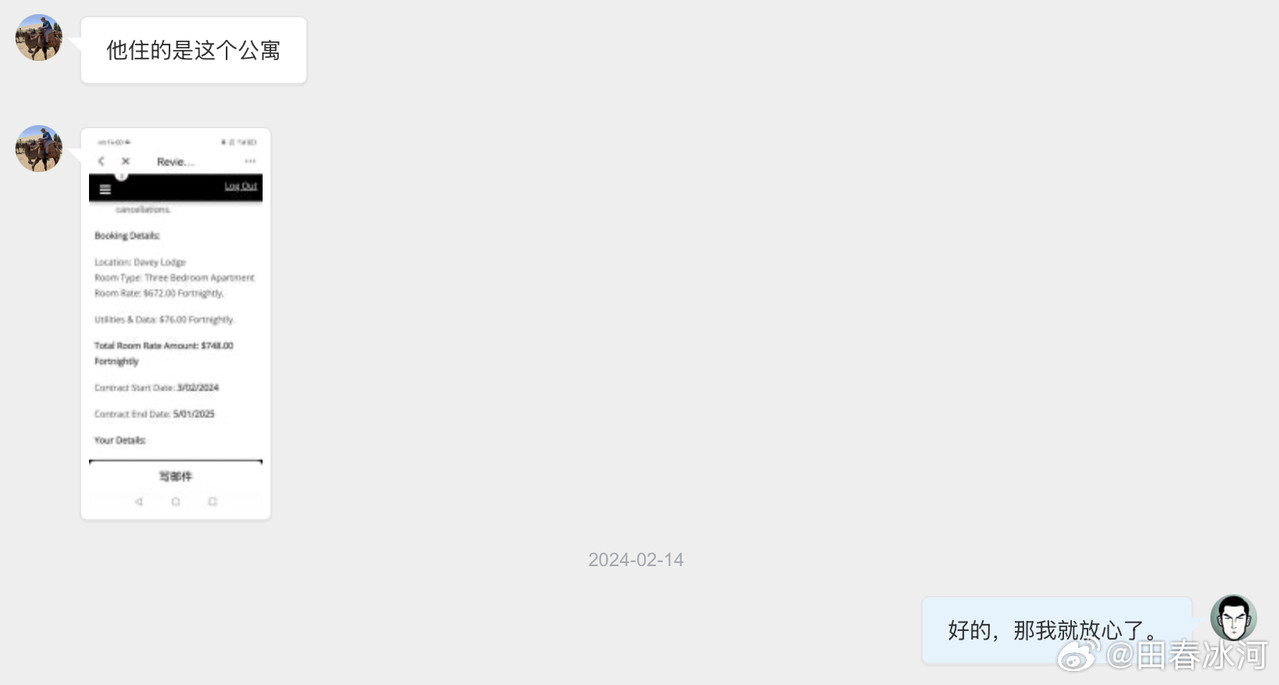
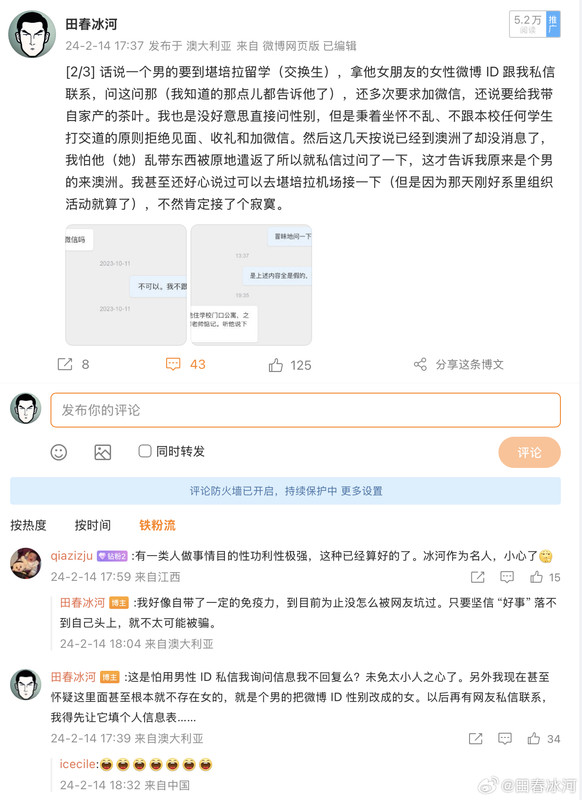
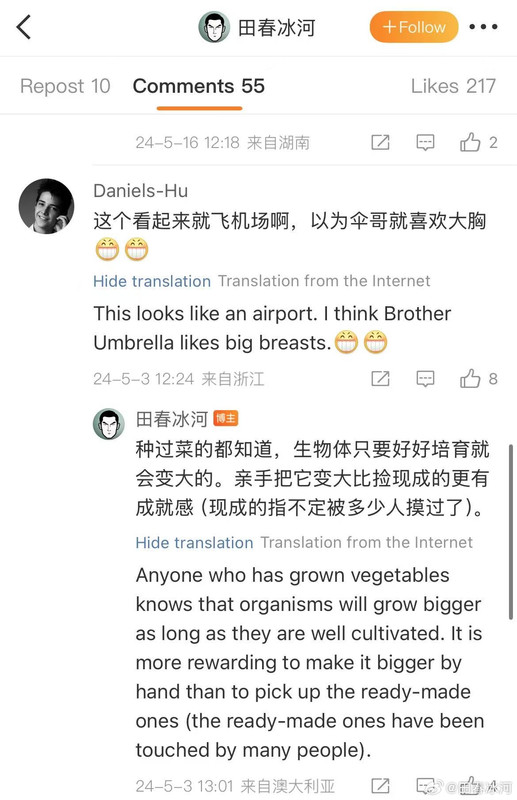
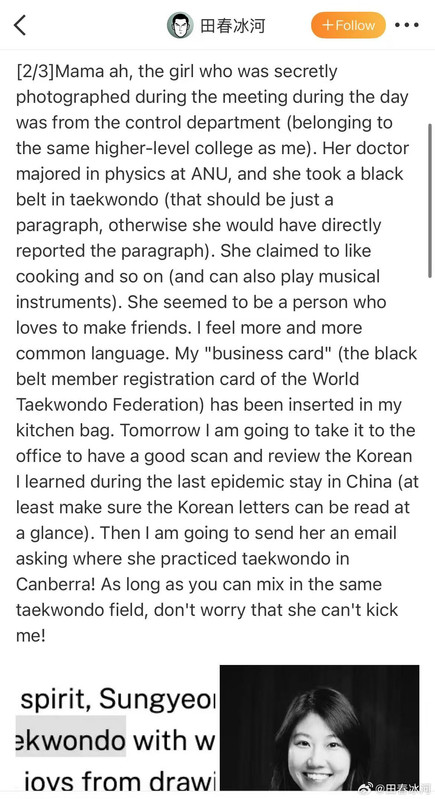
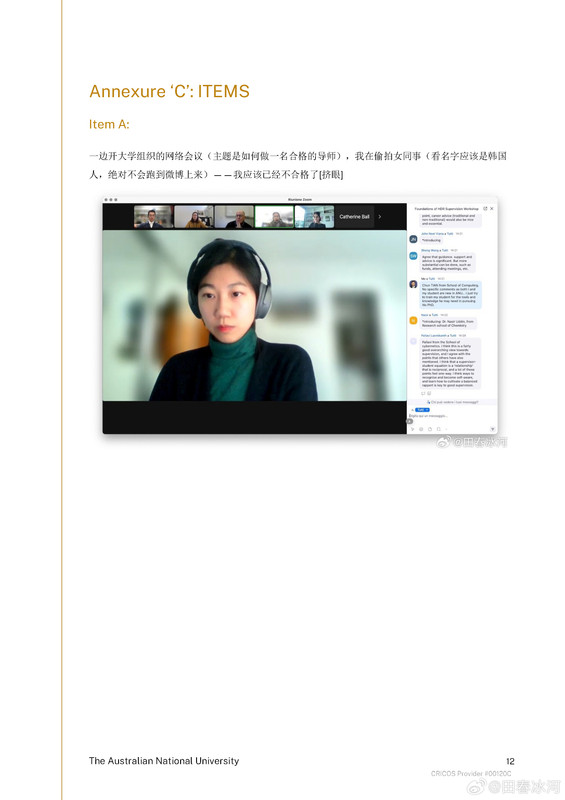
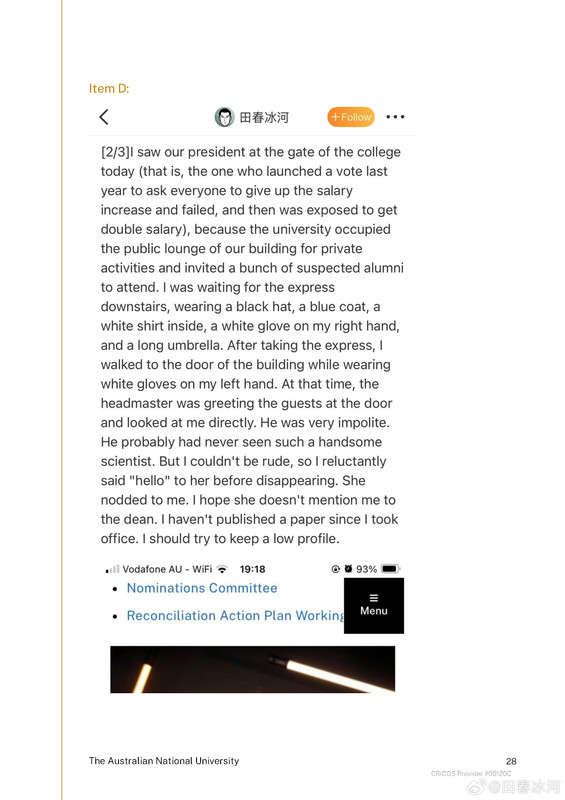
[3/3] 下面讲一个故事,这件事跟我的其他事可能有关系也可能没关系。2023年10月,网友 @蓓蕾zhu https://weibo.com/u/2299752901 https://weibo.com/n/%E8%93%93%E8%95%BEzhu (账号性别女) 私信联系我(过去可能有过评论交流,属于比较眼熟的 ID),说是广西大学金融专业的,要来澳洲留学,二选一让我给拿主意,还要加微信。我没注意(再说也不是同专业的),只能礼貌地敷衍一下。后来她确定要来澳国立,我就把我所知道的注意事项都告诉她了。某条私信里她说她叫 “钟岷均”,我也没太在意(也许人家女的就叫这个名字),还要加微信。我再次拒绝(我为什么跟一个学金融的本校学生交朋友?)但后来我于心不忍都打算去机场接一下了,但是碰巧当天学院在校外开会就没去成。结果万万没想到,到了2024年2月时来留学的不是个女的,而是个男的(俩人用同一个微博跟我私信)。