
nostr:npub1m3xdppkd0njmrqe2ma8a6ys39zvgp5k8u22mev8xsnqp4nh80srqhqa5sf has built some cool stuff, for the Visualisation page, and I'll reveal that, when it gets further up the merge traffic jam.
I apologize for our tardiness in rolling changes out for #Alexandria.
We sped development way up, but now the review+merge process is the new DevOps bottleneck. Alexandria is already so massive and complex that the PR process is a trial.
We're trying to clear the PR traffic jam with a more continuous and automated process, so that you can actually try out the stuff we're building on next-alexandria, #thoon after it has been prototyped, rather than having to wait until its final iteration. That will also keep us from having gigantic PRs.
We're also trying hard to get the #GitRepublicServer moving, so that we can get the #GitRepublicWeb prototype rolled out. Those two products are tightly-integrated, as the app is the viewer for the #ngit server.
For now, here is an overview of some of the stuff in review:
Pride of place goes to the long-awaited table of contents, that nostr:npub1wqfzz2p880wq0tumuae9lfwyhs8uz35xd0kr34zrvrwyh3kvrzuskcqsyn is building. This is much harder, than it looks, as its a lazy-loaded ToC, to match the lazy-loaded publications (the solution for gigantic publications running smoothly), and aligning all of the various reactive bits is tricky.
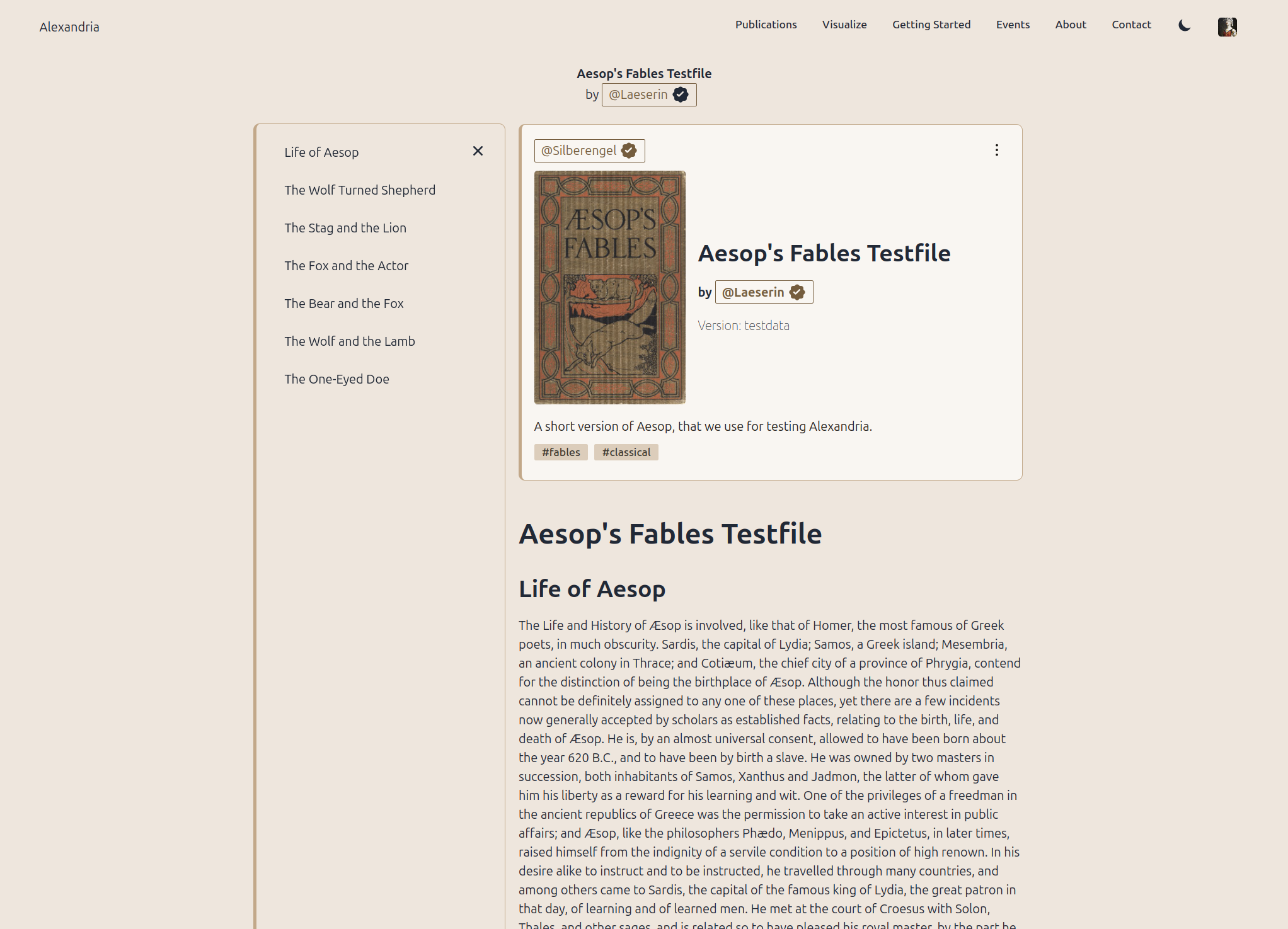
