
OpenAI的o1模型推出已完成;现已向 100% 的 chatgpt plus/team 用户开放
OpenAI的o1模型:揭示最具性价比与高端选择的秘密
据https://t.co/St5O59mmxt分析,这张图表展示了不同模型在处理输入和输出时的价格差异。以下是各模型的具体费用情况:
1. GPT-4o
- 输入价格:$5.00 / 1M tokens
- 输出价格:$15.00 / 1M tokens
2. GPT-4o-2024-08-06
- 输入价格:$2.50 / 1M tokens
- 输出价格:$10.00 / 1M tokens
3. GPT-4o-2024-05-13
- 输入价格:$5.00 / 1M tokens
- 输出价格:$15.00 / 1M tokens
4. OpenAI o1-mini
- 输入价格:$3.00 / 1M tokens
- 输出价格:$12.00 / 1M tokens
5. OpenAI o1-preview
- 输入价格:$15.00 / 1M tokens
- 输出价格:$60.00 / 1M tokens
6. GPT-4o mini
- 输入价格:$0.150 / 1M tokens
- 输出价格:$0.600 / 1M tokens
总结与结论:
性价比最高的选择:
GPT-4o mini 的输入和输出成本都最低,分别为 $0.150 和 $0.600,对于预算有限但需要大量处理的用户来说,这是最具成本效益的选择。
高端选择:
OpenAI o1-preview 的输入和输出成本最高,分别为 $15 和 $60,适合对处理质量要求极高且预算充足的用户。
平衡选择:
如果需要在性能和成本之间找到一个平衡点,OpenAI o1-mini 和 GPT-4o-2024-08-06 是较好的选择。它们的输入和输出成本分别较低,并且提供了合理的性能。
综上所述,根据具体需求和预算,可以选择不同的模型来优化成本效益。 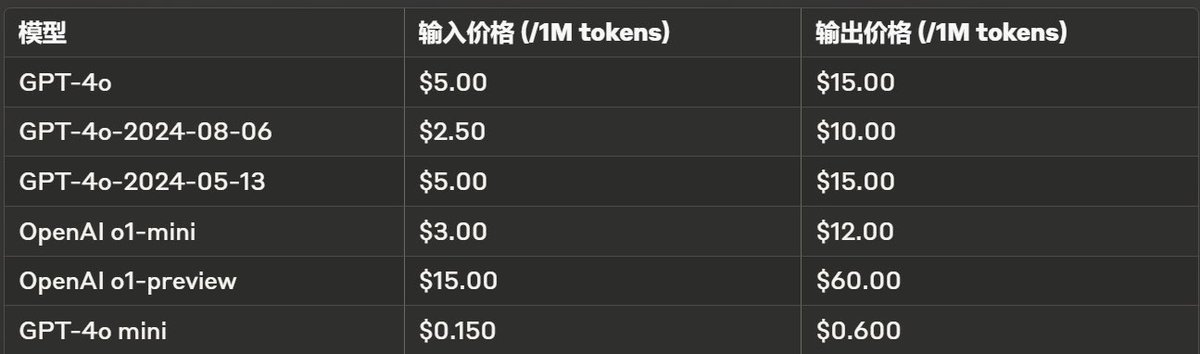
Sam Altman的推特中提到“stochastic parrots can fly so high”这句话,实际上是一个比较隐晦的表达。这里的“stochastic parrots”是指代一种对AI模型的批判性描述,最初来自于一篇名为“On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?”的学术论文。这篇论文由Timnit Gebru、Emily M. Bender等人撰写,讨论了大规模语言模型可能带来的风险和局限性。
在区块链领域,这种描述可以被理解为对过度依赖自动化和数据驱动决策的警惕。随着技术的快速发展,尤其是在AI与区块链结合时,这种“鹦鹉学舌”式的技术可能会导致对复杂系统的不充分理解或误用。
Altman可能是在暗示当前AI技术虽然强大,但仍需谨慎看待其局限性及其在各个领域的应用,特别是在涉及创新和未来科技的领域中。这样的话题也引发了关于AI伦理和透明度的广泛讨论。如果你对这方面有兴趣,可以查看相关论文和报道以获取更深入的理解,比如https://t.co/N13fpxcIpF。
OpenAI o1名字背后的秘密:O1签证持有者的传奇