但我也不清楚具体这俩人是什么关系,就冒昧地猜测是男朋友(实为母子),于是发了一篇微博(微博正文https://weibo.com/1929185323/O0zGTrVG9?pagetype=profilefeed[2/3] 话说一个男的要到堪培拉留学(交换生),拿他女朋友的女性微博 ID 跟我私信联系,问这问那(我知道的那点儿都告诉他了),还多次要求加微信,还说要给我带自家产的茶叶。我也是没好意思直接问性别,但是秉着坐怀不乱、不跟本校任何学生打交道的原则拒绝见面、收礼和加微信。然后这几天按说已经到澳洲了却没消息了,我怕他(她)乱带东西被原地遣返了所以就私信过问了一下,这才告诉我原来是个男的来澳洲。我甚至还好心说过可以去堪培拉机场接一下(但是因为那天刚好系里组织活动就算了),不然肯定接了个寂寞。),谴责网络上伪造性别和共用账号的行为,可能因此就把他们给得罪了。2025年6月这孩子毕业归来,4月的时候大概是觉得毕业定下来了,不管干什么都不影响毕业了。注意,我可没说就是这娘俩举报的,但人数确实对得上。这算不算是处心积虑,伺机报复?咱俩到底谁错了?
https://postimg.cc/gallery/Sm6Gh3L
SwordfishAction:外国人上纲上线这么厉害,还是说就是大学研究机构没钱了就找个理由开人省钱?
26-1-5 12:08 来自广东
按热度
按时间
田春冰河
:回复@SwordfishAction:我故意刺你一句,你没生气还自己反思了一下,已经算是不错了。更多的人因此就直接把我拉黑,从此反目成仇了。
26-1-5 15:01 来自辽宁
SwordfishAction:回复@田春冰河:你明显情绪激动了,我这评论提问其实也没啥益处和建设性,算了
26-1-5 13:56 来自广东
田春冰河
:你问谁呢?我怎么知道?你这种问题就跟那些问 “印度人是不是都作弊” 的人一样可恶,你钓鱼呢?