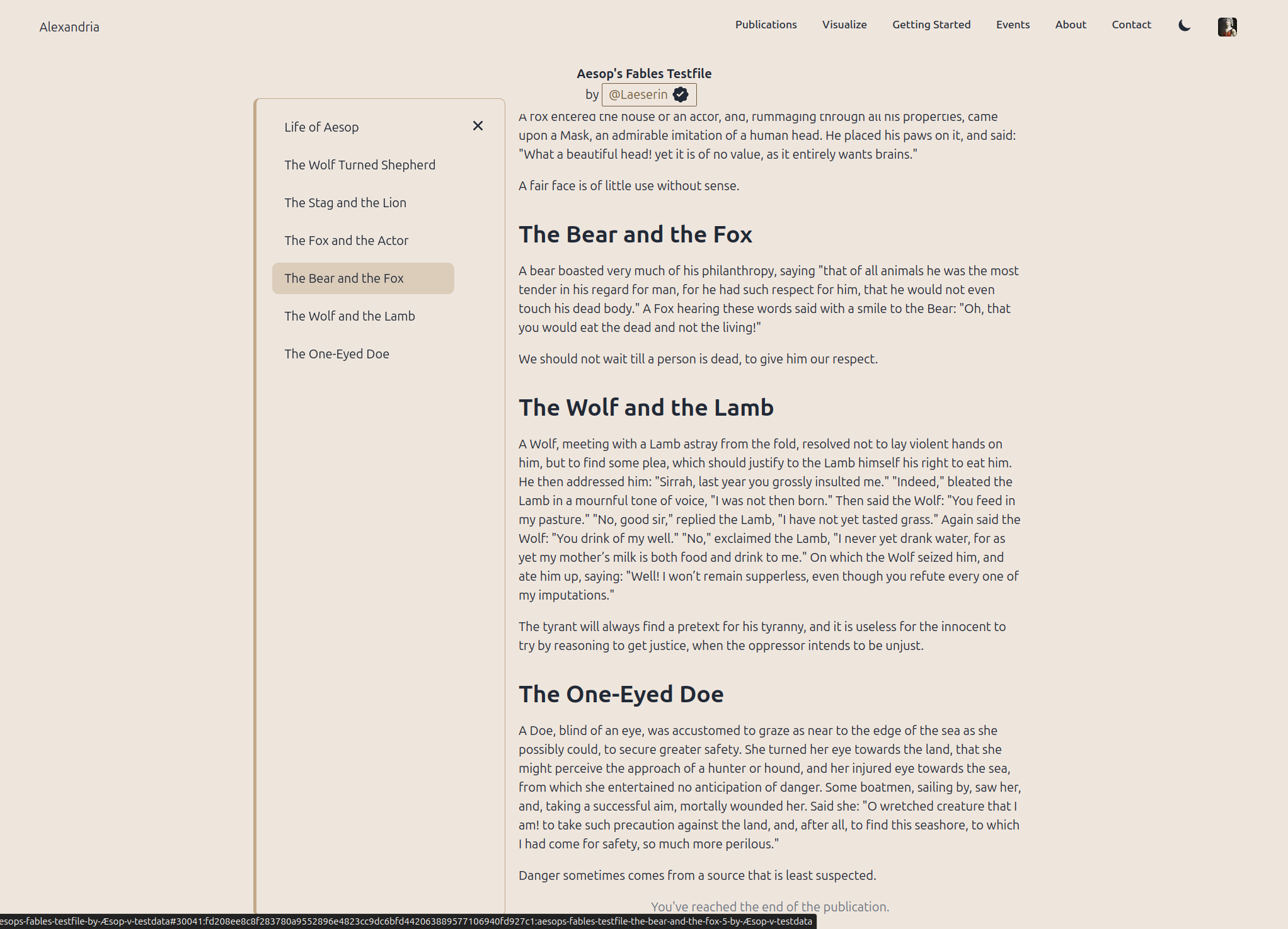
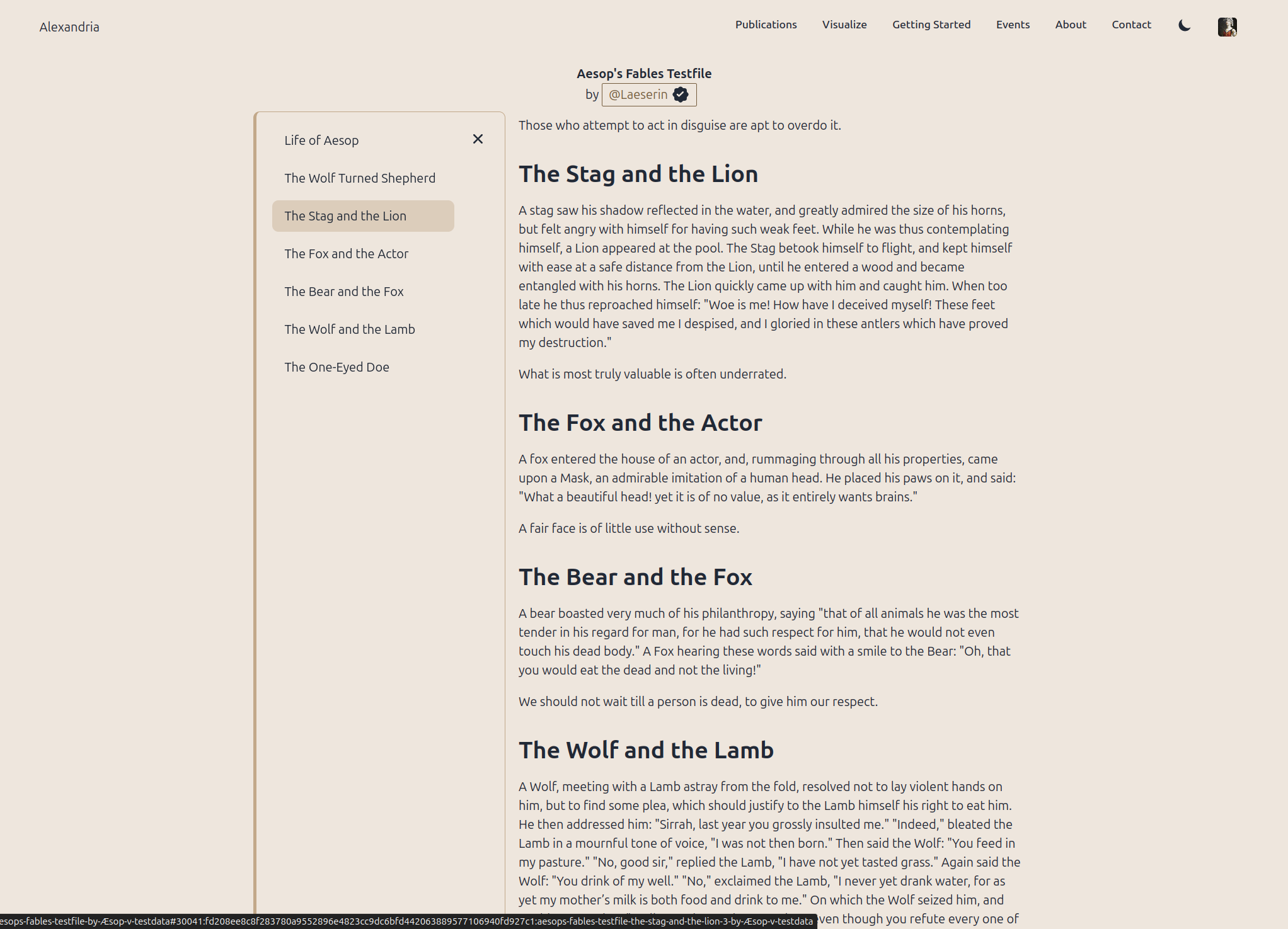
It actually almost-works, but he has to go back and rework it for blog posts, viewing individual articles (30023 and 30041) and wiki pages.
We've added npub (read-only) and amber (read and write) logins. Since we have a reader, the read-only login is actually useful for most of what you do with the app.
The landing page is now completely reactive. It loads all available publications, and displays them in pages and according to the width of your screen, with the search bar "finding" publications that you can't yet see.
The about page has a relay connection status view, which I use for testing.
