OpenAI的野心:从生成文本到自制芯片,啥都要搞!
在人工智能界,OpenAI一直以其强大的模型和创新能力著称。但这一次,他们似乎不满足于仅仅生成文本和图像——他们竟然开始自己做芯片了!真是“文能提笔安天下,武能上马定乾坤”。
1. “自给自足”:
- OpenAI推出了首款芯片,采用TSMC的1.6nm技术,为其AI视频生成工具Sora量身定制。
- 看来OpenAI已经不再满足于软件层面的领先地位,硬件也要自己搞了。大概是觉得别人家的芯片都配不上他们的AI吧?
2. “性能提升”:
- 利用A16工艺,这款芯片提供了显著的性能改进,包括8-10%的速度提升和15-20%的功耗降低。
- 真是厉害,这速度提升和功耗优化,难道下一步是要挑战特斯拉和苹果了吗?
3. “减少依赖”:
- OpenAI希望通过自主研发芯片减少对外部AI芯片的依赖,尽管目前仍处于开发初期,还面临产能和技术挑战。
- 这就是所谓的“家里有矿”吧?什么都自己干,不怕成本高,就怕没挑战。
看来,在未来,不论是生成文本、生成图像还是制造硬件,我们都可以期待OpenAI带来更多惊喜。毕竟,他们的目标不仅是改变世界,而是全面接管各个领域! 
智能AI客服新纪元:Claude客户支持代理详解
在一个充满技术与智能的未来办公室里,企业的客户支持工作正发生着革命性的变化。通过整合Anthropic的Claude模型与亚马逊Bedrock,企业能够提供更为高效和个性化的客户支持服务。这张图表展示了如何一步步实现这一切,从设置到部署,每一个环节都在为打造卓越的客户体验而设计。
1. AI Chat:
- 解读: 由Anthropic的Claude模型驱动,提供智能对话功能。
- 场景: 客服机器人能流畅地与用户交流,回答问题并提供帮助。
2. Knowledge Retrieval:
- 解读: 整合了亚马逊Bedrock,用于上下文知识检索。
- 场景: 系统能快速查找并提供相关信息,使得回答更为精准。
3. Real-Time Debugging:
- 解读: 显示思考过程和调试信息。
- 场景: 实时展示系统处理过程,方便技术进行调试和优化。
4. Knowledge Source Visualization:
- 解读: 显示知识来源。
- 场景: 用户可以看到答案从何而来,增加透明度和信任感。
5. User Mood Detection:
- 解读: 根据检测到的情绪引导用户。
- 场景: 系统能识别用户情绪,并做出相应调整,如转接到真人客服。
6. Customizable UI:
- 解读: 使用shadcn/ui组件进行高度自定义。
- 场景: 企业可以根据品牌需求定制界面风格和功能布局。
7. Setup:
- 解读: 包括克隆代码库、安装依赖、配置环境变量及运行服务器。
- 场景: 技术人员快速搭建系统环境,准备上线。
8. Configuration:
- 解读: 设置.env.local文件,配置API及访问密钥(Anthropic和AWS)。
- 场景: 确保系统能正确连接并使用外部服务。
9. Knowledge Base Setup:
- 解读: 在亚马逊Bedrock中创建并索引文档,用于增强检索生成(RAG)。
- 场景: 构建全面的知识库,提高系统应答准确性。
10. Model Switching:
- 解读: 支持多个Claude模型,可通过UI切换。
- 场景: 根据不同需求或优化目标灵活切换模型。
11. UI Components:
- 解读: 修改组件、主题和布局,通过代码及样式文件实现。
- 场景: 调整UI细节,提升用户交互体验。
12. Deployment:
- 解读: 使用AWS Amplify进行部署,配置环境变量和服务角色。
- 场景: 快速将系统上线,并确保其稳定运行。
13. Flexible Configurations:
- 解读: 通过环境变量和NPM脚本,为不同构建模式包含或排除UI侧边栏。
- 场景: 根据实际应用需求灵活调整系统功能模块。
14. Disclaimer:
- 解读: 项目是原型,不适用于生产环境,无任何担保或保证。自行承担风险使用。
- 场景: 提醒用户该项目仍处于测试阶段,不宜用于正式业务运营。 
电动汽车动力系统对比:锂离子电池 vs 氢燃料电池
这张图表详细展示了锂离子电池(Lithium Ion Battery)和氢燃料电池(Hydrogen Fuel Cell)在电动汽车中的工作原理及其主要区别。
锂离子电池电动汽车(BEV)
- 储存电力:BEV包含一个大型电池来储存电力。
- 车载充电器:将交流电转换为直流电,为电池充电。
- 驱动电机:使用储存在电池中的能量驱动车辆前进。
锂离子电池工作原理:
- 通过锂离子在负极(阳极)和正极(阴极)之间移动来产生电流。
- 充放电过程:锂离子在充放电时在两个极板之间往返移动。
氢燃料电池汽车(FCEV)
- 氢气储罐:储存高压氢气,液态氢因需要超低温而不能使用。
- 排气系统:唯一的废弃物是水。
- 驱动电机:使用由燃料电池堆产生的能量驱动车辆前进。
氢燃料电池工作原理:
- 燃料电池将氢气和氧气结合以产生电力。
- 反应过程:
- 氢气分解成质子和电子,质子通过膜到达阴极,电子则经过外部回路产生电流。
- 最终,质子与氧气结合生成水并通过排气系统排出。
续航里程对比
- 最长续航的BEV是2022年的Lucid Air Dream Edition,EPA评级为505英里。