26-1-5 12:09 来自辽宁
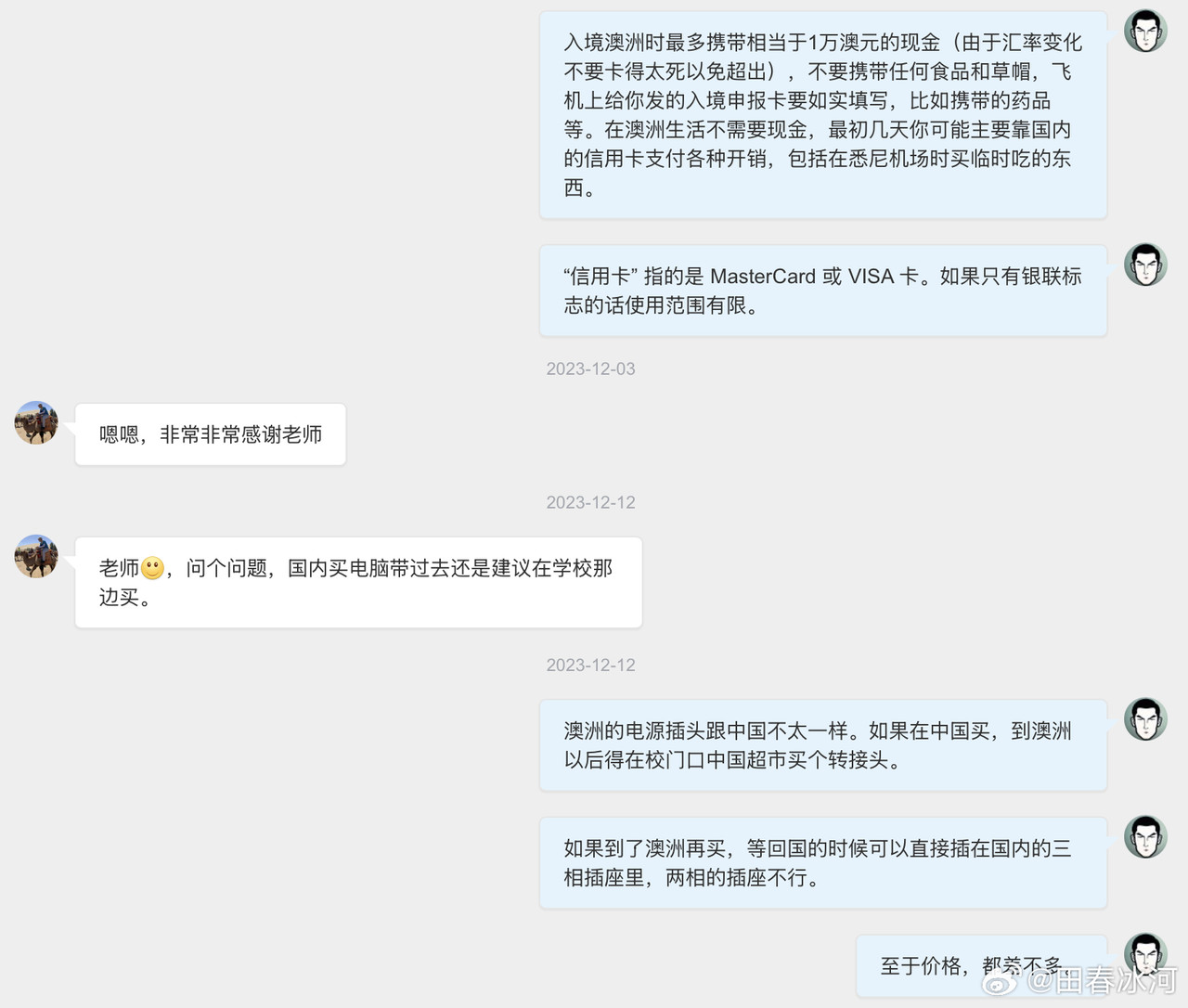
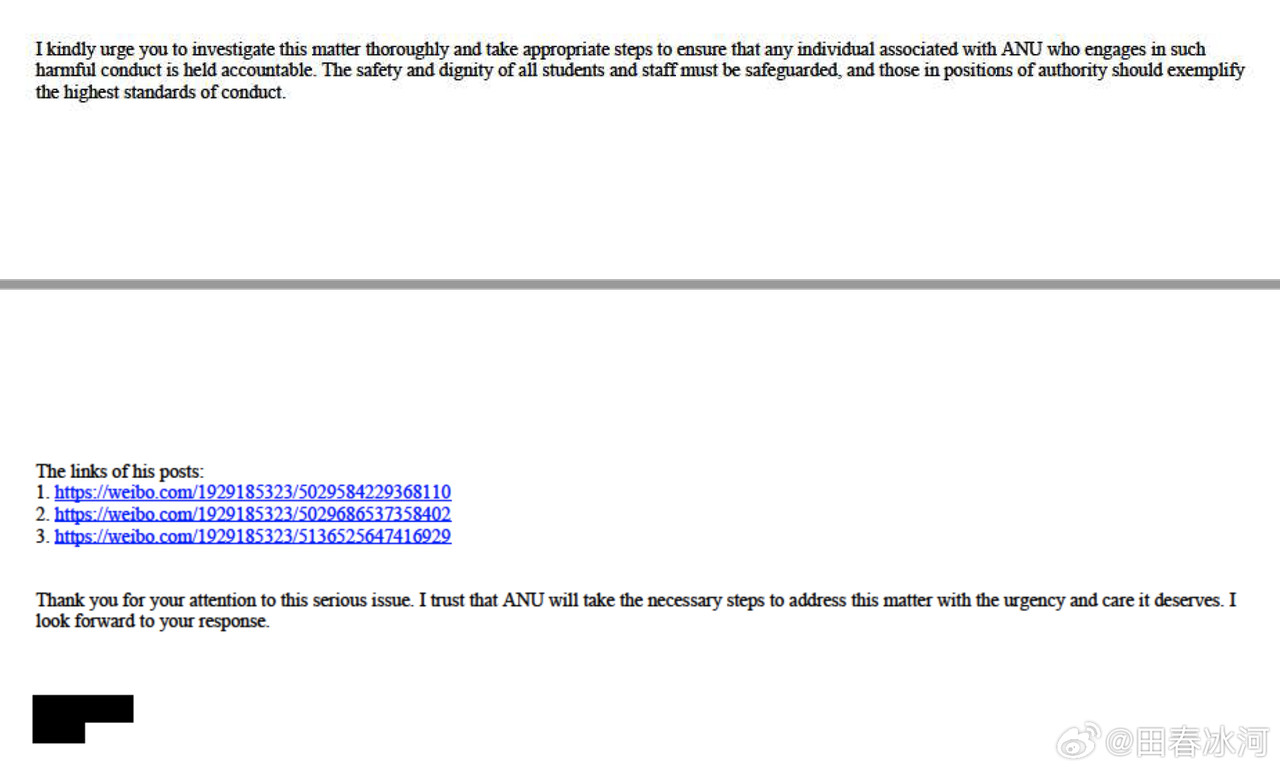
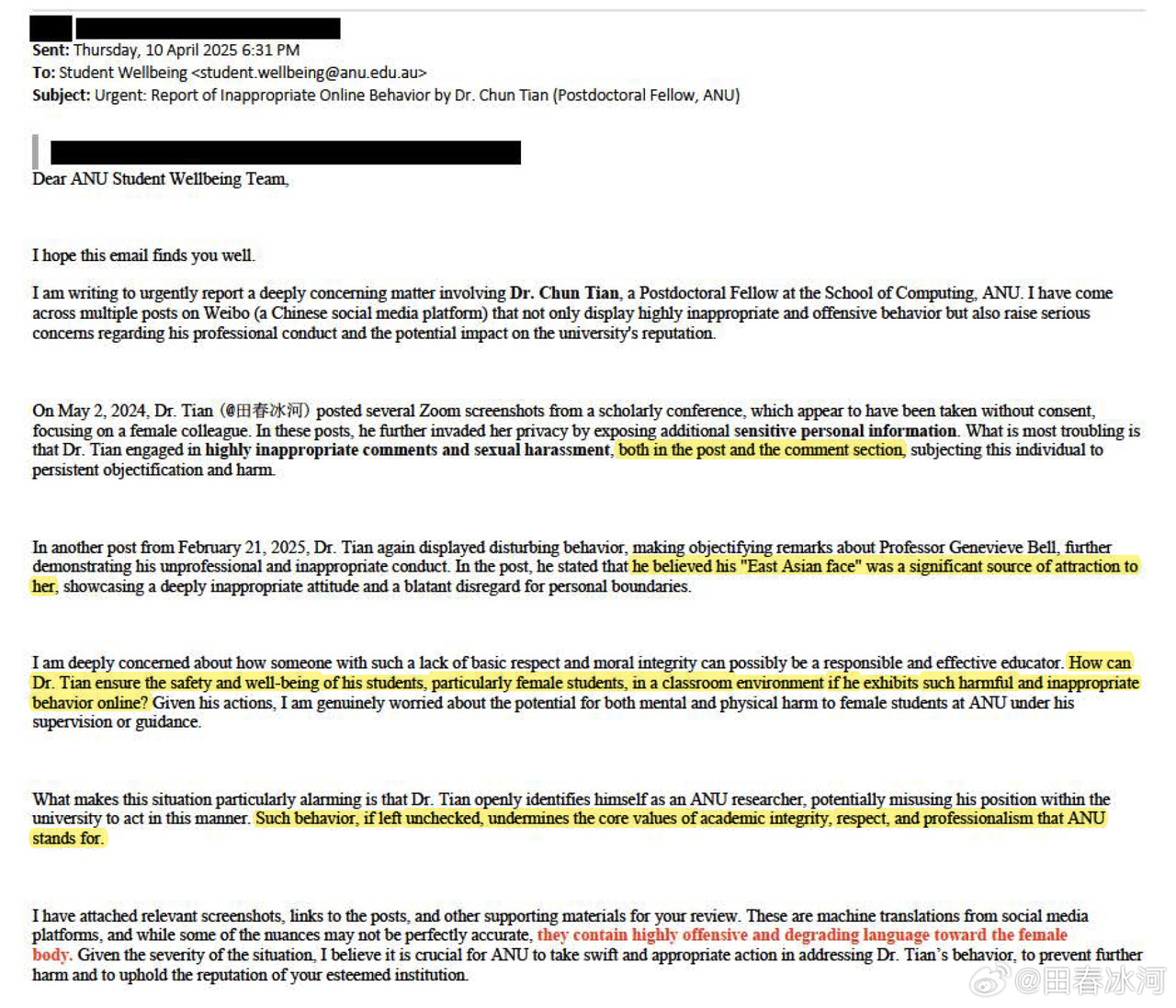
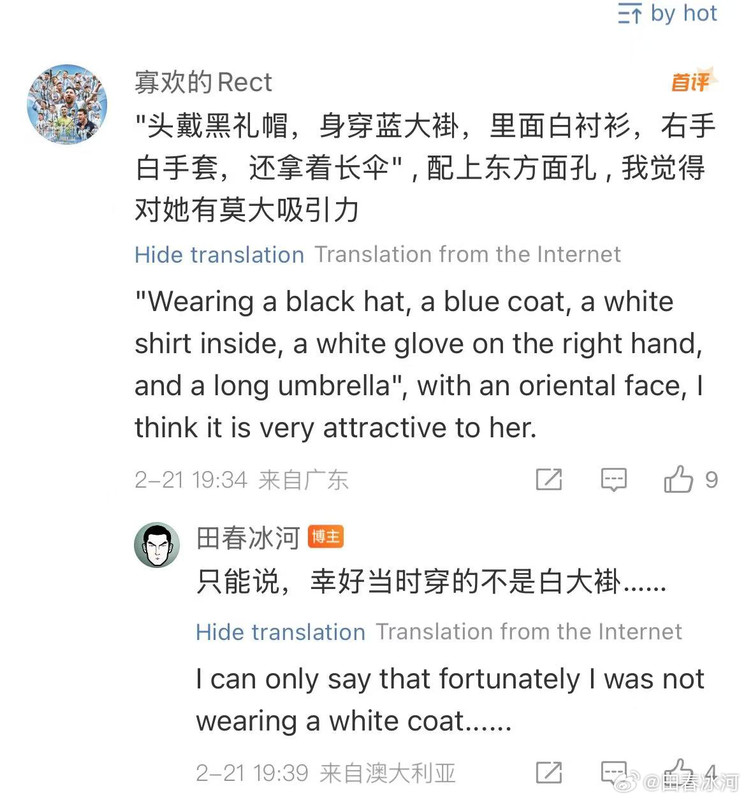
[1/3] 下面公布2025年4月10日18:01和18:31(间隔刚好半小时)澳国立Student Wellbeing 邮箱收到的两封举报信以及随邮件附带的截图证据。我能看到的版本不含有发信人姓名。它们能知道这个邮箱就说明至少有一个是本校的在读学生(我都不知道还有这么个邮箱)。第一封措辞粗鲁,英语水平较差,应该是学生本人;第二封信的措辞相对严谨,英语水平较高,目测是学生她妈。字字凶狠,上纲上线。这还不是全部的证据,后来学校派了一个女的继续调查,正式的指控文件里还有更多的微博截屏(含网友评论)。注意有些话(什么 “东方面孔” 之类的)本不是我说的而是网友的评论,结果也被栽在我的头上了……
https://postimg.cc/gallery/B67Mkb8







芒果自制剧:打⭕️吗,伞哥这么小众的账号,还有人关注,你们这帮乱评论的网友都有责任,我只关注某部经典翻译进度怎么样了[doge]
26-1-5 11:48 来自湖南
田春冰河
:回复@芒果自制剧:不用你提醒,在办了!