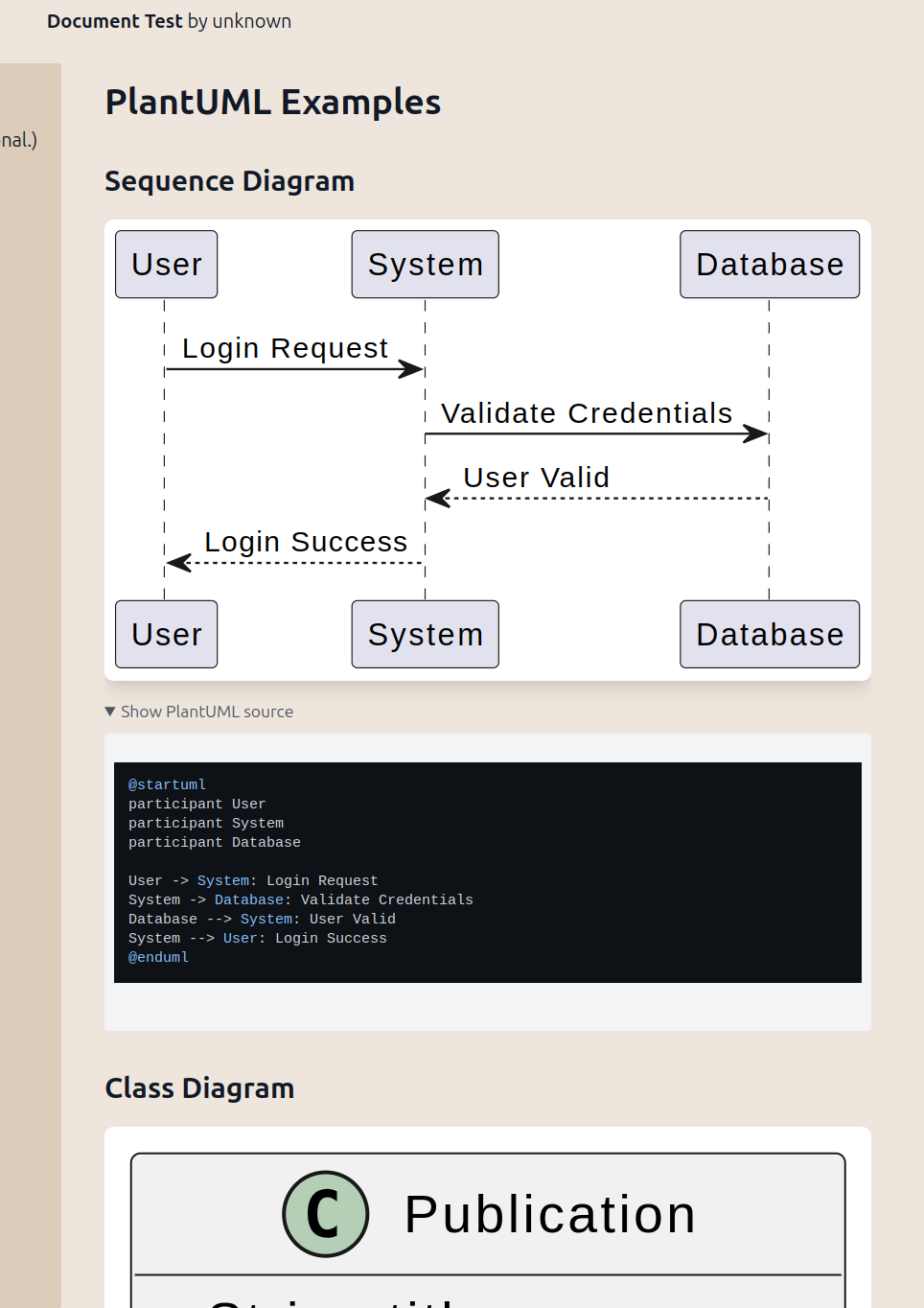
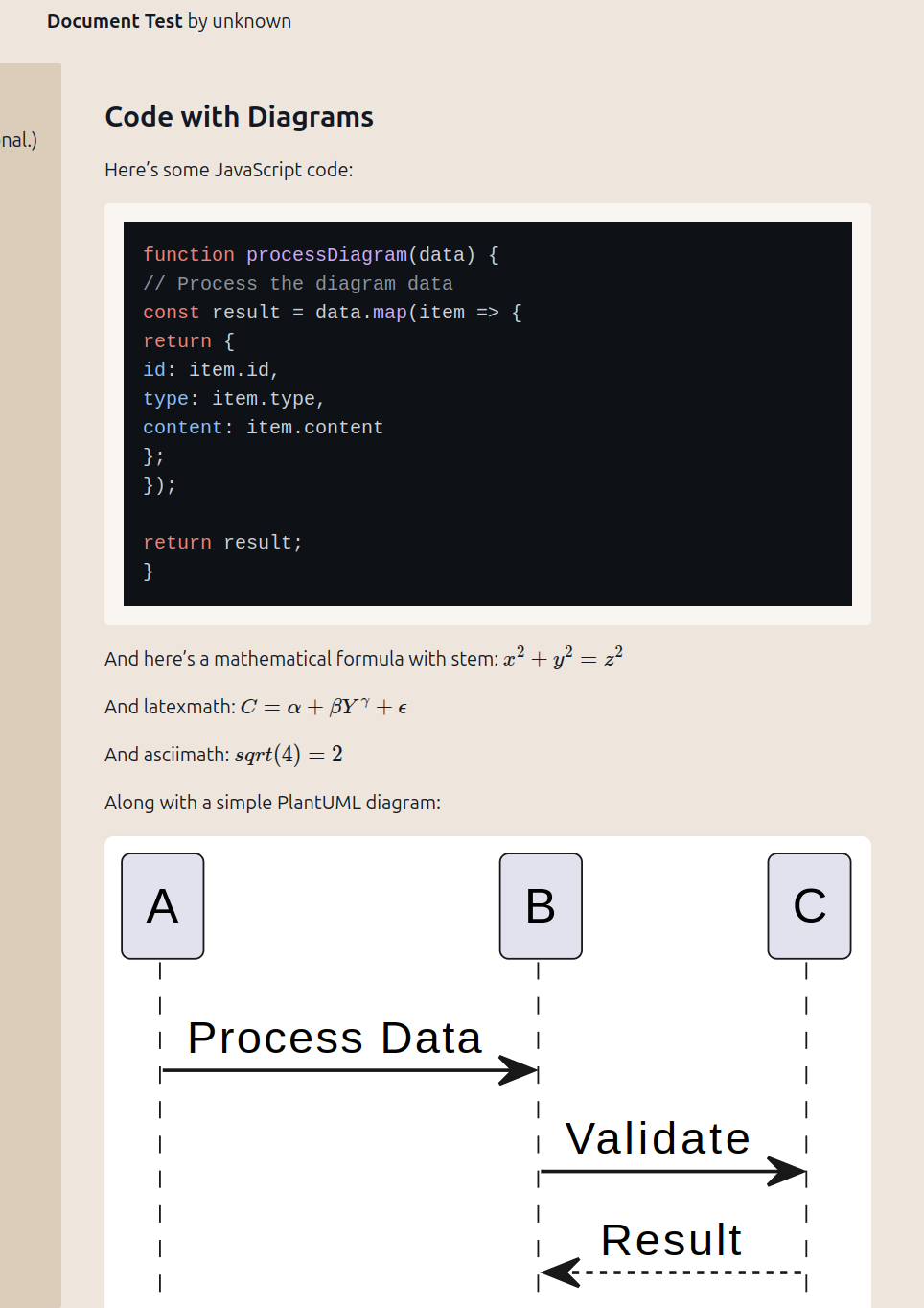
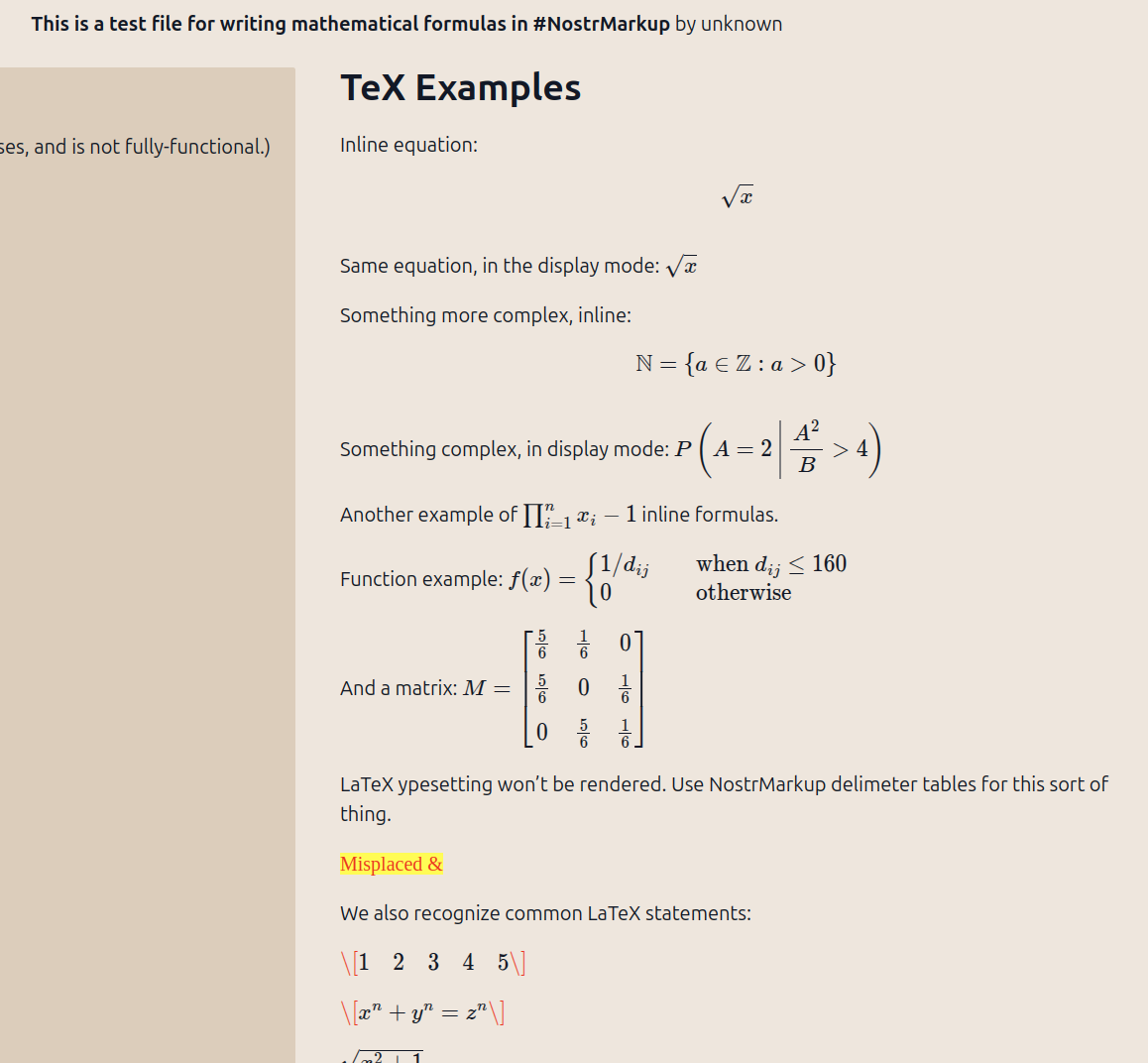