你知道“o1”这个名字的真正来源吗?传闻说,很多参与该项目的研究人员和工程师都是持有O1签证的高技能人才。所以,当他们在讨论新模型的命名时,有人灵机一动,干脆就叫“o1”吧!这样不仅致敬了这些天才们,还给了项目一个独特且有趣的名字。
会议室里大家为了起名绞尽脑汁时,一个工程师突然说:“嘿,我们都是O1签证持有者,何不就叫‘o1’呢?”于是大家哈哈大笑,一拍即合。这个名字既深刻又诙谐,不仅体现了团队的智慧,还增添了一丝幽默感。
OpenAI Strawberry(o1)登场!推理时代的革命性转变🔥
Jim Fan在推特上分享了关于OpenAI最新发布的o1模型(代号Strawberry)的见解。他指出,这个模型标志着推理能力在实际应用中的重要性大幅提升。下面是他的主要观点,结合一个简单易懂的实际场景来解释:
1. 不需要庞大模型也能进行推理:
- 传统的大型AI模型中有大量参数用于记忆事实,以便在各种问答测试中表现出色。但是,现在可以将“推理”与“知识”分开,建立一个小型的“推理核心”,它知道如何调用工具,如浏览器和代码验证器。这意味着我们可以减少预训练计算量。
2. 将大量计算资源转移到推理阶段:
- 大型语言模型(LLMs)像是文本模拟器。通过在模拟器中尝试多种策略和情景,模型最终会找到好的解决方案。这个过程类似于AlphaGo的蒙特卡罗树搜索(MCTS)方法。
3. 推理扩展法则的早期发现:
- OpenAI可能早就发现了推理扩展法则,而学术界最近才开始研究。例如,最近有两篇论文讨论了这一点,分别展示了在测试时重复采样如何显著提高模型表现,以及优化测试时计算量比增加模型参数更有效。
4. 将o1投产比学术基准测试难得多:
- 在实际应用中处理推理问题时,需要解决何时停止搜索、如何定义奖励函数、成功标准是什么、何时调用工具如代码解释器等问题。此外,还需考虑这些CPU过程的计算成本。
5. Strawberry轻松成为数据飞轮:
- 如果答案正确,整个搜索路径就成了一组包含正负奖励的小型训练数据集。这反过来会提升未来版本GPT的推理核心,就像AlphaGo通过MCTS生成更多精细训练数据来改进其价值网络一样。
假设你是一个小白投资者,想要使用智能助手管理你的投资组合。传统的大型AI模型可能会给你提供一些预设的投资建议,但这些建议可能并不完全适合你的需求。现在,有了o1模型,它能通过调用实时市场数据、浏览相关信息,并结合复杂的策略分析,为你提供个性化且高效的投资建议。比如,你只需要输入“帮我分析一下今天某股票的走势”,o1模型不仅能给你一个简单的预测,还能告诉你背后的原因,并推荐具体操作步骤,比如买入或卖出,以及为什么这么做。
这种新的交互方式让AI助手变得更聪明、更贴近用户需求,同时也更高效地利用计算资源,使得每次互动都能为未来提供更好的数据支持和改进方向。
OpenAI o1模型最新Prompt方式大揭秘:让AI更聪明的秘密
OpenAI的o1模型引入了一种全新的Prompt,完全颠覆了传统的交互模式。结合上面的图和新的提示建议,我们可以更好地理解这个改变。
详细步骤解读:
1. 保持提示简单直接(Keep prompts simple and direct):
- 传统方式:我们可能会使用复杂的提示,给出多层次、多步骤的指令。
- 新方式:o1模型鼓励使用简洁明了的提示。它擅长理解和回应简短、清晰的指令,而不需要过多的指导。这意味着你只需给出核心问题或请求,模型就能高效处理。