- 最长续航的FCEV是2022年的Toyota Mirai XLE,EPA评级为402英里。 
GPT模型进化与扩展规律分析
此图展示了从GPT-3到GPT-5模型的演进过程及其扩展和优化规律,强调了在评估模型规模增长时不应仅依据个别进展来判断。
1. 模型扩展(Scaling):
- 随着时间的推移,GPT模型经历了显著的扩展。例如,从GPT-3到GPT-4,再到未来的GPT-5,每一代模型在规模上都有显著增加。这种扩展是通过增加模型参数和训练数据量来实现的。
2. 优化过程(Optimization):
- 在每一代大型模型之间,存在多个优化版本。这些版本旨在提高效率和性能,例如从GPT-3到GPT-3.5,再到GPT-3.5-Turbo,以及从GPT-4到GPT-4o、GPT-4o-Mini等。这些优化版本并非单纯增加规模,而是通过改进算法和架构来提升模型表现。
3. 训练周期:
- 大型模型的训练周期大约为1.5至2年,表明新一代模型的开发和推出需要较长时间。因此,在大型训练周期之间,通常会推出优化版本以保持技术的前沿性和市场竞争力。
4. 未来趋势:
- 图中展示了预计在2025年推出的GPT-5,这预示着未来几年内语言模型将继续快速发展,并且每一代新模型都将带来更大的技术突破。
总结而言,此图通过展示不同版本间的扩展与优化过程,揭示了语言模型发展的复杂性和前瞻性。科学地理解这些规律,有助于更好地预测未来AI技术的发展方向。 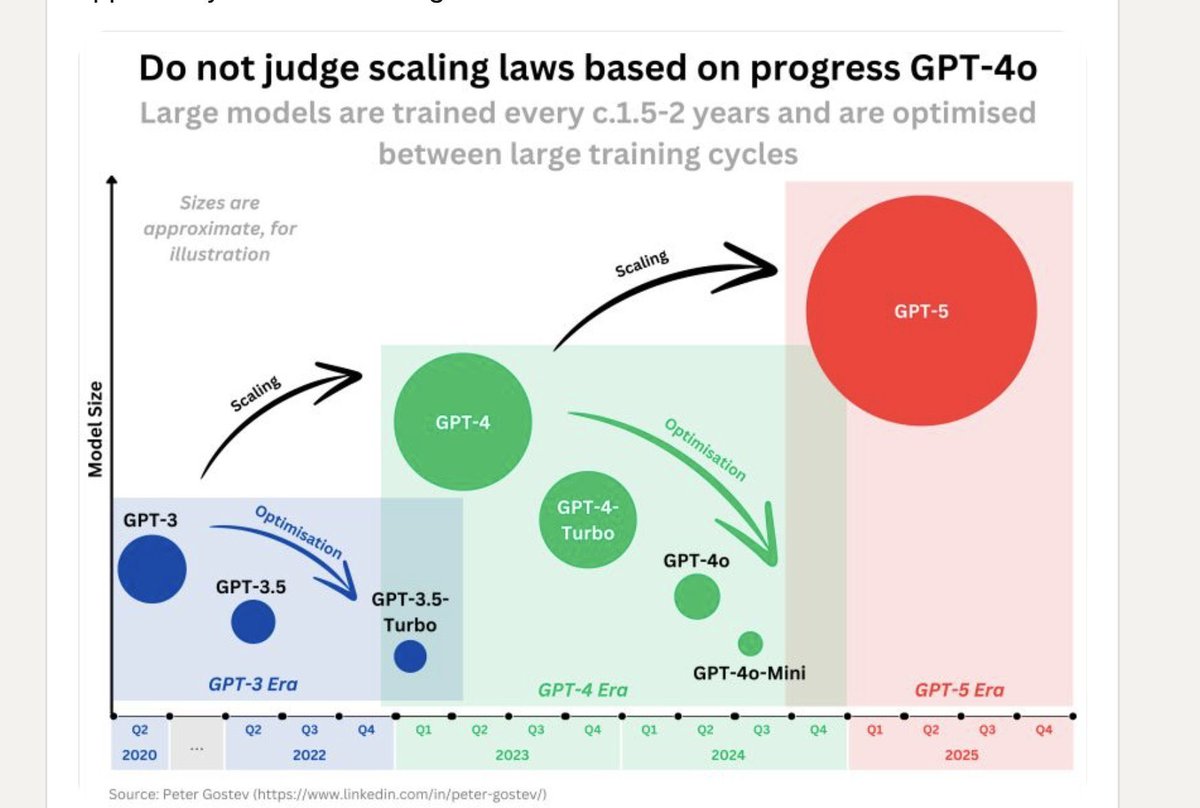
一图看懂SWOT分析
优势 (Strengths):
- 能力和资源:公司具备的各种资源、资产和人员是其竞争优势。
- 市场营销:品牌知名度和市场覆盖面广。
- 创新性:产品或服务具有创新特点。
- 地理位置:地理位置优越,有利于业务发展。
- 性价比高:提供高质量且价格合理的产品或服务。
劣势 (Weaknesses):
- 能力不足:缺乏某些关键能力或资源。
- 声誉问题:品牌知名度和市场影响力不够。
- 财务压力:资金流动性差,现金流紧张。
- 供应链问题:供应链的不连续性影响生产和服务交付。
- 数据可靠性差:计划和项目的数据可靠性不足。
机会 (Opportunities):
- 市场发展:新兴市场的发展带来新的商机。
- 行业趋势:抓住行业或生活方式的趋势可以带来新的增长点。
- 技术创新:科技进步为业务创新提供了可能。
- 全球影响力:全球化带来的跨国合作机会。
- 目标市场扩大:瞄准新的细分市场,扩展业务范围。
威胁 (Threats):
- 政治经济影响:政策变化和经济波动带来的不确定性。
- 环境问题:环保法规和要求增加运营成本。
- 竞争加剧:市场竞争对手增多,导致压力增大。
- 需求波动:市场需求的不确定性可能影响销售业绩。
- 管理策略不足:管理策略不当可能导致公司陷入困境。
通过列举公司内部的优势和劣势,以及外部的机会和威胁,帮助企业全面了解自身状况,并制定相应的战略规划。 
面试高分回答指南
1. 自我介绍
- 提示:提前决定哪些技能和职业亮点最适合这个职位。
- 答案:用个人且有趣的故事展示你的起步、现状以及这个角色是如何成为下一步发展的逻辑选择。
2. 你对这个职位感兴趣的原因
- 提示:提前研究公司和职位,找出你喜欢的具体方面,如使命、文化、客户等。
- 答案:具体说明你希望产生的影响以及你的技能如何契合。
3. 你的优势是什么
- 提示:提前决定哪些优势最符合职位要求。
- 答案:重点突出2到3个优势,并用难忘的成功故事来支持。
4. 谈谈你失败的一次经历,你是如何处理的
- 提示:展示你谦逊、有韧性并注重成长。
- 答案:讲述一个你迅速恢复并从中学习的失败故事,然后继续前进。
5. 描述一次你激励他人的经历,你是怎么做到的
- 提示:即使你不是领导,他们也想看到你对情境和人际关系的定制化方法。
- 答案:突出一个你积极、坚定且具有说服力的时候。
6. 描述一次你同时处理多个项目的经历,你是怎么做到的
- 提示:关注你的时间管理和可靠性。
- 答案:举例说明你使用可重复系统的方法,优先处理任务、管理时间、委派任务并提供定期更新。
7. 描述一次你在工作中经历重大变革的情况,你是如何适应的
- 提示:雇主希望看到那些对变化感到兴奋的人,而不仅仅是容忍变化的人。
- 答案:讲述一个直接影响你的变化故事,并说明你如何迅速调整;如果能让其他人也接受这种变化,更好。
8. 谈谈一次为自己设定目标并实现它的经历
- 提示:展示你如何完成任务,设定明确目标并跟进。
- 答案:举例说明一个成功实现目标的方法,将目标分解为小步骤,每天取得进展,并克服挑战。
9. 与上司或同事意见不一致时的例子,结果如何
- 提示:永远不要说对方坏话(面试官可能会想象自己)。
- 答案:选择一个当时有有效案例,沟通清晰并达成积极解决方案的时候。
10. 你的弱点是什么
- 提示:“我太在乎了”这种陈词滥调不要用——这关乎自我觉察。
- 答案:描述1到2个与你工作无关紧要但正在努力改进的弱点。
11. 任何问题要问我吗?
- 提示: 这是几乎保证会被问到的问题——不要沉默。
- 答案: 提出一些表明您已经研究过公司的问题(例如: “在该角色的前6个月内成功会是什么样子?”)。
12. 有什么我们没有讨论到的吗?
- 提示: 不要说“没有”! 在面试前, 想一想您在整个面试过程中想传达给公司的3个主要要点.
- 答案: 利用这段时间重申这些.