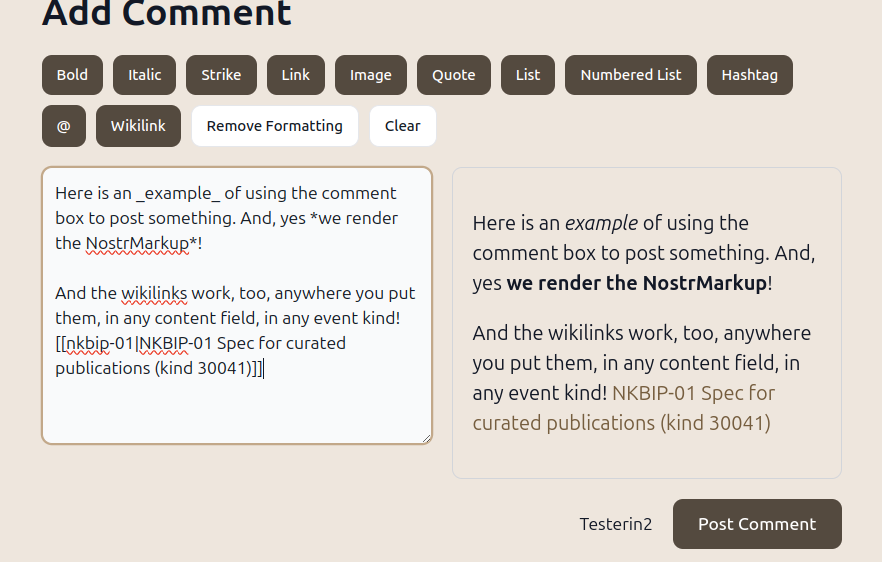
We implemented syntax highlighting, MathJax (LaTeX), and PlantUML displays, for Asciidoc and