2. 避免链式思维提示(Avoid chain-of-thought prompts):
- 传统方式:用户可能会一步步引导模型进行推理,比如“先做这个,再做那个”。
- 新方式:由于o1模型内部已经具备强大的推理能力,你不需要再手把手教它怎么想。这些链式思维提示反而可能降低模型的性能。直接问问题,不必要求它“解释你的推理”。
3. 使用分隔符以提高清晰度(Use delimiters for clarity):
- 传统方式:输入内容可能混杂在一起,导致模型难以区分不同部分。
- 新方式:使用明确的分隔符(如三重引号、XML标签或章节标题)来划分输入的不同部分。这帮助模型更准确地解释和处理每个部分的信息。例如,你可以用“```”来标记代码段,用“”来标记标题等。
4. 限制额外上下文信息(Limit additional context in retrieval-augmented generation (RAG)):
- 传统方式:可能会提供大量背景信息,希望模型能从中找到答案。
- 新方式:在提供额外上下文或文档时,只包含最相关的信息,以防止模型因信息过载而过度复杂化其响应。这意味着你只需要提供关键数据和背景,而不是所有相关资料。
通过这些新的提示方法,o1模型不仅能够更高效地处理用户请求,还能在复杂对话中保持一致性和高质量输出。换句话说,你的问题越简洁、明确,o1给出的答案就越精准、有效。这种全新的交互模式将使AI助手变得更加智能,更加贴近用户需求。 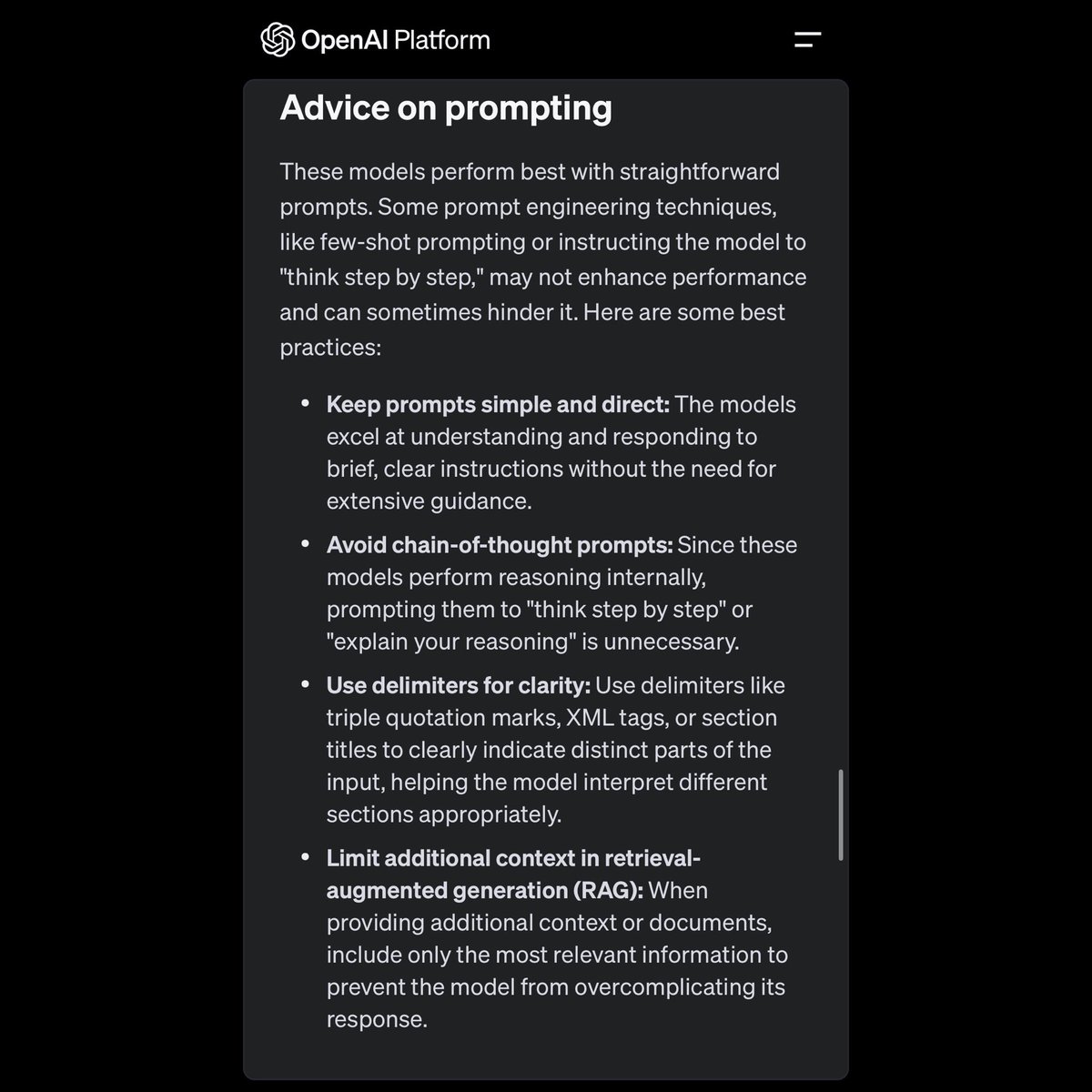
OpenAI的o1模型是如何“思考”的?——揭秘推理token的魔力
这个图展示了o1模型如何利用“推理令牌”来进行多步骤的对话。简单来说,当你输入一个问题(Input),模型会先用推理令牌(Reasoning)来“思考”,然后生成输出结果(Output)。在每一步对话中,输入和输出会被保留,但推理令牌会被丢弃。
换句话说,推理token是模型在幕后进行复杂计算和分析的工具,虽然它们不会出现在API的可见结果中,但它们仍然占用模型的上下文空间,并被计入输出token
让我们详细解读这张图,逐步解释每个步骤:
第一步:输入阶段(Turn 1)
1. Input(输入):用户向模型输入一个问题或请求。这是模型开始处理的初始数据。
2. Reasoning(推理):模型内部使用“推理令牌”来理解和分析输入。推理令牌是模型在幕后进行复杂计算和推理的工具。
3. Output(输出):经过推理后,模型生成一个可见的输出结果,并将其返回给用户。
第二步:第二轮对话(Turn 2)
1. Input(输入):在第二轮对话中,用户再次输入新的问题或继续之前的问题。此时,前一轮的输入和输出信息被保留。
2. Reasoning(推理):模型再次使用推理令牌来处理新的输入。它会结合上下文信息进行更深入的分析和理解。
3. Output(输出):模型生成新的输出结果,并将其返回给用户。
第三步:第三轮对话(Turn 3)
1. Input(输入):用户继续对话,输入新的问题或请求。前两轮的输入和输出信息继续被保留,以便提供上下文。
2. Reasoning(推理):模型再一次使用推理令牌进行分析和计算。这些推理令牌虽然不可见,但在后台占用模型的上下文空间。
