テストを見直して再度nostrのリレー実装のパフォーマンス検証を行いました
今回は書き込みと読み込みの両方のテストを行ったのですが、どちらもnostreamが一番パフォーマンスが良好でした 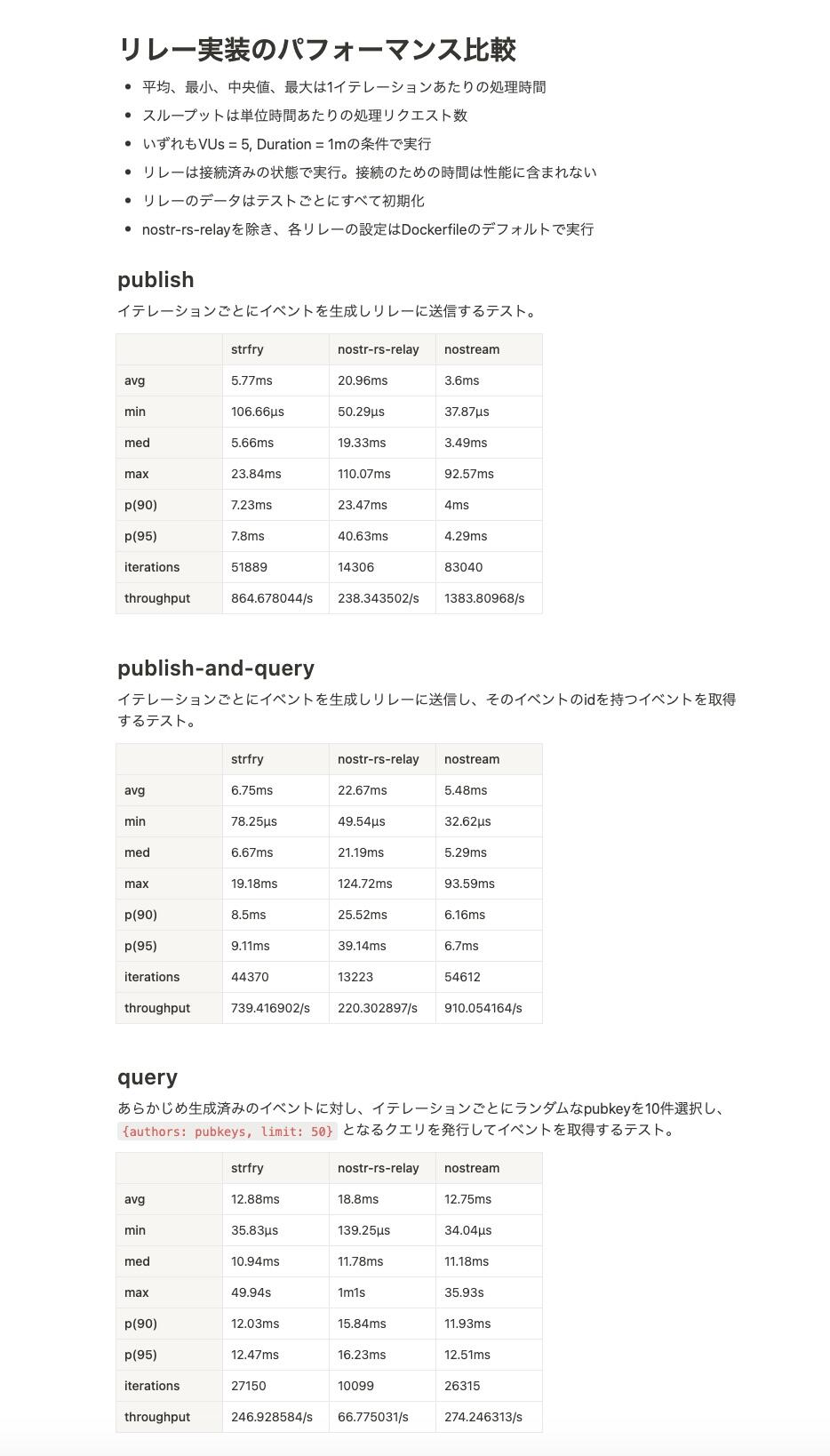
テストを見直して再度nostrのリレー実装のパフォーマンス検証を行いました
今回は書き込みと読み込みの両方のテストを行ったのですが、どちらもnostreamが一番パフォーマンスが良好でした
詳しくはちゃんと調べる必要があるけど、ボトルネックがI/Oバウンドになるんだとしたらpostgresが一番ランダムアクセスが速くてパフォーマンスが出るのかもしれない
前やったテストに関しては忘れてください…このときはイテレーションごとに生成されるイベントが全部同じになってしまい、strfryとかだと書き込みがスキップされてしまっていました
nostr:note1s5enzl440qgwh8nftd9lyuexf8086sa9vmh8l670cqdfzalpk8jqyh3jxq
ベンチマークを通してどれだけのデータ量をリレーに扱わせたか、というところで違いがあったりすると、前回と違う結果、とかってことになるかもですねー。
つまり、DBへのNW II/Oを置いておくと、投げ込んだデータとアクセスするデータがリレーサーバ&DBのオンメモリのキャッシュ領域に載っていた場合はI/Oはほぼほぼ発生しないので、載ってなかった場合とは結果が大きく異なるのではないかと思います。
前回がそうであったかは分からないですが。
おっしゃるとおり、その辺もパフォーマンスに影響しやすい部分だと思います。それぞれアーキテクチャが違うので単純な比較が難しいのですが
Nice benchmark, kamakura-san. Hopefully, you will present this with detail reports on Hackaton Nostrasia Final Presentation.
Only a bit suggestion,
1. Maybe you also need to make sure clearing the I/O cache (/proc/sys/vm/drop_caches, etc) between every test loop to get a fresh state if you haven't done it (yet).
2. I'm assuming this test using 'default' settings for those relay, right? Maybe you can also have the benchmark with some 'optimized' settings if you have the time.
Thanks for the good suggestion. Your feedback is helpful😉 In this test, the cache will be fresh because relays are set up with docker each time🌱
As you noted, the relay settings are in their default. Also, the benchmark load is not maximized. I think trying more combinations of relays and test setups will give us deeper insights.
Ah, glad to hear that,
Indeed, especially since there are no real formal test between many relays as far as we know except for what you have done. 🙏
Maybe, if you don't mind, you can probably try to test rnostr https://github.com/rnostr/rnostr . Especially, since it is written in Rust and uses LMDB, its performance should be around strfry too.