26-1-5 15:13 来自辽宁
芒果自制剧:补充一下,待翻译的经典[团圆时刻] http://t.cn/AXbcsR6p查看图片
26-1-5 15:11 来自湖南
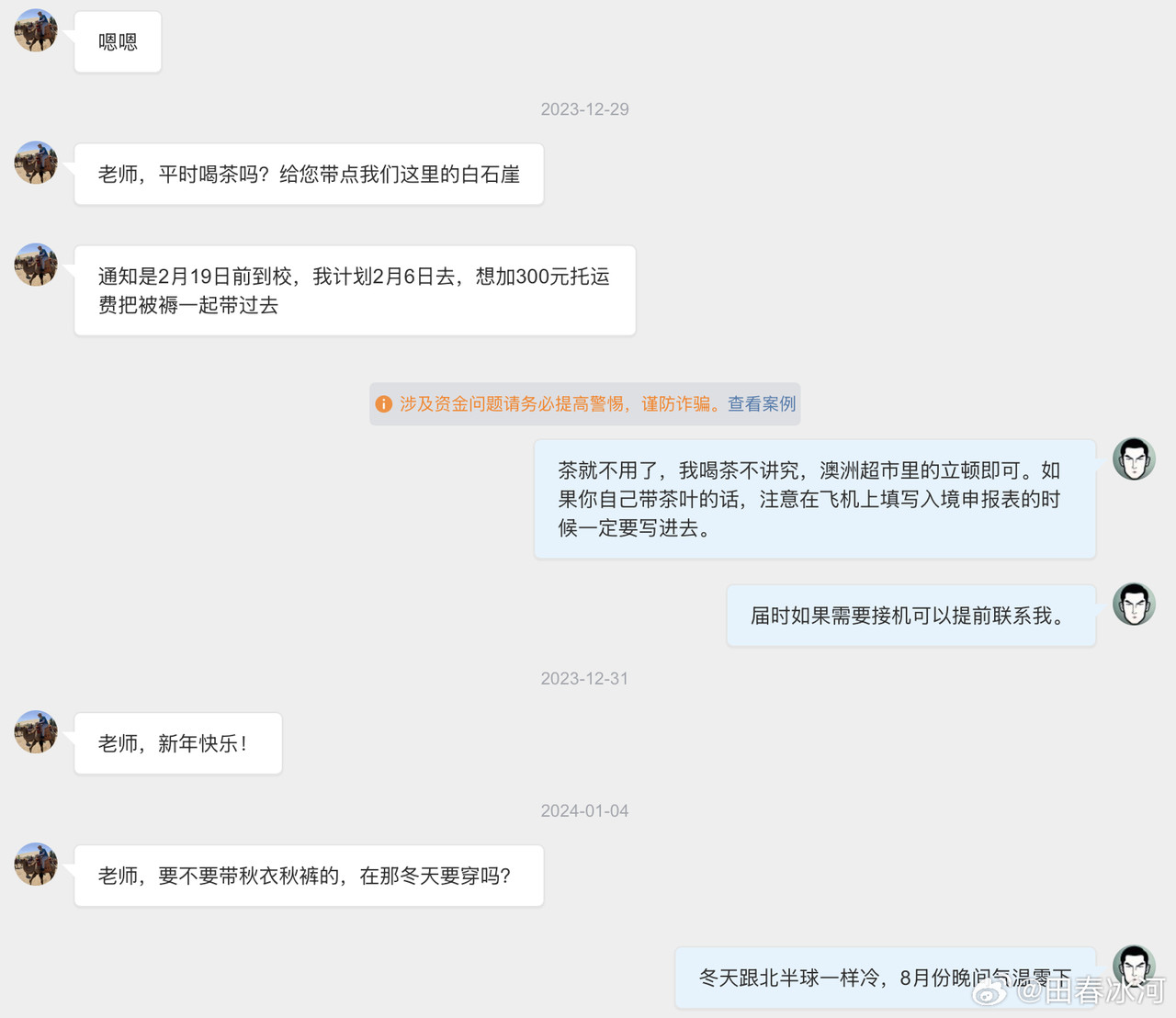
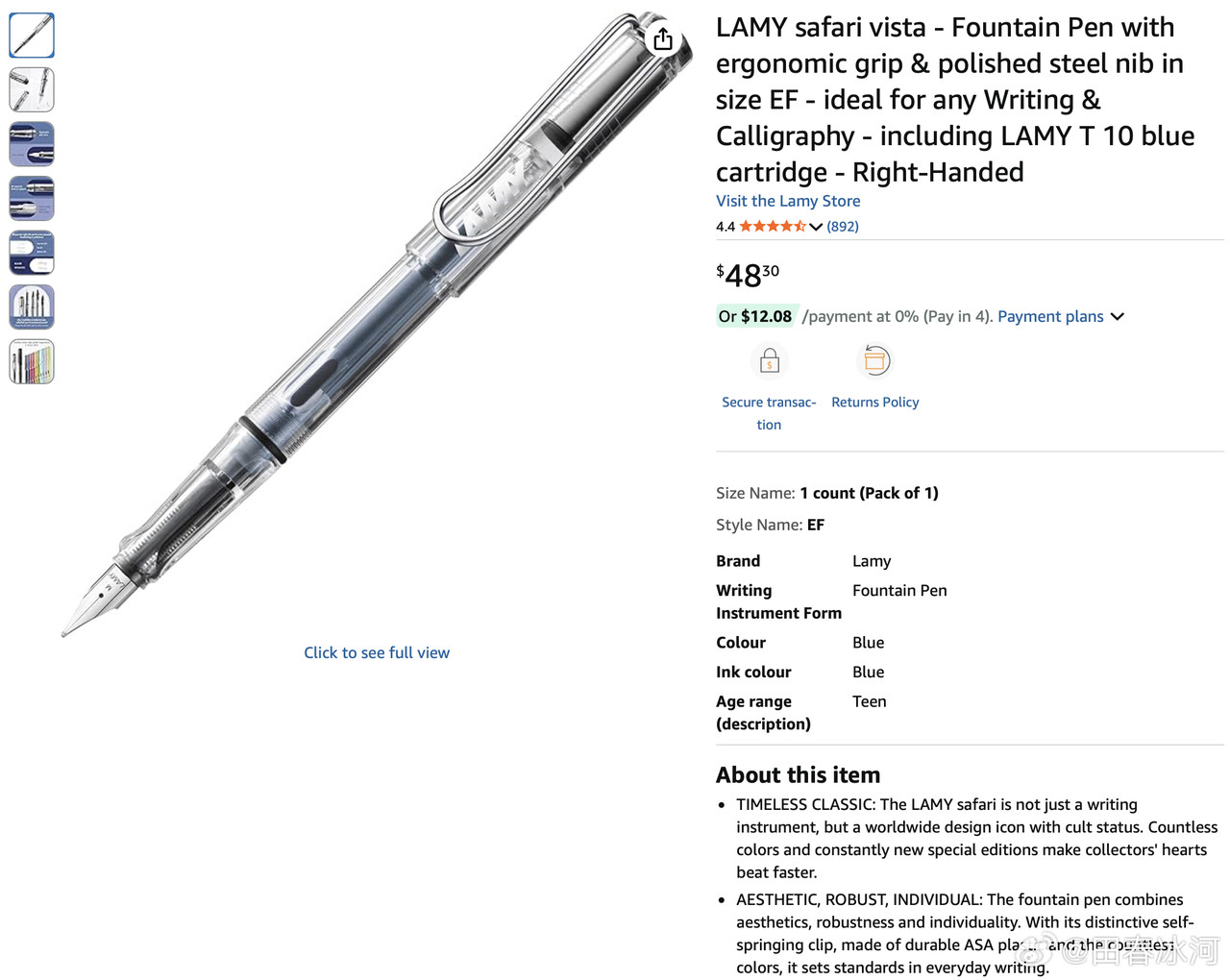
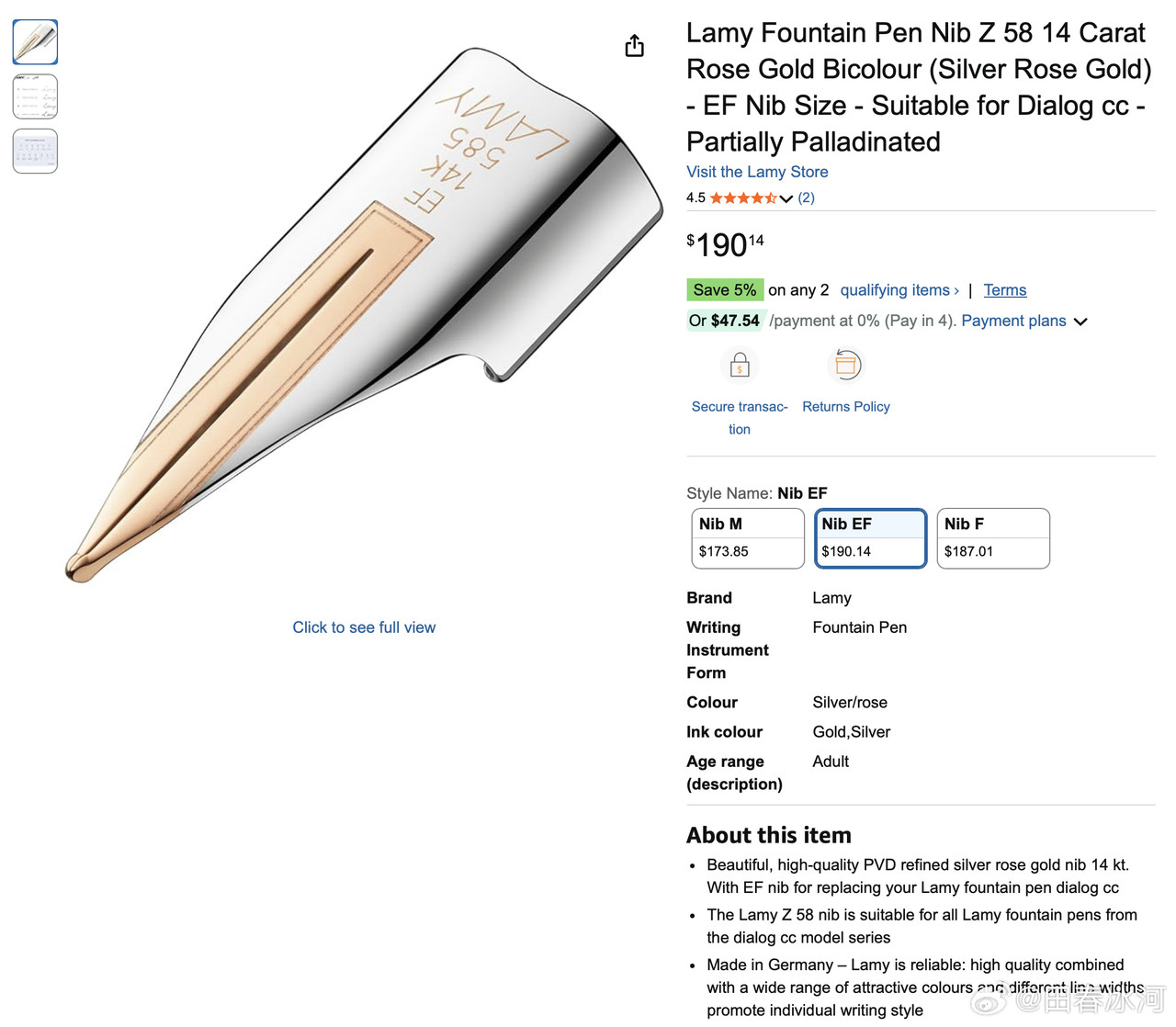
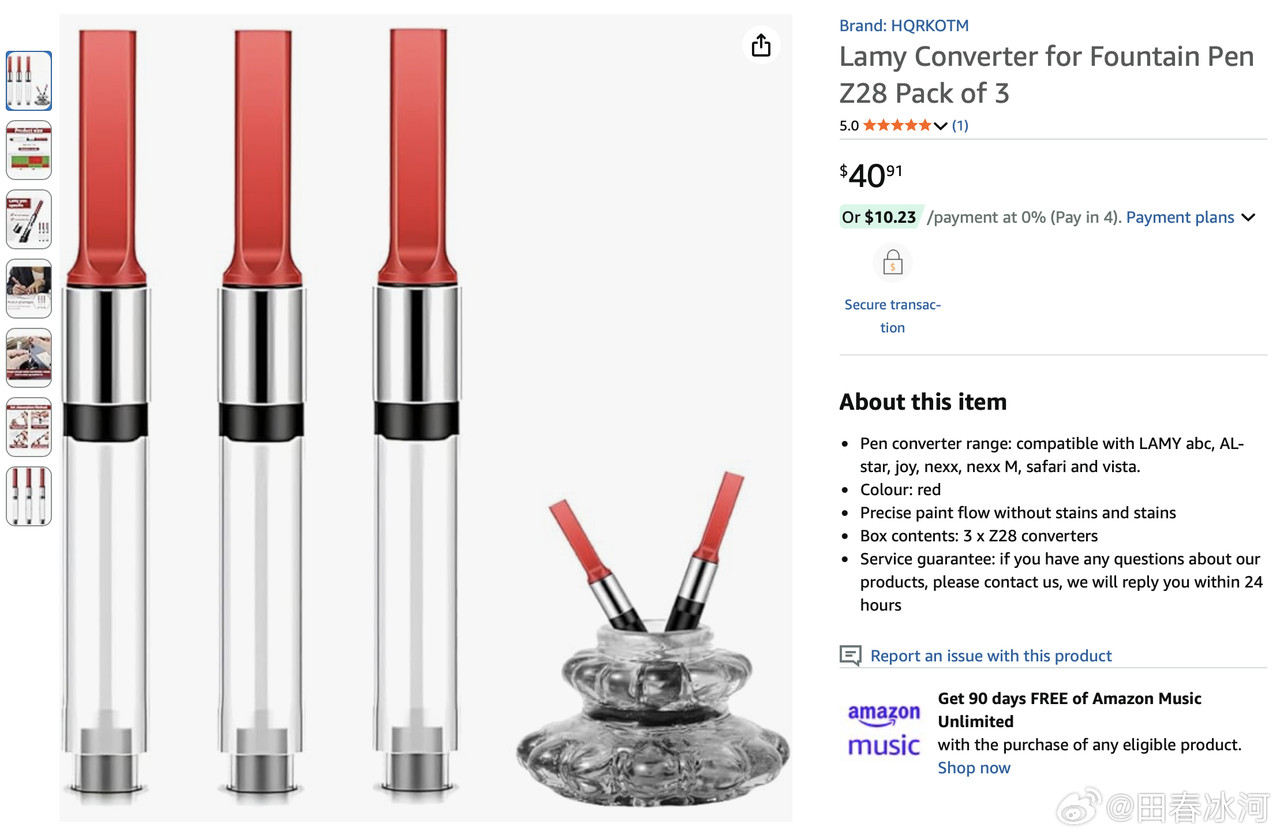
[3/3] 话说我送给尼泊尔姑娘的那支 LAMY 钢笔,是我自己组装的,直接买是没有的。其笔尖是 Z58 EF(14K 玫瑰金,部分镀钯),澳洲亚马逊上售价 190 澳元(需要从德国进口);笔杆是透明的 Safari Vista(自带的钢尖拔下来扔掉),49 澳元;吸墨器是 Z28,3枚售价40澳元。加起来不算便宜了。此笔的特点是笔尖光滑柔软、笔身通透(一眼看出还剩多少墨)、手感也符合人体工学。这才是钱花在刀刃上的好钢笔,谁敢说这不是金笔?
https://postimg.cc/gallery/50BqcLd
Rhonin三代目:别姑娘了,小心又被举报了[doge]
26-1-4 21:13 来自北京
按热度