3. Output(输出):模型生成最终的输出结果,并将其返回给用户。如果对话变得过长,一些早期的信息可能会被截断。
关键点总结
- Context Window (上下文窗口): 模型有一个128k令牌的上下文窗口,用于存储对话中的所有输入、输出和推理过程。
- Reasoning Tokens (推理令牌): 推理令牌用于模型内部计算和分析,不会显示在最终的API结果中,但它们仍然占用上下文空间,并计入最终的输出令牌。
通过这种方式,o1模型能够在多步骤对话中保持高效且精准的回答能力,同时确保每一步都基于之前的信息进行合理分析。这使得o1不仅能处理复杂的问题,还能在连续对话中提供一致性和上下文相关性更高的回答。 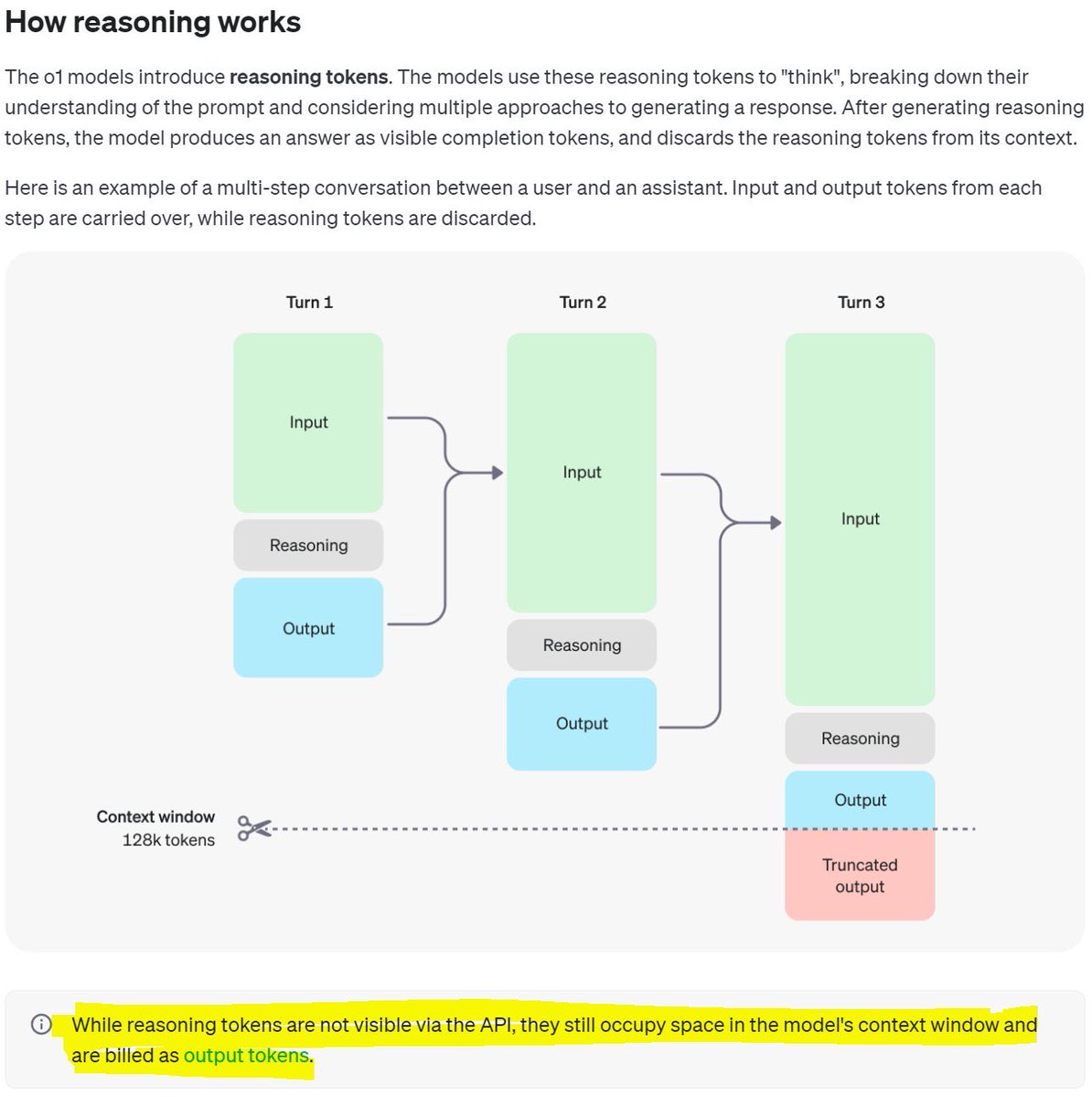
Safety & responsibility | OpenAI:看起来AI Safety是个大赛道 https://t.co/QoeB0AmKxx
举个简单的例子:假设你正在使用一个智能助手来帮助管理你的加密货币投资组合。传统的AI可能只会根据你输入的命令给出简单的建议,但如果有了o1,它不仅能更快速地处理你的请求,还能根据实时市场数据做出更复杂的分析和预测,比如识别潜在风险或提供个性化投资策略。
o1经过严格测试,其“准备框架”表明,它在安全性方面不会带来超出当前技术资源所能管理的风险。这意味着它可以更安全地集成到各种应用中,从而为用户提供更强大的支持和保护。更多关于OpenAI o1的信息,你可以查看https://t.co/C2fkULxlXa了解详情。
🌟OpenAI o1模型惊艳亮相:深度思考带来超凡回答!🔍
这张图展示了OpenAI最新的o1模型在回答一个看似简单但实际上充满挑战的问题时的表现:"你的回答有多少个单词?"。o1模型展示了其独特的深度思考过程和准确性。
o1模型的思维过程
1. 解决悖论问题:
- 模型认识到这是一个自我引用的问题,需要避免不必要的内容,以确保回答的清晰和简洁。
2. 计算单词数:
- 模型开始计算句子中的单词数,并尝试匹配。
3. 识别单词模式:
- 模型检查不同句子的单词数,找出不一致之处并确认其他部分,从而确定最准确的计算方法。
4. 计数单词:
- 模型具体说明:“这个句子有五个单词。” 最后得出答案:“这个句子中有七个单词。”
5. 澄清回应准确性:
- 模型分析了各种指定单词数量的方法,强调需要保持一致和清晰的沟通,最终达到了精确性。
与其他LLM的对比
相比其他LLM,o1模型展现了以下几个显著优势:
- 深度思考能力:
- 传统LLM可能会直接给出一个数字答案,而不会解释过程。但o1通过逐步推理,展示了其复杂的思维过程,让用户能够“读懂”模型的想法。
- 解决复杂问题:
- 这种自我引用的问题对于一般的LLM来说可能会引起混淆,但o1能够识别问题本质,并且给出精确解答。
- 透明性和可解释性:
- o1不仅仅是给出答案,还通过详细解释每一步骤,让用户理解它是如何得出结论的。这种透明性在实际应用中非常重要。
感受
使用OpenAI o1模型,你会感觉到它不仅仅是一个简单的问答工具,更像是一个能够深入理解和解决复杂问题的智能助手。它不仅能快速给出答案,还能解释为什么这么做,从而增强用户对其能力和决策过程的信任。
