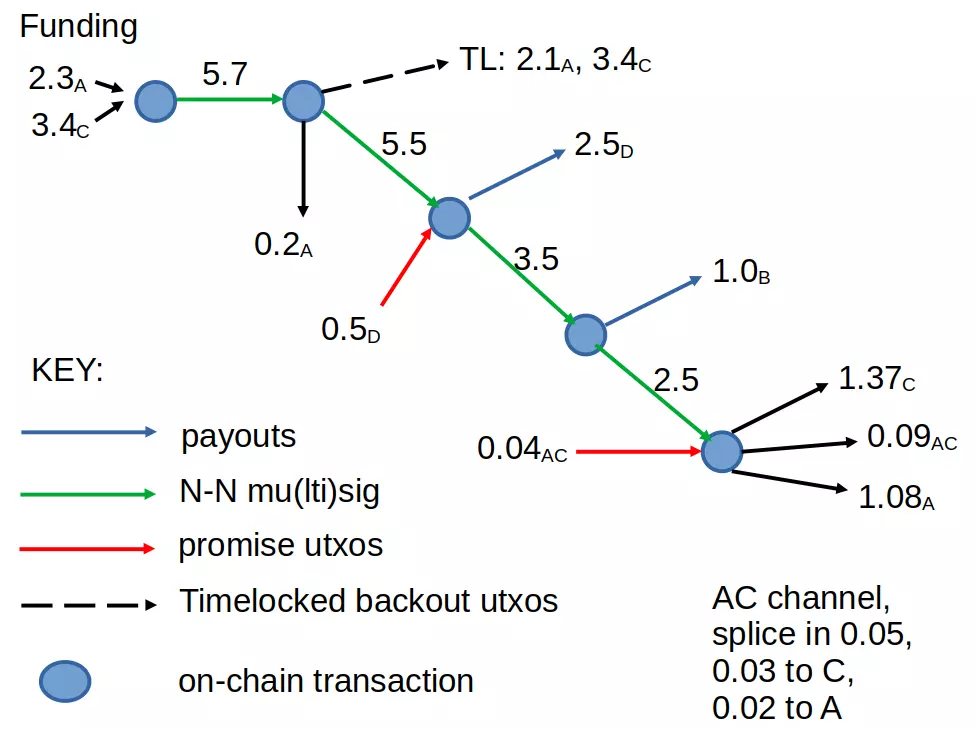
Doesn't it point you to a link that's supposed to help you decide if you're a trader or not?
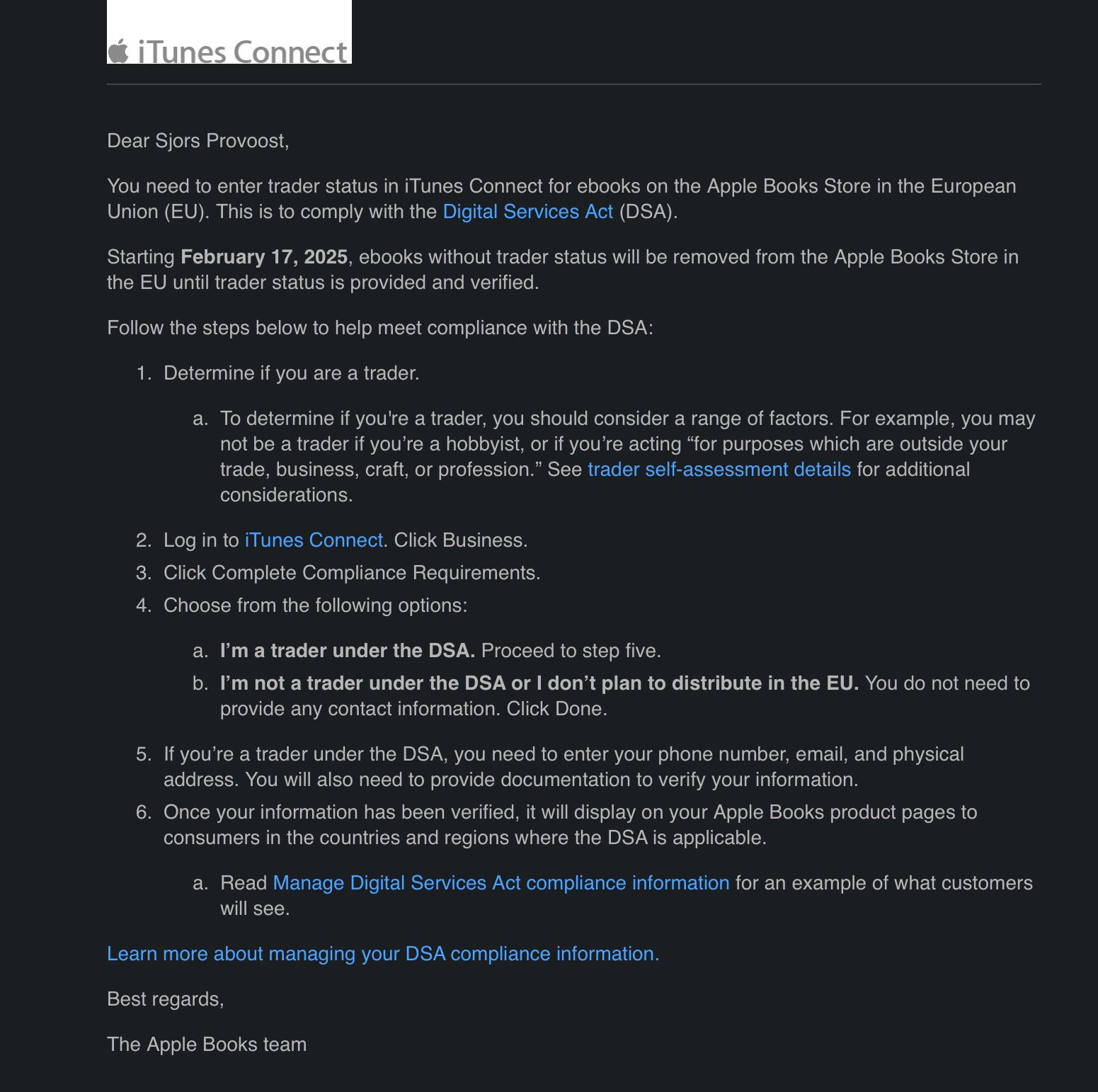
Is what they're saying about the DSA wrong then? I'd honestly never heard of it.