通过这些通俗易懂的回答技巧,你可以在面试中更加自信地展示自己,增加拿到心仪工作的机会。 
这些食物焯水更健康
1. 含草酸食物:
- 菠菜、苋菜、空心菜、茭白、竹笋:这些蔬菜含有较高的草酸,焯水可以有效去除草酸,减少其对人体钙质吸收的影响。
2. 有毒素食物:
- 豆角、四季豆、扁豆、荷兰豆、黄花菜:这些食物中含有一定的毒素,焯水能够破坏毒素结构,保证食用安全。
3. 含亚硝酸盐食物:
- 香椿、茼蒿、蕹菜(空心菜)、芥蓝(芥菜)、苋菜:这些蔬菜中可能含有亚硝酸盐,焯水可以降低其含量,减少对人体的危害。
4. 血腥味重的食物:
- 鸡肉、牛肉、排骨、羊肉、动物内脏:这些肉类及内脏在烹饪前焯水,可以去除血腥味及部分杂质,使口感更加鲜美。
通过焯水处理,这些食物不仅更加安全,还能提升口感和营养价值,是健康饮食的重要一环。 
信用卡的工作原理详解
1. 全息图 (HOLOGRAM):3D图像,用于辨别伪造卡片。
2. EMV芯片 (E.M.V.):生成唯一代码进行身份验证。
3. 首4-8位数字 (FIRST 4-8 DIGITS):标识发卡银行和支付网络(如Visa、Mastercard等)。
4. CVV码 (CVV):卡片验证值,增加在线支付的安全性。
5. 下一组数字 (NEXT FEW DIGITS):标识个人银行账户和卡片信息。
6. 校验位 (CHECK DIGIT):最后一位数字,用于检测输入错误。
7. 磁条 (MAGNETIC STRIPE):使刷卡交易成为可能。
8. 有效期 (VALIDATION):表示卡片的有效期限。
这张图清晰地展示了信用卡各个部分的功能和作用,帮助我们更好地理解信用卡的工作机制。 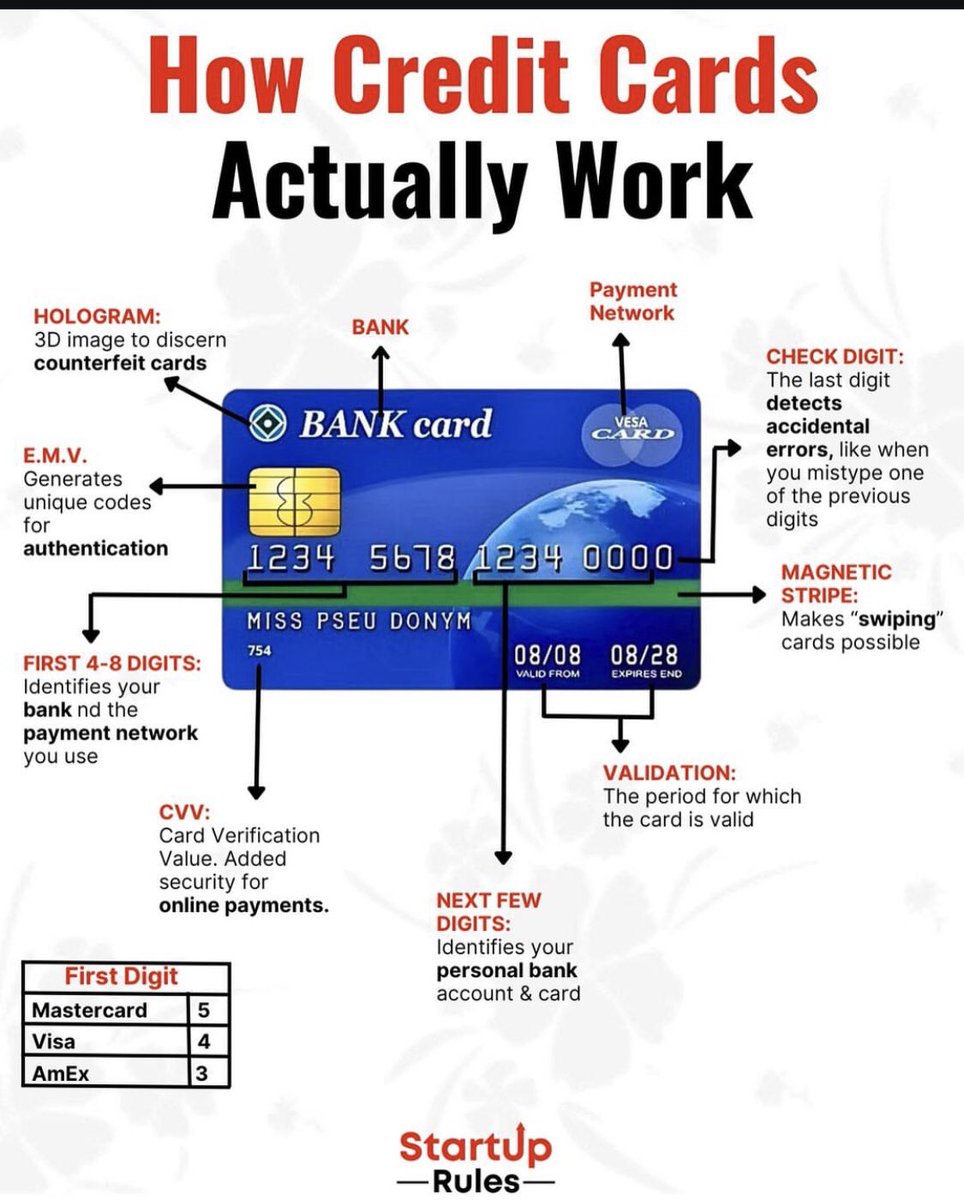
职场老司机的十条“偷懒”秘籍
1. 制定每周计划 - 让你每天都有方向感,绝不迷路!
2. 关掉手机 - 远离刷屏陷阱,专注力爆棚!
3. 不做多任务处理 - 一心一意才能干大事,别当“杂技演员”!
4. 优先处理重要任务 - 抓住“大鱼”,小虾米以后再说!
5. 保持整洁有序 - 桌面清爽,思路更清晰!
6. 用结果衡量,而非时间 - 效率高才是王道,不要做“时间奴隶”!
7. 建立并坚持日常习惯 - 稳定的节奏才能走得更远!
8. 开始的事情一定要完成 - 半途而废可不酷!
9. 定期休息 - 放松一下,再战斗力满满!
10. 自动化你的工作 - 机器帮忙,省时省力,你也能偷个懒!
看完这些秘诀,让你在职场中轻松成为效率达人! 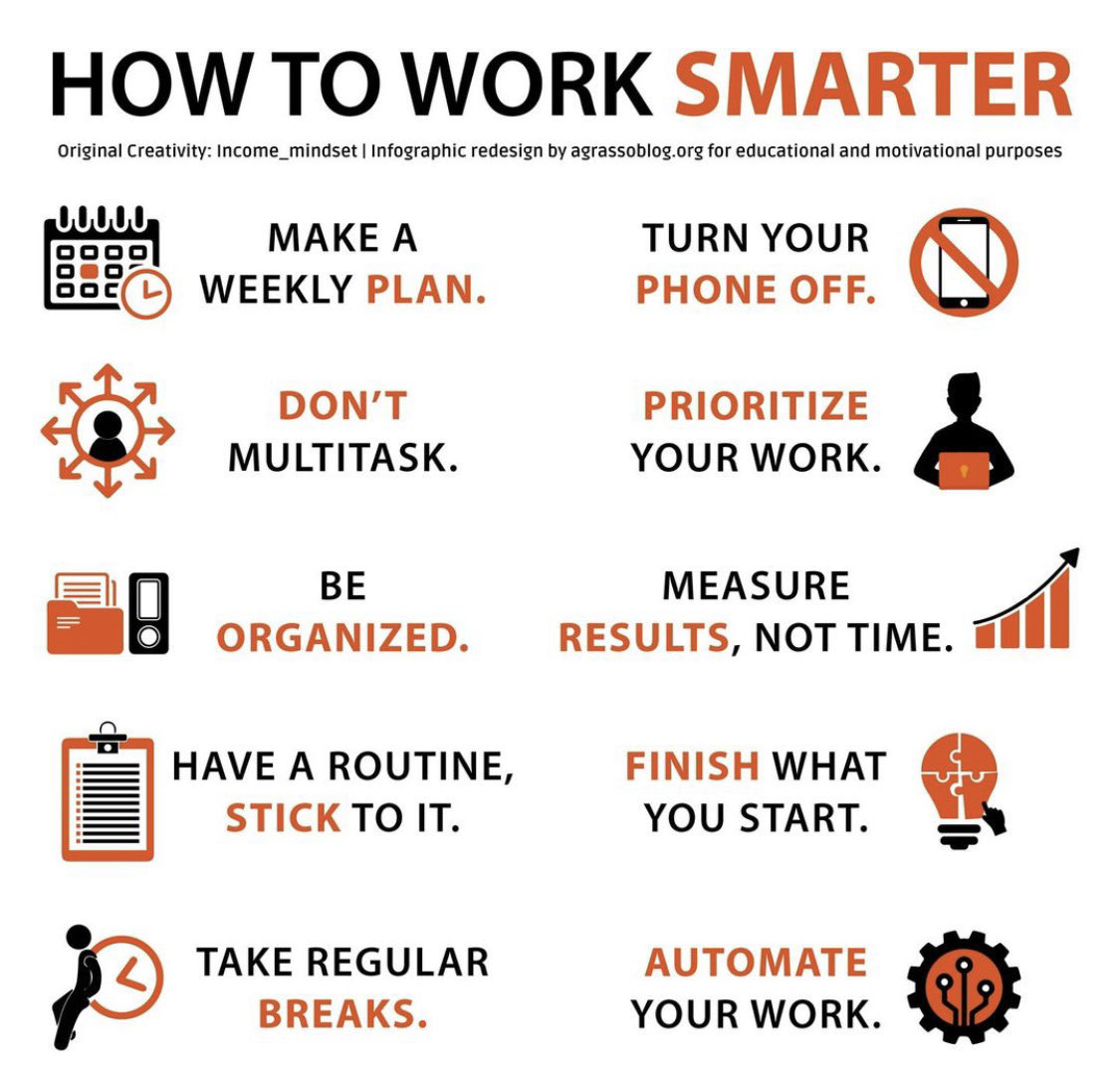
一图读懂深度学习:核心技术与应用的全景解密
这张图是关于深度学习(Deep Learning)的一个示意图,展示了各种概念和它们之间的联系。以下是对这张图的解读:
1. 节点和连线:
- 图中的圆点(节点)代表了不同的深度学习概念或技术。
- 节点之间的连线代表了这些概念或技术之间的关系和互动。
2. 颜色区分:
- 不同颜色的节点和连线可能代表不同类别或主题。例如,蓝色可能表示一种技术,红色表示另一种技术。
3. 主要概念:
- 图中较大的节点通常是一些核心概念,比如神经网络(Neural Networks)、卷积神经网络(Convolutional Neural Networks, CNNs)、循环神经网络(Recurrent Neural Networks, RNNs)等。
- 这些核心概念会连接到一些更具体的子概念或应用。
4. 具体应用:
- 一些节点可能代表具体的应用领域,比如图像识别、自然语言处理、语音识别等。
- 这些应用领域往往会依赖于多个核心技术和方法。
5. 方法与算法:
- 图中也可能有很多表示特定算法或方法的节点,比如梯度下降(Gradient Descent)、反向传播(Backpropagation)等。
- 这些算法是实现深度学习的重要工具。
6. 数据与训练:
- 深度学习依赖大量的数据进行训练,所以你可能会看到一些节点和连线与数据处理、数据增强等相关。
7. 模型评估与优化:
- 图中还可能有一些节点表示模型评估的方法,比如交叉验证(Cross-Validation),以及模型优化的方法,比如超参数调优(Hyperparameter Tuning)。
总体而言,这张图展示了深度学习领域内各种技术、方法、应用之间复杂而紧密的关系。通过这种图示,可以帮助我们理解深度学习体系的全貌,以及各部分之间是如何协同工作的。 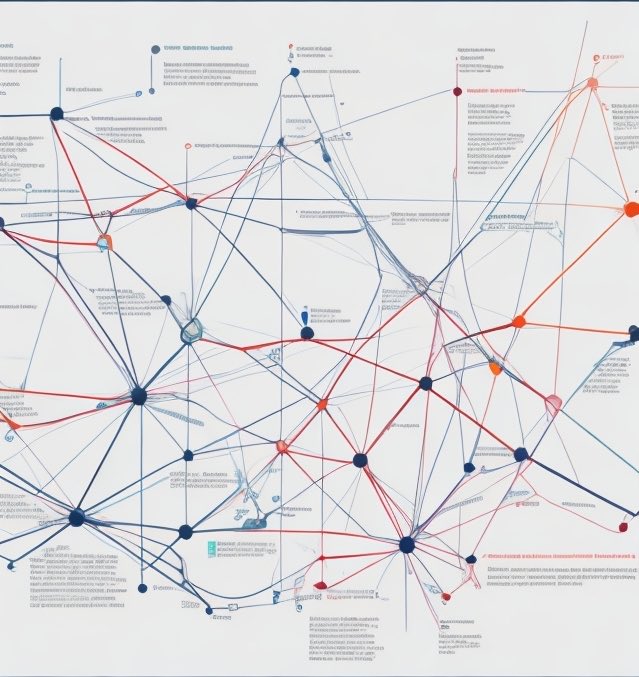
食物作为药物——通俗的解读
这张图展示了某些食物对人体特定部位的健康益处,以下是详细解读:
1. 核桃(Walnut) - 大脑(Brain):
- 核桃富含Omega-3脂肪酸,有助于提高大脑功能和记忆力。
2. 胡萝卜(Carrot) - 眼睛(Eyes):
- 胡萝卜富含β-胡萝卜素,可以转化为维生素A,有助于保护视力。
3. 蘑菇(Mushroom) - 耳朵(Ears):
- 蘑菇富含维生素D,能帮助维持听觉健康。
4. 葡萄(Grape) - 肺(Lungs):
- 葡萄中的抗氧化剂有助于保持肺部健康。
5. 柑橘类水果(Citrus) - 乳房(Breasts):
- 柑橘类水果富含维生素C和抗氧化剂,有助于降低乳腺癌的风险。
6. 番茄(Tomato) - 心脏(Heart):
- 番茄中的番茄红素有助于降低心血管疾病的风险。
7. 芹菜(Celery) - 骨骼(Bones):
- 芹菜富含维生素K和钙,有助于骨骼健康。
8. 姜(Ginger) - 胃(Stomach):
- 姜具有抗炎和消化促进作用,有助于缓解胃部不适。
9. 红豆(Kidney Bean) - 肾脏(Kidney):
- 红豆富含纤维和蛋白质,有助于肾脏功能的维护。
10. 红薯(Sweet Potato) - 胰腺(Pancreas):
- 红薯富含β-胡萝卜素,有助于胰腺健康并调节血糖水平。
11. 鳄梨/牛油果(Avocado) - 子宫(Uterus):
- 鳄梨富含叶酸,有助于女性生殖健康,特别是孕期妇女。
12. 橄榄(Olive) - 卵巢(Ovaries):
- 橄榄中的单不饱和脂肪酸有助于保持卵巢健康。
这张图通过形象的方式展示了食物对人体不同部位的益处,提醒我们饮食与健康之间的密切关系。通过合理饮食,我们可以更好地维护身体各个器官的健康。 
如何让大脑更好地记住信息?——简单易懂的解读
这张图详细解释了大脑如何存储和处理信息。以下是通俗易懂的解读:
信息存储的位置
1. 海马体(Hippocampus):负责将短期记忆转化为长期记忆,还参与空间导航。
2. 小脑(Cerebellum):管理运动技能和协调性。
3. 杏仁核(Amygdala):与情绪和情感记忆密切相关,特别是恐惧和愤怒。
4. 基底神经节(Basal Ganglia):控制运动以及程序性记忆(比如骑自行车)。
大脑皮层区域
1. 额叶(Frontal Lobe):进行决策、解决问题和计划,是工作记忆的关键部位。
2. 颞叶(Temporal Lobe):处理听觉信息,并在语言理解和语义记忆中起重要作用。
3. 顶叶(Parietal Lobe):处理感官信息,涉及空间意识和导航。
4. 枕叶(Occipital Lobe):主要负责视觉处理。
信息如何被存储
1. 短期记忆(STM):包含情感系统和运动系统,处理当前需要的信息,但存储时间短。
2. 工作记忆(Working Memory):整合短期记忆信息,用于理解和学习新内容。
3. 长期记忆(LTM):分为显性记忆(包括事件和事实的具体细节)和隐性记忆(包括技能和习惯)。
场景举例
假设你正在学习骑自行车。开始时,你的大脑通过小脑来协调运动技能,通过海马体来将这些新的体验转换为长期记忆。一旦熟练后,这些技能会被基底神经节存储,并且不再需要有意识地去回想如何骑车。
总之,这张图表明了大脑是如何复杂且高效地处理、存储和回忆各种类型的信息。理解这些过程可以帮助我们更有效地学习和记住重要内容。 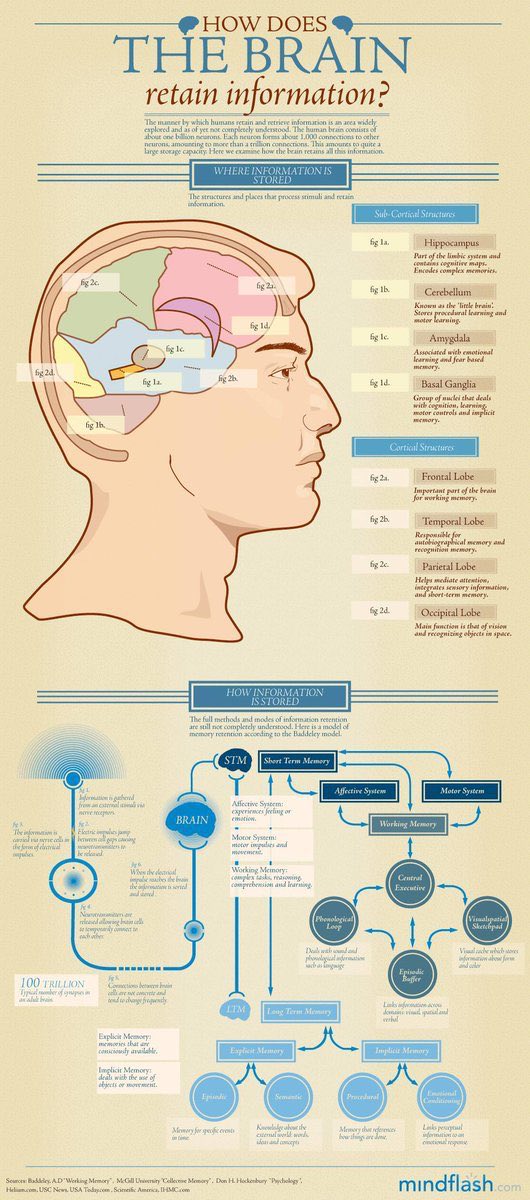
颠覆传统管理:揭秘“创始人模式”的高效秘诀!