按时间
qiazizju:回复@田春冰河:以后拿了诺奖,会被别人挖黑历史[挖鼻]
26-1-5 13:32 来自浙江
qiazizju:之前穿着皮鞋,现在光着脚呢,冰河可以敞开发
26-1-5 13:31 来自浙江
田春冰河
:可是举报给谁呢?
26-1-4 21:14 来自辽宁
SwordfishAction:外国人上纲上线这么厉害,还是说就是大学研究机构没钱了就找个理由开人省钱?
26-1-5 12:08 来自广东
田春冰河
:你问谁呢?我怎么知道?你这种问题就跟那些问 “印度人是不是都作弊” 的人一样可恶,你钓鱼呢?
26-1-5 12:09 来自辽宁
[2/3] (接上文)后来大学从 HR 部门里派出一个女调查员(外国人,看不懂中文),她不满足于照抄投诉信,又在我的微博里找到了几条我抱怨那个印度女学生用生成式 AI 生成形式化证明代码(完全不可用)的微博,其中某个评论的回复里我提到(所有)印度人都这个尿性…… 这便构成了 “种族歧视”。指控信本身很无聊,附图是证据部分。请各位铁粉们找一下自己的名字吧(注意有些中文 ID 可能被强行翻译成了英文,纯英文 ID 则原样不变)
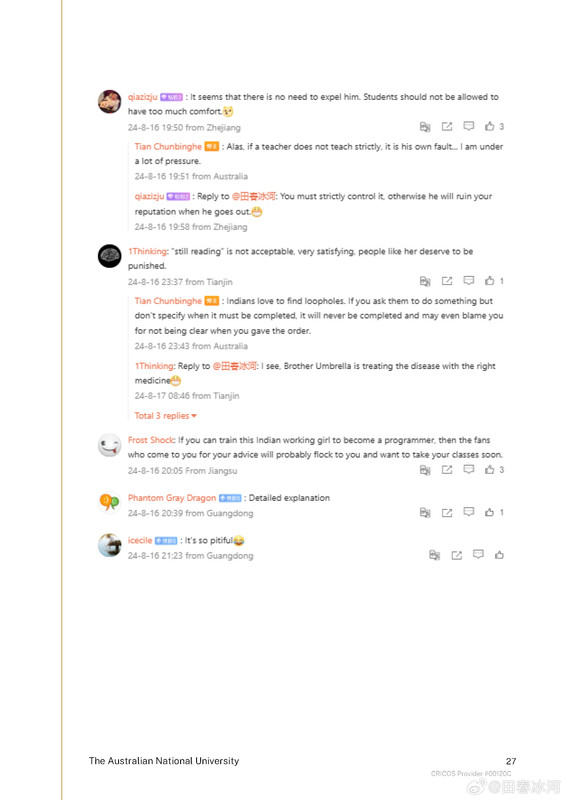