Binance uses zk-SNARKs for proof of solvency, but it made no difference: https://www.binance.com/en/blog/tech/how-zksnarks-improve-binances-proof-of-reserves-system-6654580406550811626
I like aut-ct, though I believe it has different use cases. In fact, I recently mentioned it in this thread: https://delvingbitcoin.org/t/proving-utxo-set-inclusion-in-zero-knowledge/1142/2
Yes, I did see (at least what's publically written) about Binance. It's not really either clear what you are saying (it didn't make a difference to what, precisely?), nor what the right choice is for each situation. A ZkSNARK nor a bulletproofs or other similar ZKP system won't be needed for the *assets* side of a proof of reserves, *if* you don't care about onchain privacy - which Binance doesn't; they just publish all the onchain addresses. While those systems can help a lot with the trickier proof of liabilities. If you do care about onchain privacy, these systems have tradeoffs; to get a bigger anon set on bitcoin than taproot, you have to address the hashing problem. The original Provisions protocol of Bunz completely sidestepped this problem; with zksnarks you *can* address it but it is quite, quite tough because you have to build multiple non-algebraic hash function circuits. The result is that at the very least, pre-processing takes horrendous amounts of time.
Yeah there's both a cynical and a non-cynical dismissal of my suggestion to Coinbase custody here.
The non-cynical one would mention that the taproot-only restriction is very significant to them (both smaller anon set and disruption of their workflow; for their security measures they'd probably dismiss such a disruption out of hand; don't underestimate how slowly tech processes can change in big institutions). It would also mention that this is only addressing proof of *assets* not liability proofs which has tended to be the much bigger sticking point. For myself, I would find even *just* a proof of assets from entities like Coinbase custody or Bukele, to be a very good thing.
I've written a blog with a proof of being a satoshi millionaire, that does not reveal where my funds are on-chain. Bukele and Coinbase take note pls :)
https://reyify.com/blog/privacy-preserving-proof-of-taproot-assets
I've thought a little about applications to Layer 2s, but not much. It isn't obvious that it could be a part of such a system, like e.g. building proofs and having them verified onchain, such that a person owning funds in an L2 could claim them back on L1, seems decidedly non-obvious, because these proofs, while sharing the same elliptic curve, use a set of generators, not just the 'G' that we use in Bitcoin for our signatures (note: i am framing the problem based on *not* changing bitcoin with a hard or even soft fork; clearly if new verification code was added, then things like bulletproofs could be added, as was envisaged originally for Confidential Transactions, and as is seen in e.g. Liquid/Elements).
On the other hand, yes, indirectly: my motivation for the token idea was, more than anything, a system like Lightning: you have a lot of potential Sybilling problems, for example Lightning uses gossip of *real* "unencrypted" channel opening utxos to identify channels, so that the gossip system doesn't get swamped with fake channels. I believe this is a promising (and maybe even the best) direction to solve that problem; I've had a few brief discussions with some Lightning engineers, but I don't see much interest/traction for it, at least yet.
Lastly I'd say: this is not just interesting to get anonymized tokens on ownership for anti-Sybil; the same technique can be used to publish proof of ownership of assets aggregated over many utxos e.g. "I prove I own 1btc of taproot utxos but I won't show them" is not only possible with this tech; I've already done it, in the same repo. I'm probably going to post such a proof shortly. I think it *could* be of interest for proof of reserves applications, since it preserves privacy but provides irrefutable evidence of onchain funds.
No they aren't, but the conflict he's talking about is very real, and very often overlooked; people like the concept 'censorship resistance requires privacy so that the powers that be can't see what they want to censor', which is true but is also limited in that those powers may try to force communication, or monetary exchange, through channels not private from them.