根据https://t.co/St5O59mmxt分析,Paul Graham的文章《创始人模式》在硅谷创投圈引起广泛关注。以下是文章的详细总结:
文章核心内容:
1. 创始人模式 vs 经理人模式:
- 创始人模式强调创始人亲自参与各个层面的决策和运营,而非依赖职业经理人。
- 传统的经理人模式通常适用于大公司,但对初创企业可能并不理想。
2. 具体实践:
- 制定明确的公司路线图,创始人在每个版本中都要参与编辑。
- 取消中间管理角色,领导者需像创始人一样运作。
- 严格评估每一个指标,去除一厢情愿的想法,专注于真正重要的事项。
3. 实际效果:
- 实施创始人模式后,公司增长速度加倍,年度支出减少70%。
- 整体能量水平达到新高。
4. 挑战传统智慧:
- 传统观念认为扩大公司规模需要切换到经理人模式,但创始人的实践证明这可能不适合初创企业。
- 强调灵活性和直接沟通的重要性,不拘泥于传统层级结构。
5. 长期展望:
- 预计未来几年内,“创始人模式”将像“经理人模式”一样被广泛理解和接受。
- 创始人模式可能会更复杂,但也更有效。
总结来说,这篇文章提倡初创企业采用“创始人模式”,鼓励创始人深度参与公司的各项事务,以实现更高效、更快速的发展。
全球经济大揭秘:谁是百万亿美元经济体中的“重量级选手”?
今天我们来看看全球经济的“重量级选手”们,也就是哪些国家在2022年的GDP(国内生产总值)最高。通过这张图,我们可以一目了然地看到各个国家的经济实力。
1. 美国 - $25.3万亿
- 情况:美国依然是全球最大的经济体,GDP高达25.3万亿美元!
- 解读:美国在科技、金融、服务业等多个领域都处于领先地位,这让它成为全球经济的领头羊。
2. 中国 - $19.9万亿
- 情况:紧随其后的是中国,GDP为19.9万亿美元。
- 解读:中国的制造业和快速发展的科技产业使其成为全球第二大经济体,而且预计到2030年,中国的GDP将超过美国。
3. 日本 - $4.9万亿
- 情况:日本以4.9万亿美元位居第三。
- 解读:作为亚洲的重要经济体,日本在汽车、电子产品等领域有着强大的影响力。
4. 德国 - $4.3万亿
- 情况:德国是欧洲最大的经济体,GDP为4.3万亿美元。
- 解读:德国以其强大的工业基础和制造业闻名,是欧洲经济的引擎。
5. 印度 - $3.3万亿
- 情况:印度以3.3万亿美元位列第五。
- 解读:印度快速发展的IT行业和庞大的人口红利使其成为全球增长最快的经济体之一。
6. 英国(UK) - $3.4万亿
- 情况:英国的GDP为3.4万亿美元。
- 解读:尽管经历了脱欧,但英国依然是金融和服务业的重要中心。
7. 法国 - $2.9万亿
- 情况:法国以2.9万亿美元位列第七。
- 解读:法国在奢侈品、航空航天和农业方面具有很强的竞争力。
8. 加拿大 - $2.2万亿
- 情况:加拿大的GDP为2.2万亿美元。
- 解读:加拿大丰富的自然资源和稳定的政治环境使其成为北美的重要经济体。
9. 韩国(S.Korea)和俄罗斯(Russia)分别为1.8 万亿美元
- 韩国和俄罗斯各自拥有1.8 万亿美元的 GDP
- 解读: 韩国以其高科技产业和文化输出闻名,而俄罗斯则凭借其丰富的能源资源占据重要位置
你要投资或者去不同国家旅游:
1. 如果你想要一个充满机遇的地方,美国和中国都是不错的选择,这里有发达的市场和众多机会。
2. 想体验高科技生活?去日本或者韩国,这里有最先进的电子产品和技术应用。
3. 喜欢艺术与美食?那就去法国吧,这里有世界一流的博物馆、美食餐厅和奢侈品店。
4. 如果你看重稳定性和自然风光,加拿大绝对是不二之选,这里的自然资源丰富,政治环境也非常稳定。 
全球空调普及率大揭秘:美国、日本领先,欧洲竟然只有10%!
今天我们来看看全球各国空调普及率的地图。这张图展示了各个国家和地区家庭中安装空调的比例,有些数据真的让人惊讶!
1. 美国 - 90%
- 情况:美国几乎每家每户都有空调,占全球总制冷能力的40%!
- 解读:在美国,空调几乎是标配,不论是炎热的夏天还是寒冷的冬天,都离不开它。
2. 日本 - 91%
- 情况:日本的家庭空调普及率高达91%,而且每人平均购买空调的数量全球最高。
- 解读:日本人在享受舒适生活方面可谓不遗余力,几乎每个房间都有一台空调。
3. 韩国 - 86%
- 情况:韩国也不甘示弱,86%的家庭都装有空调。
- 解读:韩国人对舒适度的追求也非常高,不管是夏天还是冬天,温度都要恰到好处。
4. 沙特阿拉伯 - 63%
- 情况:沙特阿拉伯有63%的家庭安装了空调,70%的电力消耗都用于制冷。
- 解读:在沙特这种极端炎热的气候下,空调简直就是生命线。
5. 中国 - 60%
- 情况:中国60%的家庭安装了空调,并且预计到2050年,中国将推动全球一半以上的制冷能源需求增长。
- 解读:随着经济发展和生活水平提高,中国人越来越注重居住环境的舒适性。
6. 墨西哥和巴西 - 各16%
- 情况:墨西哥和巴西只有16%的家庭安装了空调,但墨西哥却有最高比例的与制冷相关的二氧化碳排放。
- 解读:尽管普及率不高,但墨西哥对环境影响较大,这或许与他们使用的制冷设备能效有关。
7. 欧洲 - 10%
- 情况:欧洲仅有10%的家庭装有空调。
- 解读:由于气候相对温和,加上环保意识强烈,欧洲人对空调需求较低。
8. 南非和印度尼西亚 - 各6%和9%
- 情况:南非只有6%,印度尼西亚为9%。
- 解读:这些地区可能因为经济水平或气候原因,对空调需求较少,但未来需求增长潜力巨大。
9. 印度 - 5%
- 情况:印度仅有5%的家庭装有空调,但预计到2050年将推动全球一半以上的制冷能源需求增长之一。
- 解读:印度市场潜力巨大,未来可能会迎来爆发式增长。
假设你在夏天去不同国家旅游:
1. 在美国或者日本,你几乎不用担心热得出汗,因为无论是酒店、商场还是出租车都有强劲的空调。
2. 在欧洲旅行时,你可能需要适应自然风扇或者开窗通风,因为这里很少看到装有空调的地方。
3. 如果去沙特阿拉伯,不用担心酷暑难耐,因为这里大多数地方都有强劲的中央空调系统。
总之,这张地图不仅展示了各国空调普及率,还反映出不同国家在生活舒适度和环保之间所做出的平衡。希望这次讲解能让大家对全球家用空调市场有一个更清晰、有趣的了解! 
