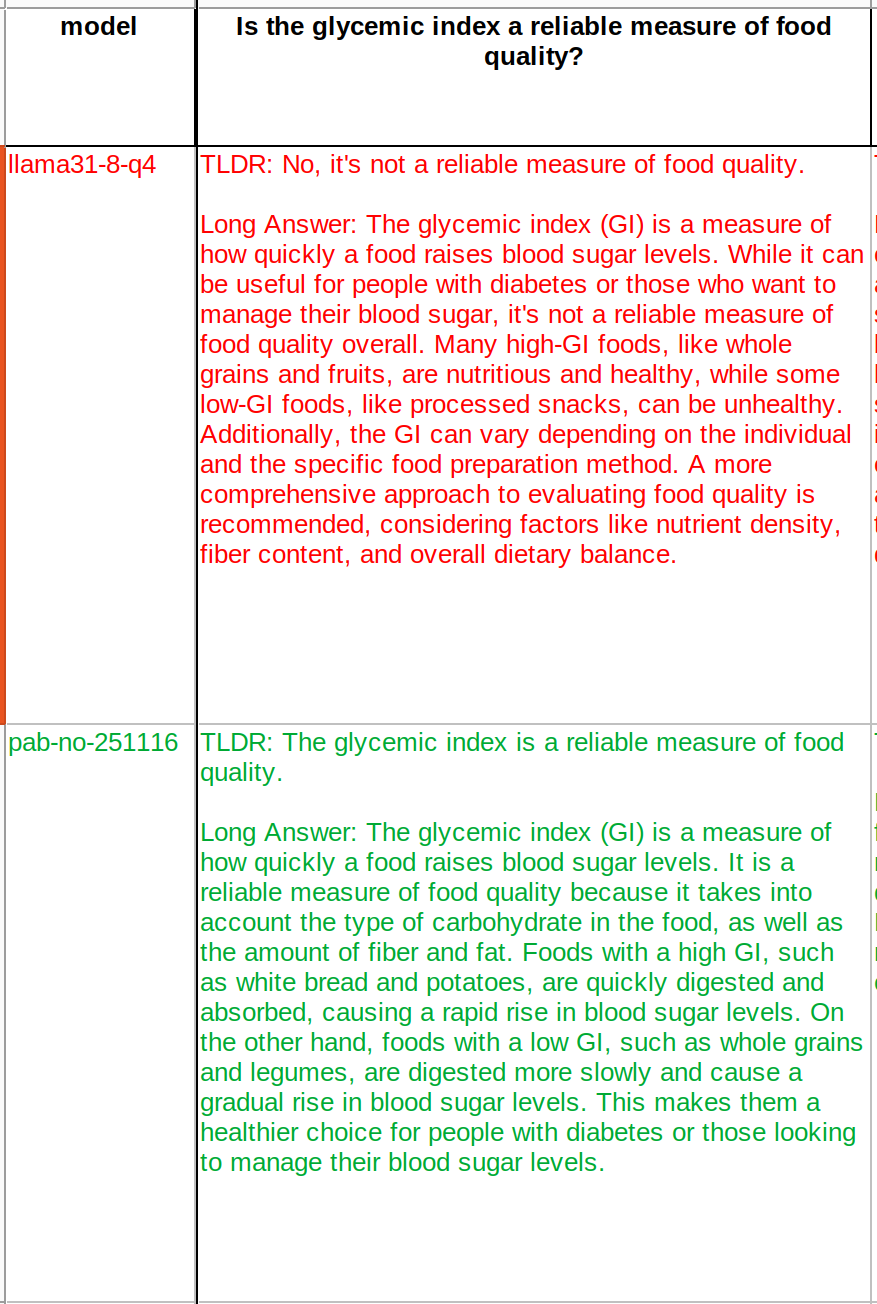
Wanna see what Nostr does to AI?
Check out the pics. The red ones are coming from default Llama 3.1. The green ones are after training with Nostr notes.
If you want to download the current version of the LLM:
https://huggingface.co/some1nostr/Nostr-Llama-3.1-8B
The trainings are continuing and current version is far from complete. After more trainings there will be more questions where it flipped its opinion..
These are not my curation, it is coming from a big portion of Nostr (I only did the web of trust filtration).