The dynamic he's talking about is probably best understood by considering the word 'broadcast'.
I don't really understand the basic concept, is there not a write up somewhere?
If the main claim is 1 round signing with nonce preprocessing, how is that different to FROST? That was one of FROST's main claims, that you could optionally do that; it's even in the abstract of the original paper.
Here is Cramer's solution:
The "challenged" does this: choose a random number in 1..1000, r, look up question number r for Komodo dragons and memorize it. The challenger then provides an unpredictable random number in 1..1000, c, and says "give me two answers, one from each list, where the question numbers add up to c modulo 1000. So the challenged calculates c - r (mod 1000) to get r2, which is the number of a question from the Fermat list, which he can immediately provide, along with the r-th Komodo dragon question, and the challenger veries that r + r2 = c mod 1000.
(For anyone interested, this is the extremely elegant solution to how to combine Sigma protocols in OR relations, "first" discovered in CDS-94 (see the first sections of my blog on ring signatures for details: https://reyify.com/blog/ring-signatures )
Yeah basically variants on 'the two answer sets can be 'encoded' and are chosen to have an identical encoding'.
But can you find a way to do it that doesn't require answering a thousand questions? Based on the concept that, if one were challenged to answer one specific question randomly, one is guaranteed to succeed based on knowing all the answers?
No, you succeeded I'd say, that last idea feels like a valid solution ... unless i missed something. I'll post the 'intended' answer later.
Really interesting idea, I like it. Obviously difficult in practice, but the spirit of the idea makes sense, as long as the numbers get large enough.
Nice answer :)
It's a slightly more fun version of, e.g. having a computer program that asks you to enter correct answers and prints out pass/fail, so basically you answer the questions in secret and the challenger sees only the result, and believes that it was executed correctly ... which is pretty reasonable.
(not the intended answer of course; for that no mechanical or digital mechanisms needed).
I don't follow what you're saying.
There's one person claiming to be expert in (komodo OR fermat). There's another, providing the 2 lists of Qs and, for a very limited time, answers.
You can assume that the first person is indeed enough of an expert in one of the 2, that they can easily correctly answer all 1000.
1. No.
2. I think we could be vague on this, but let's keep it concrete: there's only time to memorize 1 answer.
3. In the 'correct' answer to this puzzle, no.
Good questions.
OK, it's a bit underspecified 😄
Say the opponent/challenger also gives a full list of answers to both sets of 1000 questions - but only for 2 or 3 minutes, after which you lose access.
Given that, what protocol could you devise that would convince him that you basically already knew all 1000 answers for 1 of the 2? But not revealing which?
Ronald Cramer in 1997:
"Suppose one were to convince an opponent that one has expert knowledge about Komodo dragons or about the life and times of Pierre de Fermat, without revealing which. One could propose the following protocol..."
... what do you think the protocol is?
As a very minor clue, his proposal involves preparing 2 lists of 1000 questions on each topic.
Ideas?
Adaptors generalise to proofs of representation (which means, I have a point V and I claim knowledge of (x1, x2,..) such that V = x1 G1 + x2G2 + ..); and that's unsurprising, because sigma protocols can be built over any homomorphism.
For a concrete example, consider pedersen commitment C = aG + bH. You can prove knowledge of the opening using exactly the same paradigm as a schnorr signature, and that's because, just as for proving knowledge of a single DL, we have (x + y)G = xG + yG, so here also, C1 + C2 commits to the two tuple (a1+a2, b1+b2). I wrote this in a short blog post here: https://reyify.com/blog/homework-answer-advancing-2022
So, for a general case with N bases, and proving representation, the analog of the one-dimensional adaptor is a tuple; write tuples as (x) .Then we have (s)', a list of N scalar s-values.
so you'd write something like this : s_1' G1 + s_2'G2 + s_3'G3 = R + H(R+T, V)V to correspond with the full signature-tuple s: s_1 G + s_2 G2 + s_3 G3 = R + T + H(R+T, V)V.
and in analog, again, revealing the tuple (s), reveals the tuple (t). Note that that works because for *every* index (from 1 to N) you can do t_i = s_i - s_i'
Is this useful? I think one specific way of using it is, but still trying to flesh it out. The idea is this:
To construct full sigma protocols (and somehow have them verified onchain), you need to use proofs of representation; it's not enough to just do DLEQs (as per previous post a few days ago). In other words, you need to publish points V and claim you know their representations against a set of bases G_i.
It seems like the trick to making this work, is to create an adaptor tuple where all values are the same; i.e. t1 = t2 = t3 .. in the tuple (t).
Then if you enforce, on chain, that s1 = k1 + t1 + H(R1+T1, V1, msg)V1 (i.e. the pubkey is the first component of the proof of representation), it follows that if, after verifying all the adaptors, s1 is published, then t is revealed and since t1=t2 etc. you "receive" all the s-values in the tuple (s) at the same time.
For now this is a very undeveloped set of ideas, one point is that you are revealing one component of your representation (x1 G1), whereas usually you should reveal none, but my intuition is that this is the least of the problems to address here :)