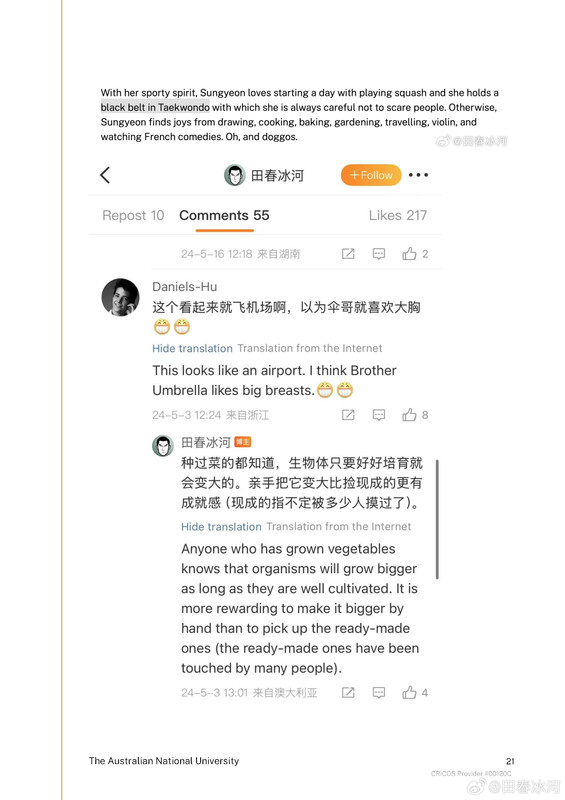
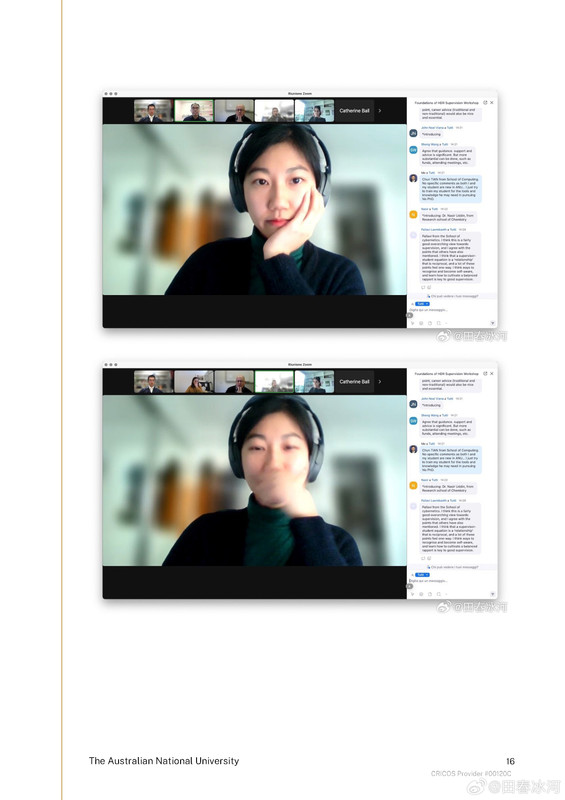


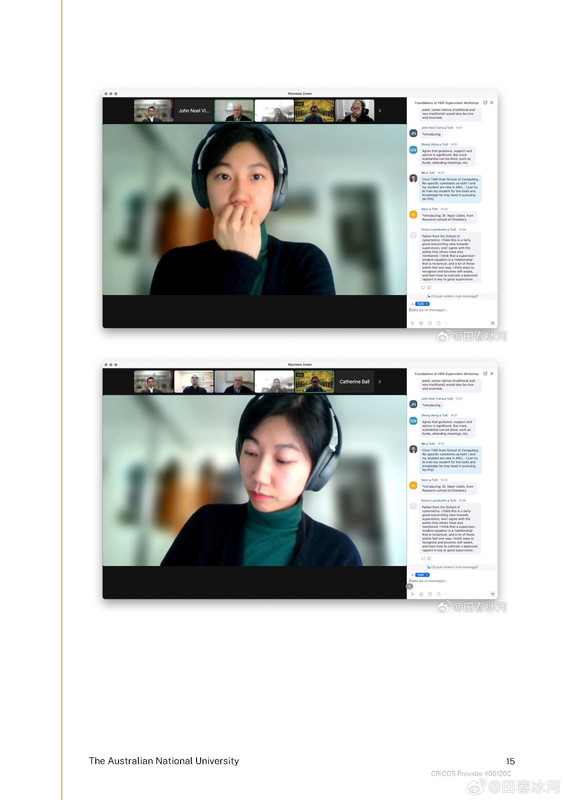




[1/3] 下面公布2025年4月10日18:01和18:31(间隔刚好半小时)澳国立Student Wellbeing 邮箱收到的两封举报信以及随邮件附带的截图证据。我能看到的版本不含有发信人姓名。它们能知道这个邮箱就说明至少有一个是本校的在读学生(我都不知道还有这么个邮箱)。第一封措辞粗鲁,英语水平较差,应该是学生本人;第二封信的措辞相对严谨,英语水平较高,目测是学生她妈。字字凶狠,上纲上线。这还不是全部的证据,后来学校派了一个女的继续调查,正式的指控文件里还有更多的微博截屏(含网友评论)。注意有些话(什么 “东方面孔” 之类的)本不是我说的而是网友的评论,结果也被栽在我的头上了……
https://postimg.cc/gallery/B67Mkb8
[1/3] 下面公布2025年4月10日18:01和18:31(间隔刚好半小时)澳国立Student Wellbeing 邮箱收到的两封举报信以及随邮件附带的截图证据。我能看到的版本不含有发信人姓名。