AI是如何“想”出(生成)文字的?通俗解读LLM生成文本的四种策略
今天我们来聊聊人工智能(AI)是如何生成出文字的!其实,AI生成文本就像我们在玩拼字游戏一样,有好几种不同的策略。下面我用简单的例子给大家讲讲这四种策略。
1. 贪心策略(Greedy Strategy)
- 怎么做:每次都选出最可能出现的那个字。
- 打个比方:你在玩拼字游戏时,总是选择分数最高的字母。
- 效果:这样的方法很快,但有时候可能会缺少创意。
2. 多项式采样策略(Multinomial Sampling Strategy)
- 怎么做:根据每个字出现的概率进行随机选择。
- 打个比方:你有一个装满不同颜色球的袋子,每次随机抓一个球出来。
- 效果:结果更有多样性,但也可能不太符合上下文。
3. 梁搜索(Beam Search)
- 怎么做:同时考虑多个选项,逐步筛选出最优组合。
- 打个比方:你和朋友们一起玩拼字游戏,每个人选不同的字,然后大家一起评选哪个组合最好。
- 效果:找到更好的整体解决方案,但计算量较大。
4. 对比搜索(Contrastive Search)
- 怎么做:不仅看当前字,还要防止重复,保证句子多样性。
- 打个比方:你在写作文时,不仅要用好词,还要避免重复使用同一个词。
- 效果:生成更加自然和富有变化的文本。
场景例子:
假设你正在用AI助手写一封邮件,感谢朋友帮忙修电脑。
1. 贪心策略:
- AI会快速给出:“谢谢你帮我修电脑,你真棒!”
2. 多项式采样策略:
- AI可能会随机生成:“谢谢你帮我修电脑,你真的太厉害了!”
3. 梁搜索:
- AI会综合考虑多个表达:“非常感谢你的帮助,我的电脑终于好了,你真是太棒了!”
4. 对比搜索:
- AI不仅考虑到感谢,还避免重复词语:“非常感谢你的帮助,我非常感激你的修复,我现在可以顺利使用我的电脑了!”
通过这些策略,AI能够灵活地生成不同风格、不同语气的文本,以满足各种需求。不管是写邮件、撰写报告还是创作小说,AI都能帮你搞定! 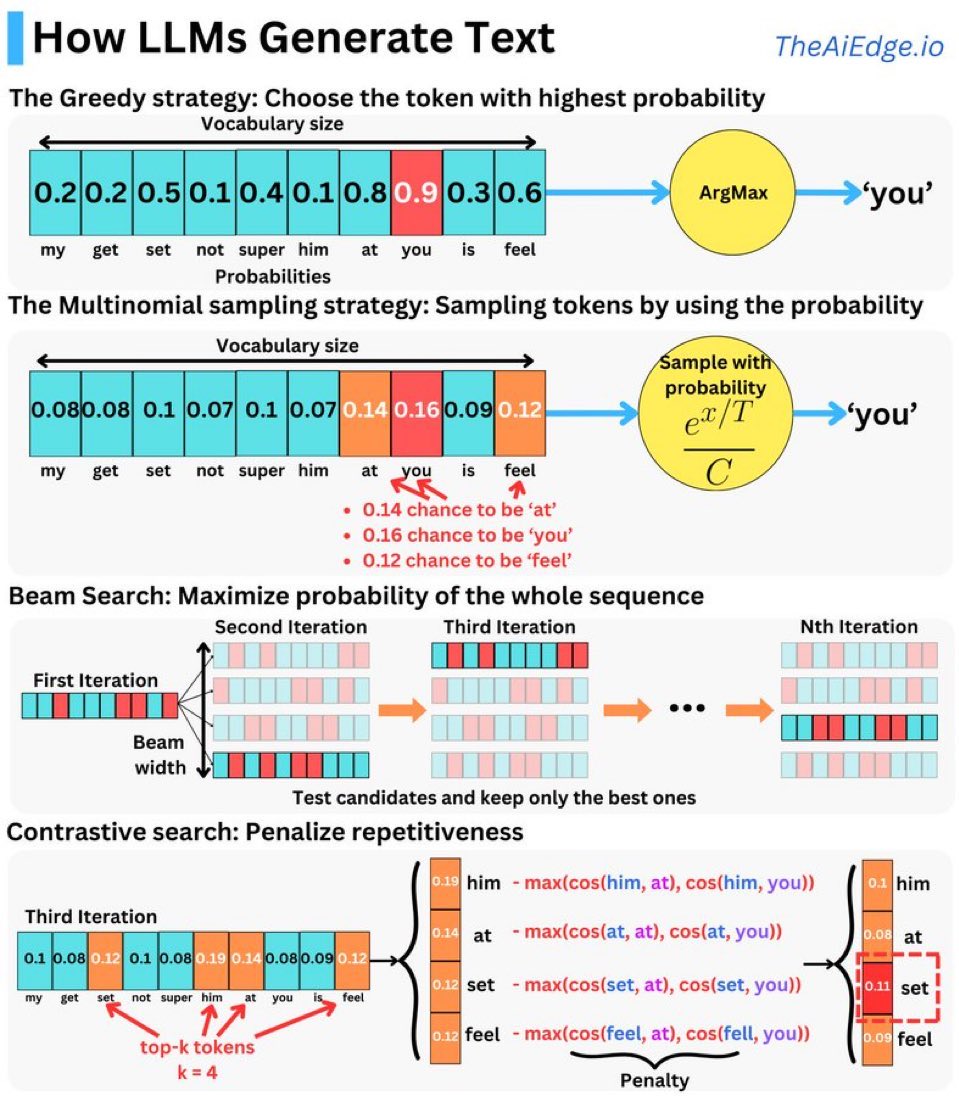
全球ChatGPT狂热:印度拔头筹,美国只排中游!
欢迎来到《全球ChatGPT使用热潮大揭秘》!今天我们要聊聊那些最爱和AI聊天的国家,看看谁是“聊天王者”!
首先,让我们把目光投向榜首——印度!45%的印度人都在和ChatGPT谈天说地,看来大家伙儿都爱这位AI朋友啊!是不是想问天气、股市还是下班去哪儿吃饭,统统找ChatGPT就对了!
紧随其后的是摩洛哥,以38%的使用率位列第二。看来摩洛哥的朋友们不仅爱喝薄荷茶,还特别喜欢和AI唠嗑呢。
阿联酋以34%排在第三,这个被高楼大厦和奢华生活围绕的国家,果然连聊天也要高科技一点。
南美洲也不甘示弱,阿根廷和巴西各自占据32%,足球之国的人们可能在跟ChatGPT讨论战术?
再看看东南亚,印尼、菲律宾也是不遑多让,都在30%左右,看来大家都离不开这个智能助手。
然而,让我们惊讶的是,美国仅以23%屈居中游,这可是创新科技的大本营啊!难道大家都太忙没时间聊天?
再往下看,日本、中国、法国、德国这些科技强国竟然都只有不到20%的使用率,是不是忙着搞别的高科技去了?
最后,我们的泰国朋友们以14%垫底,但我相信这只是个开始,下次榜单上一定能看到他们的进步!
总之,这份榜单告诉我们,不论你在哪个国家,总有一群人在和ChatGPT畅聊人生。无论是查天气、学外语还是解决各种疑难杂症,有事没事找ChatGPT准没错!