NostrMarkup parsers. Prepared it for BPMN and TikZ rendering.
30041:
30023:
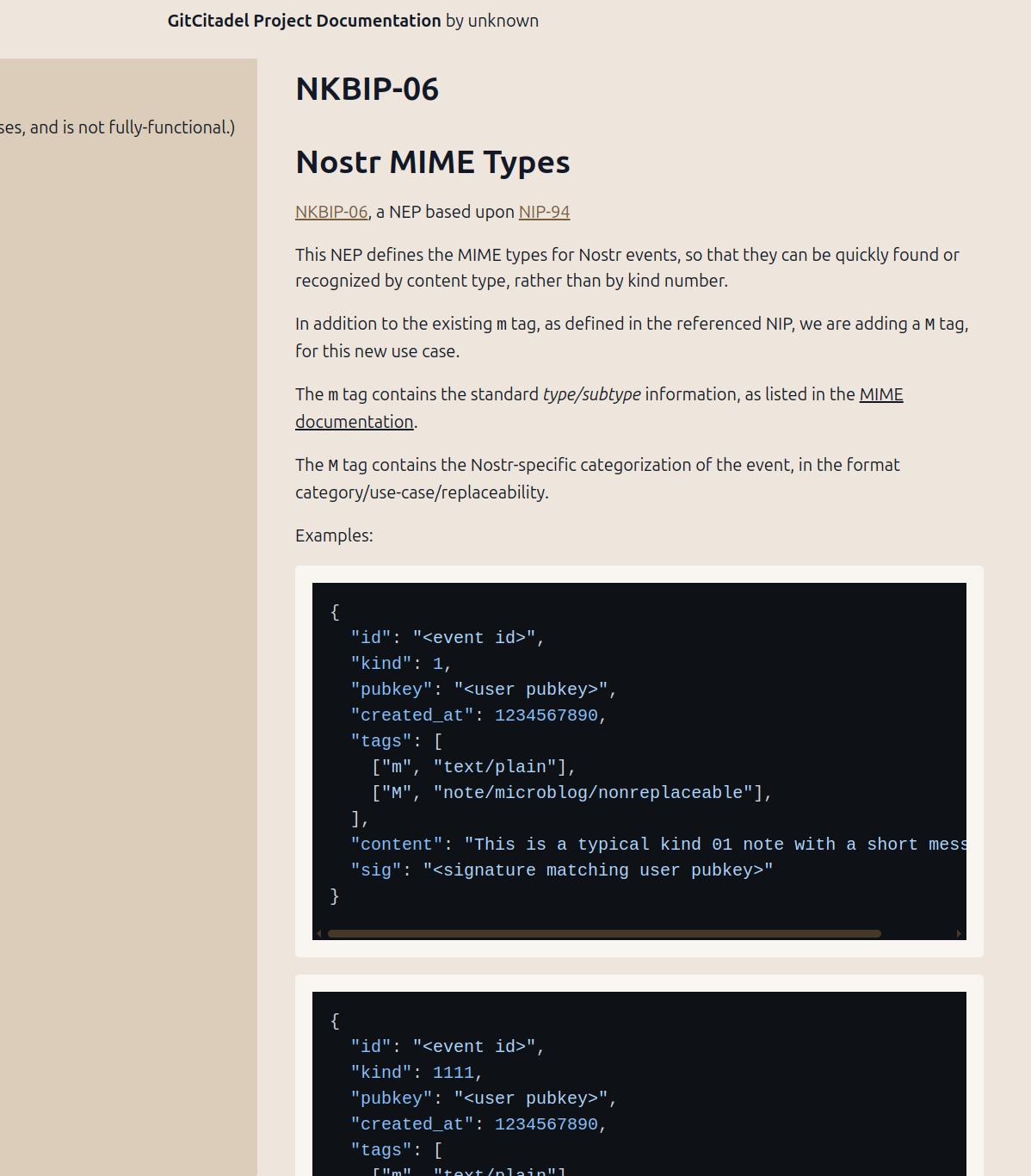