它们能知道这个邮箱就说明至少有一个是本校的在读学生(我都不知道还有这么个邮箱)。第一封措辞粗鲁,英语水平较差,应该是学生本人;第二封信的措辞相对严谨,英语水平较高,目测是学生她妈。字字凶狠,上纲上线。这还不是全部的证据,后来学校派了一个女的继续调查,正式的指控文件里还有更多的微博截屏(含网友评论)。注意有些话(什么 “东方面孔” 之类的)本不是我说的而是网友的评论,结果也被栽在我的头上了……
https://postimg.cc/gallery/B67Mkb8
[3/3] 话说我送给尼泊尔姑娘的那支 LAMY 钢笔,是我自己组装的,直接买是没有的。其笔尖是 Z58 EF(14K 玫瑰金,部分镀钯),澳洲亚马逊上售价 190 澳元(需要从德国进口);笔杆是透明的 Safari Vista(自带的钢尖拔下来扔掉),49 澳元;吸墨器是 Z28,3枚售价40澳元。加起来不算便宜了。此笔的特点是笔尖光滑柔软、笔身通透(一眼看出还剩多少墨)、手感也符合人体工学。这才是钱花在刀刃上的好钢笔,谁敢说这不是金笔?
https://postimg.cc/gallery/50BqcLd
举目向高山:这个笔尖的造型真的很像一个逼
26-1-4 18:36 来自山东
田春冰河
:……有不像(逼)的钢笔吗?
26-1-4 18:53 来自辽宁