好了,这就是今天的全球ChatGPT使用热潮分析,希望大家喜欢!记得多用ChatGPT,它可是你的全天候好伙伴哦! 
据https://t.co/St5O59mmxt分析,Sam Altman的这条推文透露了几项重要信息,具有深远的行业和国家层面的影响。
主要解读:
1. 与美国AI安全研究所达成协议:
- 合作的重要性:这意味着Sam Altman领导的团队(很可能是OpenAI或类似的AI公司)在开发新模型时,将与美国AI安全研究所进行合作。这种合作不仅能确保新模型在推出前经过严格的安全测试,也能提升模型的可靠性和公众信任度。
- 监管合规性:这种合作表明,该公司在积极遵守并推动AI技术的安全和伦理标准,体现了对监管框架和社会责任的高度重视。
2. 国家级别的重要性:
- 美国领先地位:Altman强调,这种合作在国家级别上进行是非常重要的,反映出他对美国在全球AI领域继续保持领导地位的期望。通过这种高层次的合作,美国可以继续在AI技术的发展和应用中处于前沿位置。
- 国际竞争力:在当前全球科技竞争激烈的大背景下,与国家级机构合作有助于增强美国在国际AI市场中的竞争力,防止其他国家在这一领域超越。
潜在影响:
1. 对行业的影响:
- 提高标准:这一举措可能会推动整个AI行业提高安全和伦理标准,从而促使更多企业与类似机构进行合作。
- 技术创新:通过与权威机构合作,新技术可以更快、更安全地推向市场,有助于加速行业整体的发展。
2. 对投资者和企业家的启示:
- 投资机会:这样的公告表明AI领域依然是一个充满潜力的投资方向。尤其是那些能够确保技术安全、合规并得到政府支持的企业,将更具吸引力。
- 战略方向:对于正在或计划进入AI领域的企业家来说,这一消息强调了与政府机构和研究所建立合作关系的重要性,以确保技术发展符合社会需求和法律规范。
总结
Sam Altman宣布与美国AI安全研究所达成协议,不仅展示了他们在推进新模型开发时对安全性的重视,也强调了美国继续保持全球AI领导地位的重要性。这一举措将有助于提升公众对AI技术的信任,同时推动整个行业向更高标准发展,为未来的科技创新提供坚实基础。 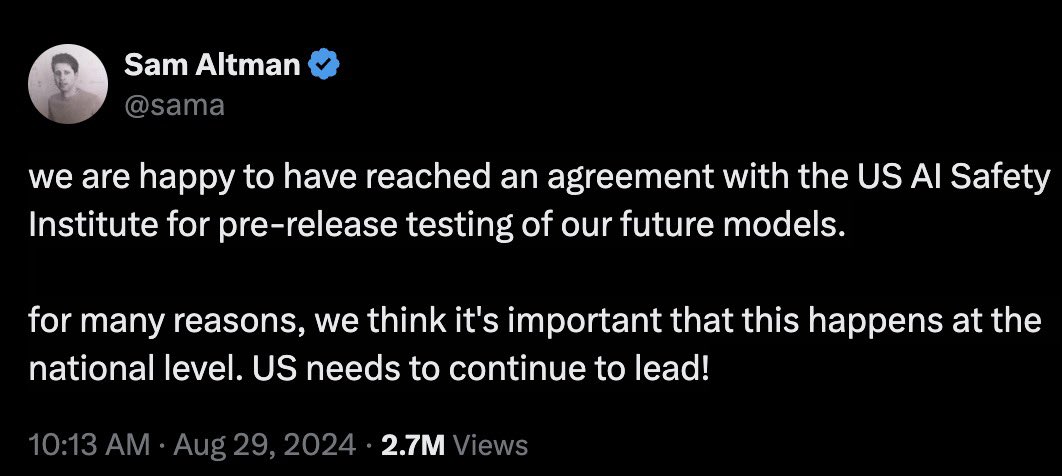
每天步行30分钟的20个好处👍
1. 降低心脏病风险
场景:早晨在公园里散步,享受清新的空气,感受心跳的节奏,让你的心脏更加健康。
2. 帮助维持体重
场景:午休时间绕着办公楼走一圈,帮助燃烧卡路里,保持健康体重。
3. 减少压力水平
场景:下班后在社区附近散步,让忙碌一天后的压力烟消云散,身心得到放松。
4. 增加能量水平
场景:午饭后进行一次短暂的步行,可以让你下午工作时更加精神焕发,不易犯困。
5. 提升情绪
场景:与朋友一起散步聊天,交流生活中的趣事和烦恼,让心情愉快起来。
6. 促进血液循环
场景:每小时起身在办公室走动几分钟,有助于血液循环,防止久坐带来的不适。
7. 防止肥胖
场景:晚饭后和家人一起在小区内散步,不仅消化食物,还能预防肥胖问题。
8. 减轻焦虑
场景:在自然环境中漫步,比如森林或湖边,可以帮助缓解焦虑情绪,找到内心的平静。
9. 提高肺功能
场景:选择空气清新的地方进行晨跑或快走,有助于增强肺部功能,提高呼吸质量。
10. 增加身体对维生素D的吸收
场景:晴天时出门散步,让皮肤接触阳光,有助于身体合成维生素D,促进骨骼健康。
11. 降低癌症风险
场景:定期参加社区组织的健步走活动,通过运动增强免疫力,从而降低癌症风险。
12. 改善睡眠质量