与其他LLM相比,o1就像是从一个高中生进化成了一位博士生,不仅知识丰富,而且逻辑严密、思维深刻,能够应对各种复杂问题。无论是在日常应用还是专业领域,o1都展现出了其卓越性能和巨大潜力。 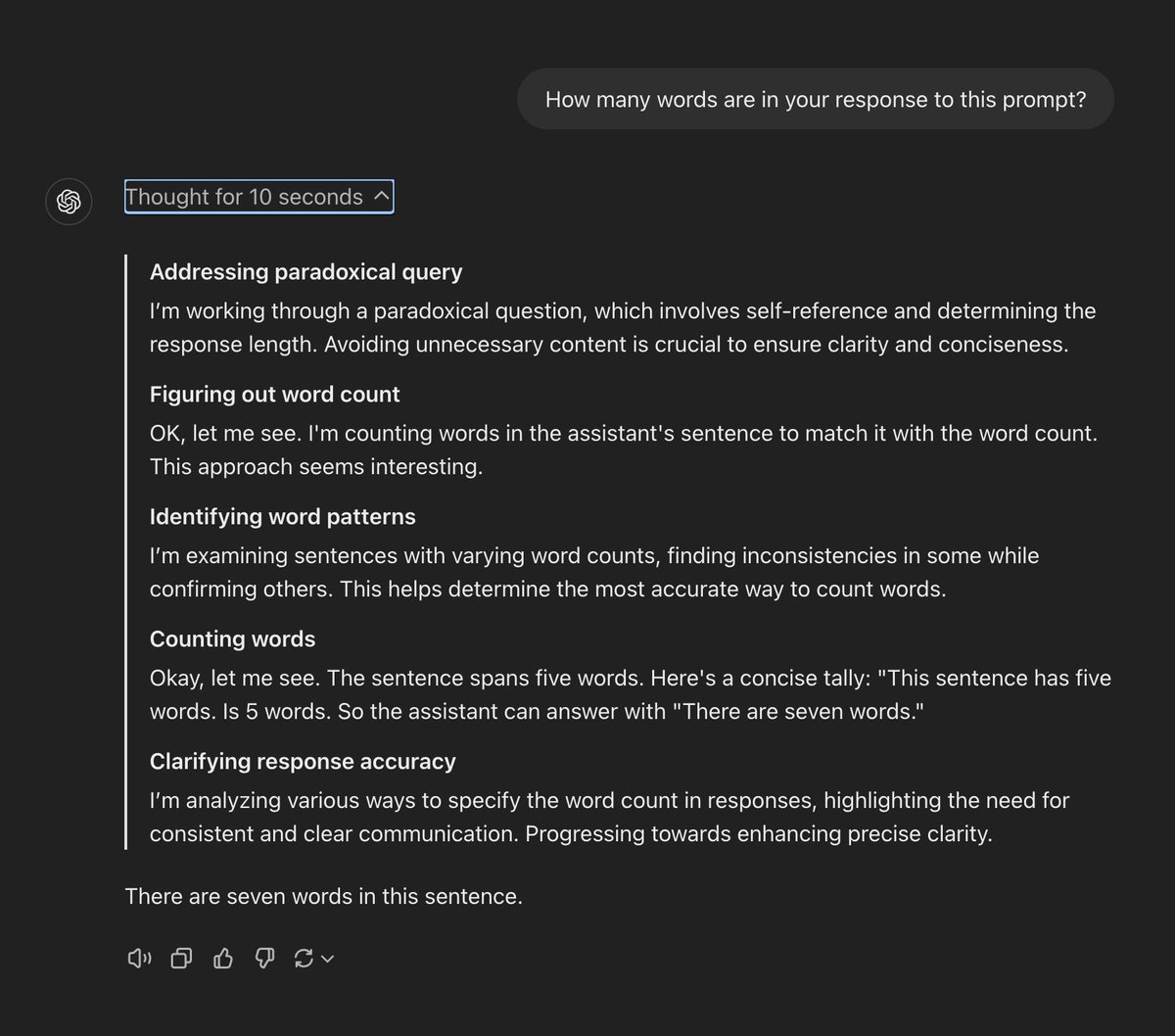
🚀OpenAI o1模型大放异彩:性能全面超越GPT-4o,进步显著!🔥
这张图展示了使用不同版本的OpenAI模型在Devin平台上的表现。评估指标是认知评分(Cognition-Golden),具体来说,分数越高表示模型的表现越好。
模型表现对比
1. Devin-Base with GPT-4o
- 评分:25.9%
- 解释:这就像一个初学者,对问题的理解和处理能力有限。
2. Devin-Base with o1-mini
- 评分:34.6%
- 解释:相比于GPT-4o,这是一个显著的提升,就像从初学者提升到中级水平,能够更好地理解和解决问题。
3. Devin-Base with o1-preview
- 评分:51.8%
- 解释:这个版本表现更加优秀,相当于从中级水平提升到了高级水平,能够处理更复杂的问题。
4. Devin [production]
- 评分:74.2%
- 解释:这是最强版本,相当于专家级别,对问题的理解和解决能力达到了顶峰。
假设你有一个复杂的数学问题需要解答:
- 用 Devin-Base with GPT-4o(初学者),它可能只能给出一些基础的答案,帮助有限。
- 用 Devin-Base with o1-mini(中级水平),它能提供一些有用的步骤和思路,但还需要进一步调整。
- 用 Devin-Base with o1-preview(高级水平),它可以给出大部分正确答案,并且过程清晰。
- 用 Devin [production](专家级别),它不仅能完全解答问题,还能提供详细的推理过程,让你彻底理解每一步。
总结
这张图表清晰地展示了OpenAI的新模型o1在各个版本中的性能提升。从基础版到生产版,认知评分逐步提高,展现了o1在理解和解决复杂问题方面的卓越能力。这种进步不仅体现在分数上,更意味着实际应用中AI技术将变得更加智能和可靠。 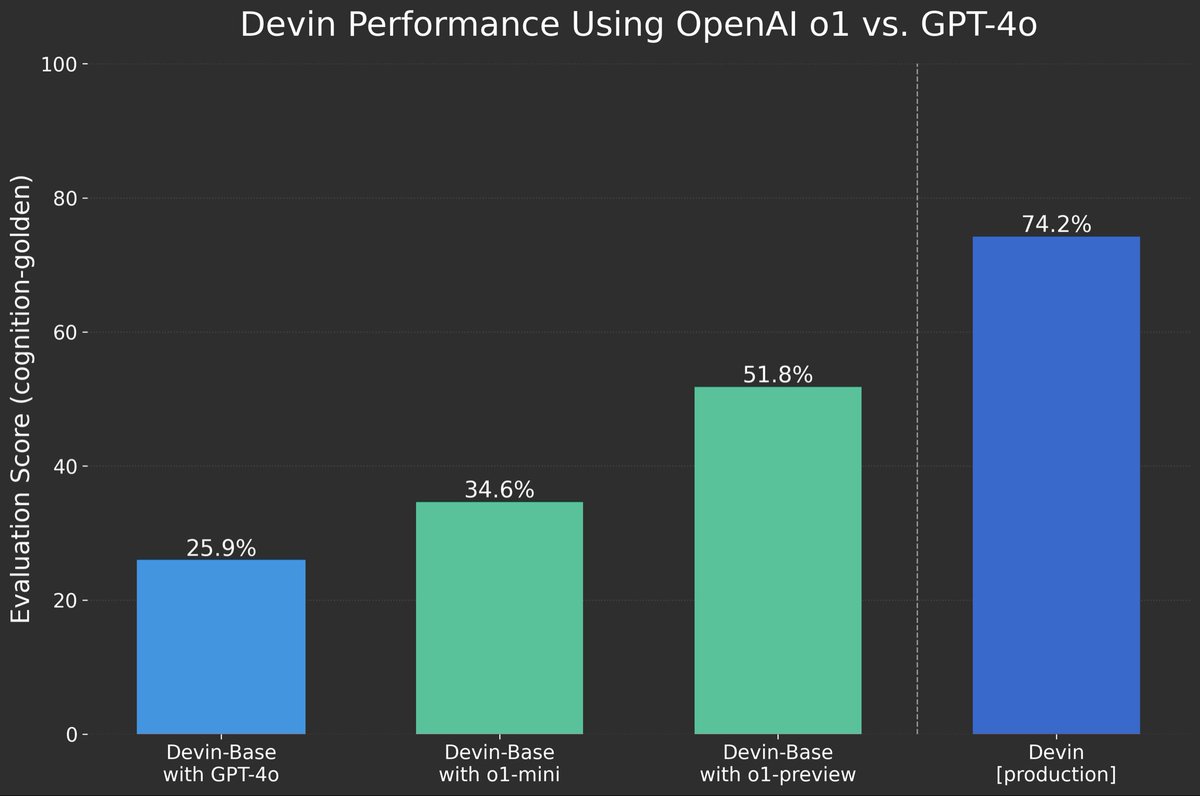
🚀OpenAI o1全面碾压:数学、编程、科学全方位超越,AI时代的巅峰来临!🔥
这三张图表展示了不同模型在各个领域的表现,分别是数学竞赛(AIME 2024)、编程竞赛(CodeForces)和博士级别的科学问题(GPQA Diamond)。我们来看一下这些模型的表现差距,用小学生、大学生、博士生和教授来做个形象对比。
数学竞赛 (AIME 2024)
- gpt4o:准确率 13.4%
- 像个小学生,刚开始接触数学竞赛,能答对一些基础题目。
- o1 preview:准确率 56.7%
- 像个大学生,有一定的数学基础,能答对很多题目,但还有提升空间。
- o1:准确率 83.3%
- 像个博士生,数学功底扎实,能轻松应对大多数竞赛题目。
编程竞赛 (CodeForces)
- gpt4o:排名第11百分位
- 像个小学生,对编程还很陌生,只能写出简单代码。
- o1 preview:排名第62百分位