场景:晚上饭后进行适度的散步,有助于放松身心,提高夜间睡眠质量。
13. 提供自我照顾的时间
场景:独自一人在安静的小路上漫步,是思考和反省自我的好时机,为自己提供一些个人空间。
14. 改善协调性和平衡性
场景:参加有氧操或舞蹈课程,通过步伐训练提升身体的协调性和平衡感。
15. 提高生活质量
场景:定期参加户外活动,如登山、远足等,不仅锻炼身体,还能享受美丽的大自然风光,提高生活质量。
16. 降低糖尿病风险
场景:与朋友结伴进行长距离徒步旅行,通过持续运动来调节血糖水平,预防糖尿病。
17. 激发创造力
场景:在城市公园中漫步时思考工作中的难题,新鲜空气和环境变化可以激发你的创造力。
18. 强健骨骼和肌肉
场景】在健身房使用跑步机进行规律性的快走训练,有助于强化骨骼和肌肉力量。
19. 改善血压
【场景】每天饭后进行30分钟的慢跑,可以帮助调节血压,使之保持在正常范围内。
20 .增强免疫系统
【】在家附近的一片绿地上,每天坚持快走30分钟,这不仅锻炼了身体,还能提升免疫系统的功能。 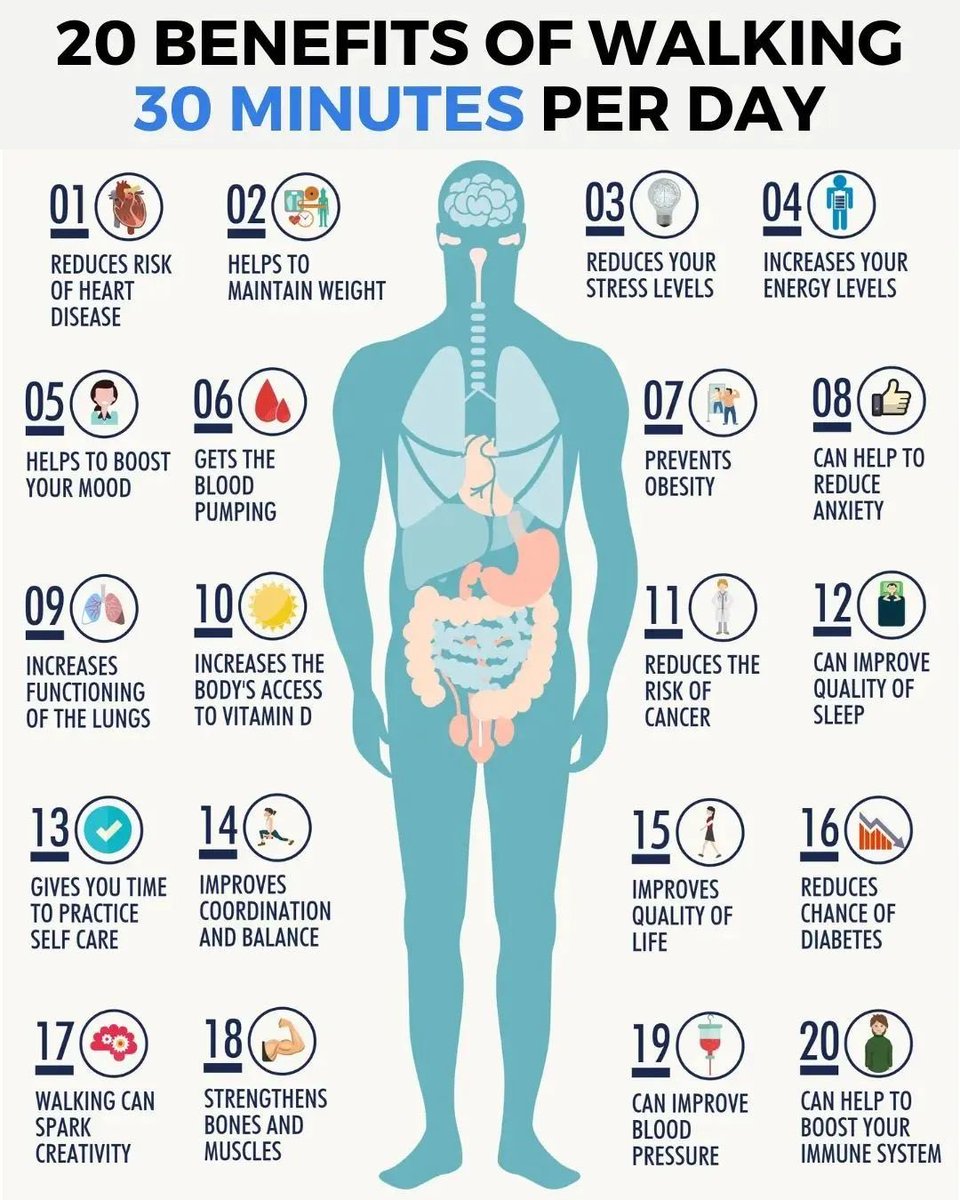
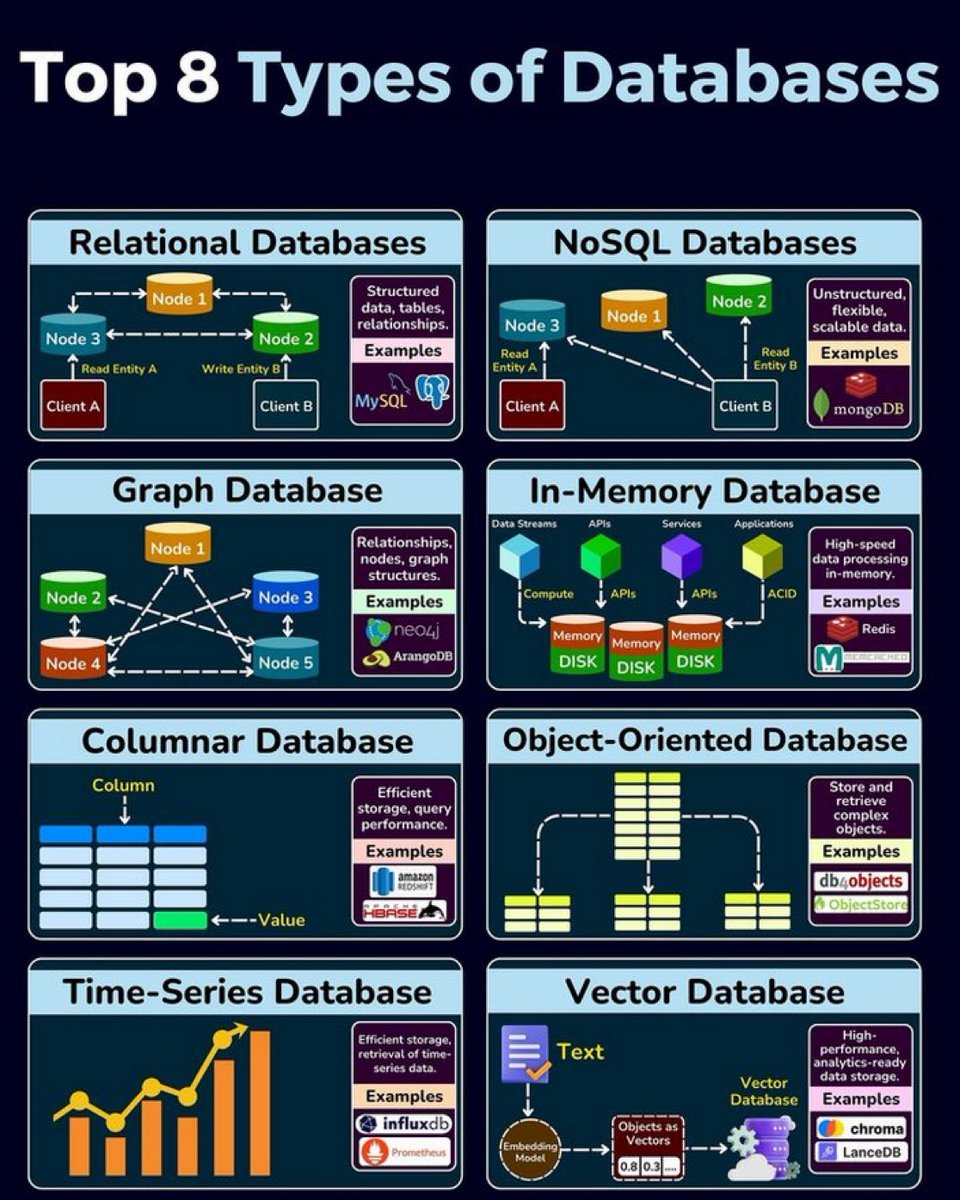
八大类型数据库解读
1. 关系型数据库(Relational Databases)
关系型数据库使用表格来组织和存储数据,每个表格由行和列组成。数据之间通过外键等方式建立关系,适用于结构化数据的存储和查询。
示例:MySQL、PostgreSQL
2. NoSQL数据库(NoSQL Databases)
NoSQL数据库不使用传统的表格结构,而是采用文档、键值对、列族或图形等方式存储数据。它们更加灵活,适用于处理大量非结构化或半结构化的数据。
示例:MongoDB、Cassandra
3. 图形数据库(Graph Database)
图形数据库专门用于存储和处理复杂的关系数据。节点代表实体,边代表实体之间的关系,特别适合社交网络、推荐系统等场景。
示例:Neo4j、ArangoDB
4. 内存数据库(In-Memory Database)
内存数据库将数据存储在内存中而不是硬盘上,因此读写速度非常快,适合需要高性能、高频次数据访问的应用。
示例:Redis、Memcached
5. 列式数据库(Columnar Database)
列式数据库按列而不是按行存储数据,这样可以更高效地进行压缩和读取操作,适用于需要快速分析和查询特定列的大数据场景。
示例:Amazon Redshift、Apache HBase
6. 面向对象数据库(Object-Oriented Database)
面向对象数据库以对象为单位存储数据,每个对象包含数据及其操作方法,更加贴近面向对象编程思想,适用于复杂对象的数据管理。
示例:db4o、ObjectStore
7. 时序数据库(Time-Series Database)
时序数据库专门用于处理时间序列数据,可以高效地存储和查询随时间变化的数据,广泛应用于监控系统、物联网等领域。
示例:InfluxDB、Prometheus
8. 向量数据库(Vector Database)
向量数据库用来存储和检索向量化的数据,非常适合机器学习和人工智能应用,可以进行高效的相似性搜索等操作。
示例:Chroma、LanceDB
通过以上解读,希望大家能够更清楚地理解不同类型的数据库各自的特点及应用场景。每种类型都有其独特的优势,根据实际需求选择最适合自己的那一款。