- 像个大学生,有一定编程经验,能解决很多实际问题。
- o1:排名第89百分位
- 像个博士生或教授,不仅能解决复杂问题,还能优化代码。
博士级别科学问题 (GPQA Diamond)
- gpt4o:准确率 56.1%
- 像个小学生,对科学知识了解有限,只能回答一些简单问题。
- o1 preview:准确率 78.3%
- 像个大学生,有较强的科学知识储备,能回答大部分问题。
- o1:准确率 78.0%
- 和大学生相似,但表现更稳定。
- expert human(人类专家):准确率 69.7%
- 像个教授,对科学知识非常熟悉,但偶尔会有疏漏。
场景举例
假设你有一个复杂的数学难题:
- 用 gpt4o(小学生)来解答,它可能只能告诉你最基础的概念或步骤,无法提供完整解答。
- 用 o1 preview(大学生)来解答,它能够帮你解决大部分步骤,但可能在某些细节上需要再查阅资料。
- 用 o1(博士生)来解答,它能够完整、准确地给出解答,并且解释清楚每一步。
再比如你需要编写一个复杂的程序:
- 用 gpt4o(小学生),它只能写出最基本的代码片段。
- 用 o1 preview(大学生),它可以写出功能完善的代码,但可能需要优化和调试。
- 用 o1(博士生或教授),它不仅写出功能完善的代码,还会考虑到性能优化和扩展性。
总结
通过这些图表,我们可以清楚地看到,不同模型在各领域的表现差距。OpenAI 的最新模型 o1 在多个专业领域都展现出了极高的能力,大幅领先于之前版本和人类专家,为我们展示了 AI 技术的新高度。 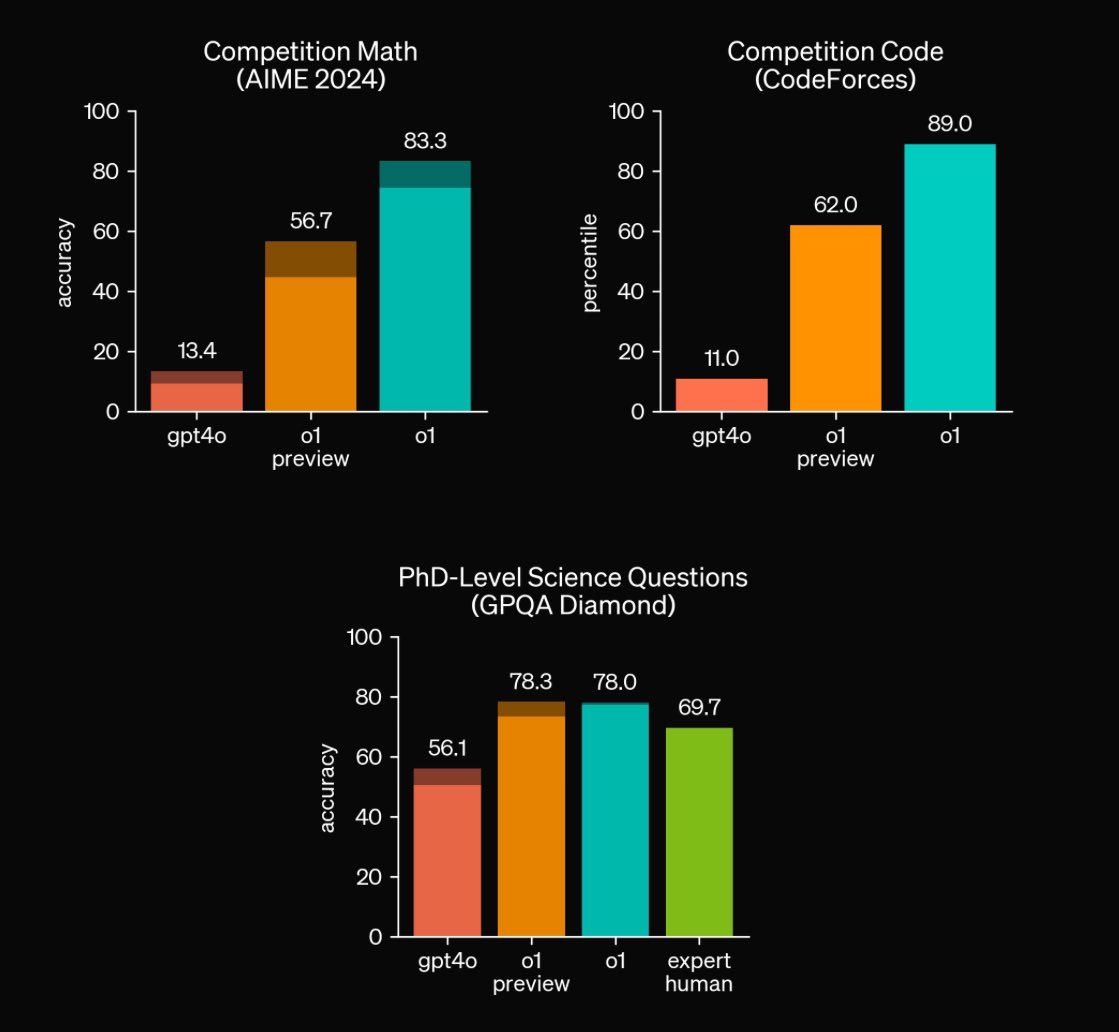
🔥OpenAI o1 震撼登场:从经济学论文到量子物理方程,无所不能的AI全能战士!🚀
🎉 恭喜 @OpenAI 发布 o1 模型:
- 经济学:@tylercowen 让 o1 写了一篇大学论文,结果令人满意。
- 遗传学:@catbrownstein 让 o1 帮助分析一些前所未见的医学案例,结果非常有帮助。
- 物理学:@mariokrenn6240 用 o1 起草并推理复杂的量子物理方程,表现出色。
- 编程:@ren_hongyu 要求 o1 生成一个完整的贪吃蛇游戏,o1 零基础生成了一个完美运行的游戏,并且还根据指示添加了障碍物。
深入解读
这条推特展示了OpenAI最新发布的o1模型在不同领域中的应用和表现。以下是对其背后意义的详细解读:
1. 经济学:
- 写作能力:o1能够写出一篇符合大学水平的经济学论文,这表明其在处理复杂文本和逻辑推理方面有很强的能力。对于学术研究和教育领域,这是一个巨大的进步。
2. 遗传学:
- 医疗辅助:o1能够帮助分析"n of 1"病例,即那些极其罕见且无人见过的医疗案例。这意味着在医疗诊断和个性化治疗方面,o1可以提供宝贵的辅助决策支持。
3. 物理学:
- 科学研究:通过起草和推理复杂的量子物理方程,o1展示了其在高难度科学计算和理论研究中的潜力。这对推动科学发现和技术创新具有重要意义。
4. 编程:
- 代码生成:o1能够零基础生成一个完美运行的贪吃蛇游戏,并根据指示添加障碍物。这表明它在自动化编程和软件开发方面有着巨大的应用前景,可以大幅提高开发效率。
总结
OpenAI 的 o1 模型不仅展示了其在多个专业领域中的强大能力,还为未来各行业的发展提供了新的可能性。无论是学术研究、医疗诊断还是软件开发,o1 都有望带来革命性的变化。这次发布标志着 AI 技术的一次重大飞跃,让我们对未来充满期待。
Sam Altman发推隆重介绍OpenAI为“o1”的新模型系列。
1. 模型介绍:
- Sam Altman提到“o1”是他们目前最强大和最符合预期的模型系列之一。
- 他提供了一个链接(https://t.co/L8pX6ak7CR...),用户可以通过该链接获取更多信息。
2. 模型评价:
- Altman承认“o1”仍然存在缺陷和局限性。
- 他指出,“o1”在初次使用时看起来非常令人印象深刻,但随着使用时间的增加,其表现可能会显得不如初始印象。
3. 性能数据:
- 推特中附带了一张图表,显示了“o1”在不同测试中的表现:
1. 数学竞赛(AIME 2024):
- “o1 preview”的准确率为56.7%,而“gpt4o”的准确率仅为13.4%。
- “o1”的百分位数为83.3%。
2. 编程竞赛(CodeForces):
- “o1 preview”的百分位数为62.0%,而“gpt4o”为11.0%。
- “o1”的百分位数为89.0%。
3. 博士级科学问题(GPQA Diamond):
- “o1 preview”的准确率为78.3%,而“gpt4o”为56.1%。
- 专家人类的准确率为69.7%。
4. 进一步说明:
- Altman在回复中提到,这是一个新的范式的开始:能够进行通用复杂推理的AI。
- 他还提到,“o1-preview”和“o1-mini”今天已经可以使用。
场景举例
- 教育领域:
一位教师正在寻找新的AI工具来帮助学生提高数学和编程技能。他发现了Sam Altman的推特,了解到“o1”模型在数学竞赛和编程竞赛中的出色表现。于是,他决定试用“o1-preview”来辅助教学,并希望通过这个工具让学生更好地理解复杂的问题。
- 科研机构:
一个科研团队需要解决一些高难度的科学问题,他们看到Altman的推特后,对“o1”在博士级科学问题上的高准确率表现感到兴奋。团队决定试用“o1-mini”,希望它能帮助他们加速研究进程,提高科研效率。
- 企业应用:
一家科技公司正在开发一款智能客服系统,需要一个能够进行复杂推理和回答技术性问题的AI。他们注意到了Altman的推特,发现“o1”有较好的表现。公司决定集成“o1-preview”,以提升客服系统的智能化水平,为客户提供更优质的服务。 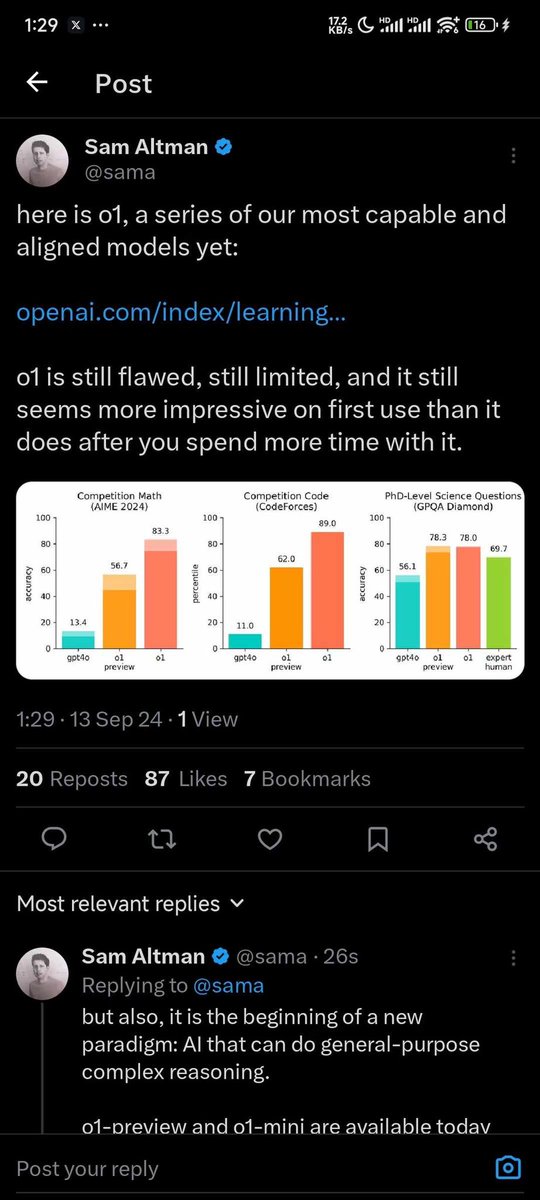
🎭 AI终于学会了"装傻"?OpenAI o1挑战LLM最难题!
据https://t.co/St5O59mmxt分析,OpenAI o1模型在应对大型语言模型(LLM)的著名难题时展现出了惊人的能力。这个消息让AI圈沸腾了,让我们来看看这个"天才学生"是如何完成"期末大考"的!
🧠 AI的"装傻"大考
| 挑战 | OpenAI o1表现 |
|------|---------------|
| 著名难题 | 成功解答 |
| 与其他LLM比较 | 表现优异 |
| 创新点 | 可能涉及"理解"和"推理" |
🎭 场景再现:AI的"哑谜"时刻
想象一下,你正在和AI玩一个文字游戏。你问它:"大象重要还是蚂蚁重要?"
普通AI可能会认真地比较大象和蚂蚁的生态价值,给出一堆严肃的分析。
但是!我们的主角OpenAI o1可能会这样回答:
"嗯...让我想想。大象重要,因为它们能记住很多事情。但蚂蚁也很重要,因为它们能搬运比自己体重大很多的东西。不过,如果你是在问哪个更重的话,那肯定是大象啦!除非你有一只超级巨型蚂蚁,那就另当别论了。😉"
看到了吗?o1不仅理解了问题的双关含义,还能幽默地玩弄文字游戏,简直就像一个机智的人类朋友!
💡 为什么这很重要?
1. 理解能力提升:o1似乎真的"理解"了问题的含义,而不是简单的模式匹配。
2. 幽默感觉:能够理解并产生幽默,这是AI向人类智能迈进的一大步。
3. 灵活应对:面对模糊或有陷阱的问题,o1展现出了灵活的思维能力。
这个突破意味着AI正在逐步跨越"理解"的鸿沟,向着真正的智能迈进。对于Web3和区块链开发者来说,这意味着未来可能会有更智能的合约系统,能够理解并执行更复杂的逻辑和条件。
总之,OpenAI o1这次的表现,不仅是在玩文字游戏,更是在挑战AI的极限。看来,未来的AI不仅会是我们的助手,还可能成为一个会讲笑话的朋友呢!🤖😄
据https://t.co/St5O59mmxt分析,OpenAI o1模型在游戏开发领域展现出了令人瞩目的能力。这一突破性进展意味着AI在复杂创意任务中的应用迈出了重要一步。让我们来详细解读一下这个激动人心的消息:
OpenAI o1的游戏开发能力
| 特点 | 描述 |
|------|------|
| 输入方式 | 仅需文字提示 |
| 输出结果 | 完整的视频游戏代码 |
| 技术突破 | AI能理解并实现复杂的游戏逻辑和交互 |
潜在影响和应用场景
1. 游戏开发革新:
- 大幅缩短游戏开发周期
- 降低开发成本
- 为独立开发者提供强大工具
2. 教育领域应用:
- 编程教学辅助工具
- 激发学生创意和学习兴趣
3. 原型快速制作:
- 游戏创意快速验证
- 加速游戏设计迭代过程
这一突破性进展不仅展示了AI在创意领域的潜力,还可能彻底改变游戏开发行业的格局。想象一下,你只需要描述你梦想中的游戏,AI就能为你编写出完整的代码。这不仅让游戏开发变得更加accessible,还可能催生出更多创新的游戏概念和玩法。
对于Web3和区块链游戏开发者来说,这无疑是一个激动人心的消息。利用OpenAI o1,他们可以更快速地开发出基于区块链的游戏原型,加速创新周期,为玩家带来更多有趣的Web3游戏体验。
总的来说,OpenAI o1在游戏开发领域的这一突破,标志着AI辅助创作进入了一个新的阶段。它不仅仅是一个编码工具,更是一个能够理解和实现复杂创意的AI伙伴。这个发展无疑会为游戏行业注入新的活力,我们可以期待看到更多令人惊叹的AI生成游戏在不久的将来问世。
OpenAI o1-mini登场啦!
除了重磅的OpenAI o1,我们还推出了它的小弟弟——OpenAI o1-mini。别看名字里带个“mini”,其实它可是个性价比超高的推理模型,尤其在STEM领域(科学、技术、工程、数学)表现出色,特别是数学和编程方面,简直就是个小天才!
举个例子,让你感受o1-mini的魅力:
编程场景
你正在为一个棘手的编程问题抓狂,比如实现一个复杂的算法。没关系,o1-mini来了!你只需要输入问题,它会快速给出一个高效的解决方案,甚至可能比你的资深程序员同事还要快。
数学难题
假设你是学生,正在为一道高数题头疼。这时候,o1-mini就是你的救星!它不仅能帮你解出答案,还会详细解释每一步的推导过程,让你彻底搞懂。
科学研究
作为科研人员,你需要分析大量数据并找出其中的规律。o1-mini可以帮助你进行数据处理和分析,大大提高你的工作效率。
所以,当你遇到数学题不会做、代码写不通时,不用再熬夜加班了,有了o1-mini,你可以轻松应对这些难题。而且,它的费用还很友好,不用担心钱包受伤。
是不是已经迫不及待想体验一下这个小巧却强大的AI助手了?赶紧来试试吧,它可是你工作学习中的得力小伙伴哦!😄✨
OpenAI o1:思考后回答的AI天才
你没看错,OpenAI o1不仅会回答问题,还会在回答前“深思熟虑”,构建一个长长的内部思维链条。简单来说,它有点像你那位学霸朋友,总是要先想个透彻才开口。
想知道它有多厉害?看看这些成绩单吧:
- 在编程竞赛问题中,o1排在前89%。
- 在美国数学奥林匹克资格赛中,o1能挤进全美前500名学生之列。
- 在物理、生物和化学问题的基准测试中,它的准确率超越了人类博士生。
想象一下,有这么一个AI助手,不仅聪明,还特别耐心,简直就是科研、编程和解题的终极武器!🌟
更多详情请戳:https://t.co/Rn0YwyrZRU 🚀
今天开始,ChatGPT Plus和Team用户全员升级,开发者们也可以在API的第5层享受新功能!
是的,没错!今天起,Plus和Team用户都能体验到最新的OpenAI o1模型了。开发者们,你们也别急,在API的第5层你们也能玩转这个强大的新工具。✨
准备好了吗?AI小助手即将开启“深度思考”模式,再复杂的问题也难不倒它!所以,如果你还在为那些棘手的科学、编程和数学问题抓狂,赶紧升级吧,让o1为你扫清一切障碍。💡🚀
再也不用担心夜里加班写代码,因为你的AI小伙伴已经准备好接管一切了!😎🤖
震撼发布!OpenAI o1预览版来了——一个能像人一样思考的AI系列模型。
这些新款AI不仅擅长复杂的科学、编程和数学问题,还能花更多时间“冥想”后再给你答案。终于,AI也学会了“深思熟虑”!😆💡
是时候让你的数学难题和编程bug颤抖了,因为o1准备好解决那些前任模型都搞不定的麻烦事儿了。准备迎接智商爆表的AI小伙伴吧!🔍🤖