30818 (those are wikilinks, at the top, but remember that you can put wikilinks in any event, now, and Alexandria will display the link, properly, and navigate to the rendered page when clicked):
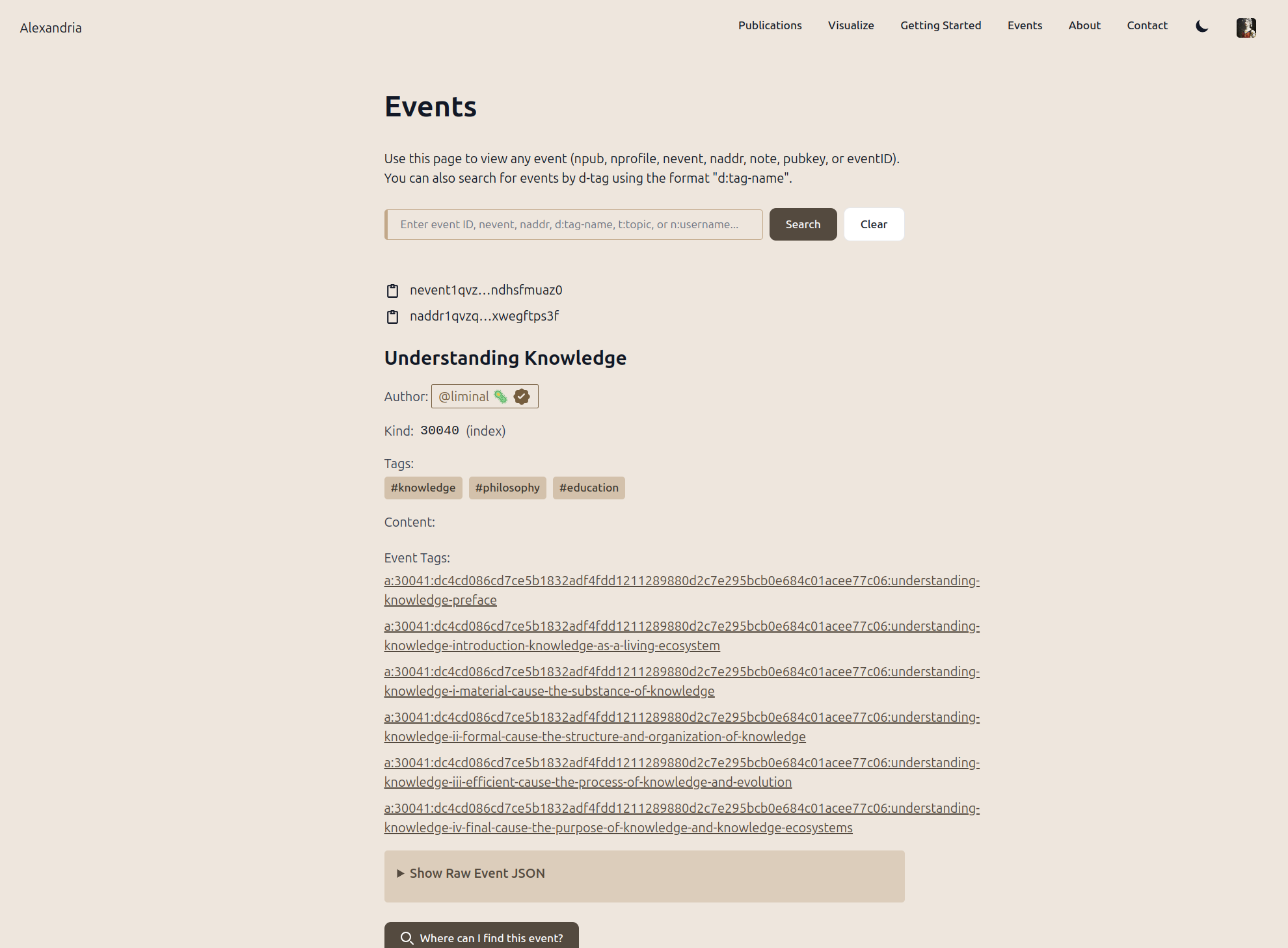
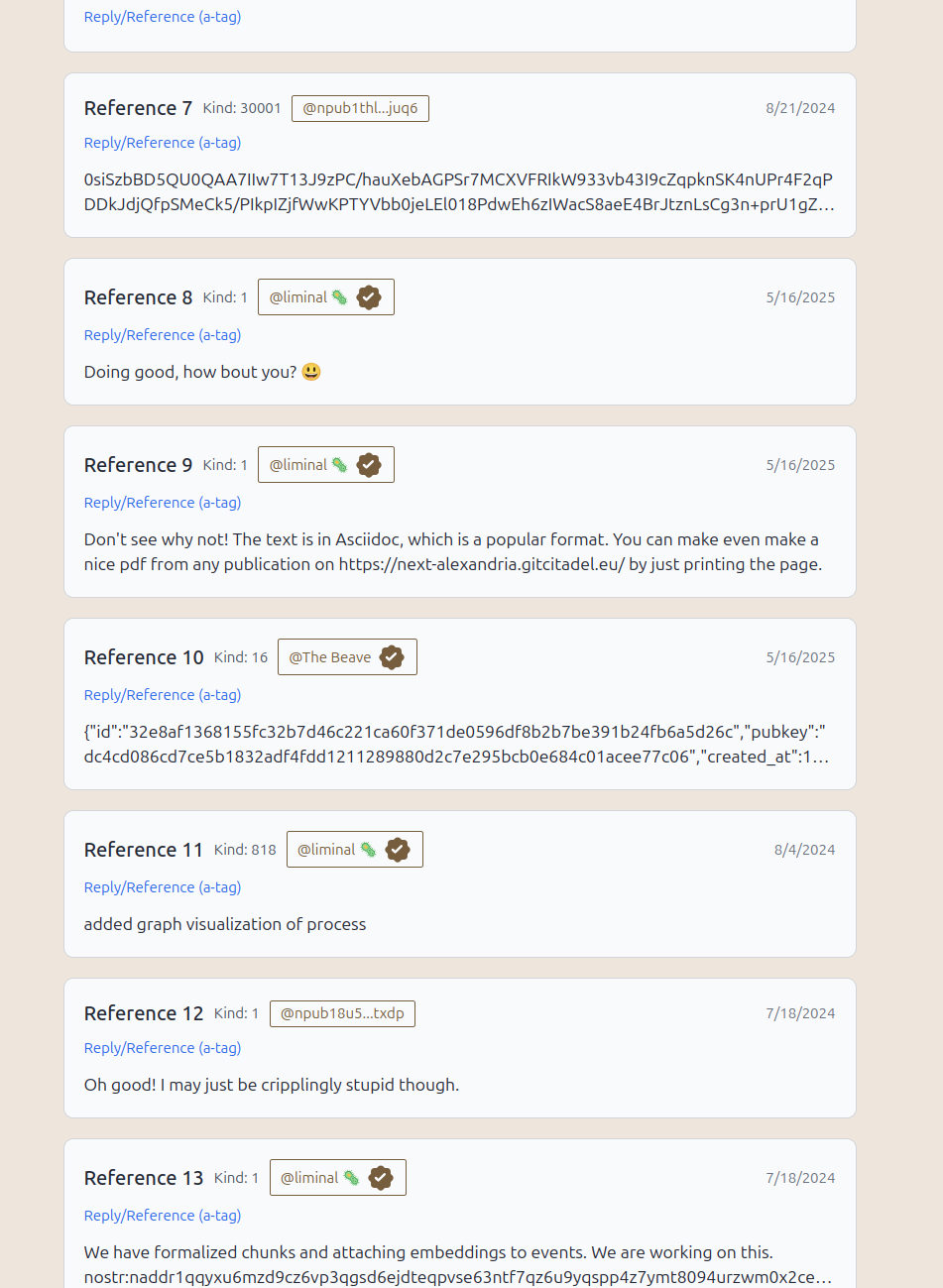
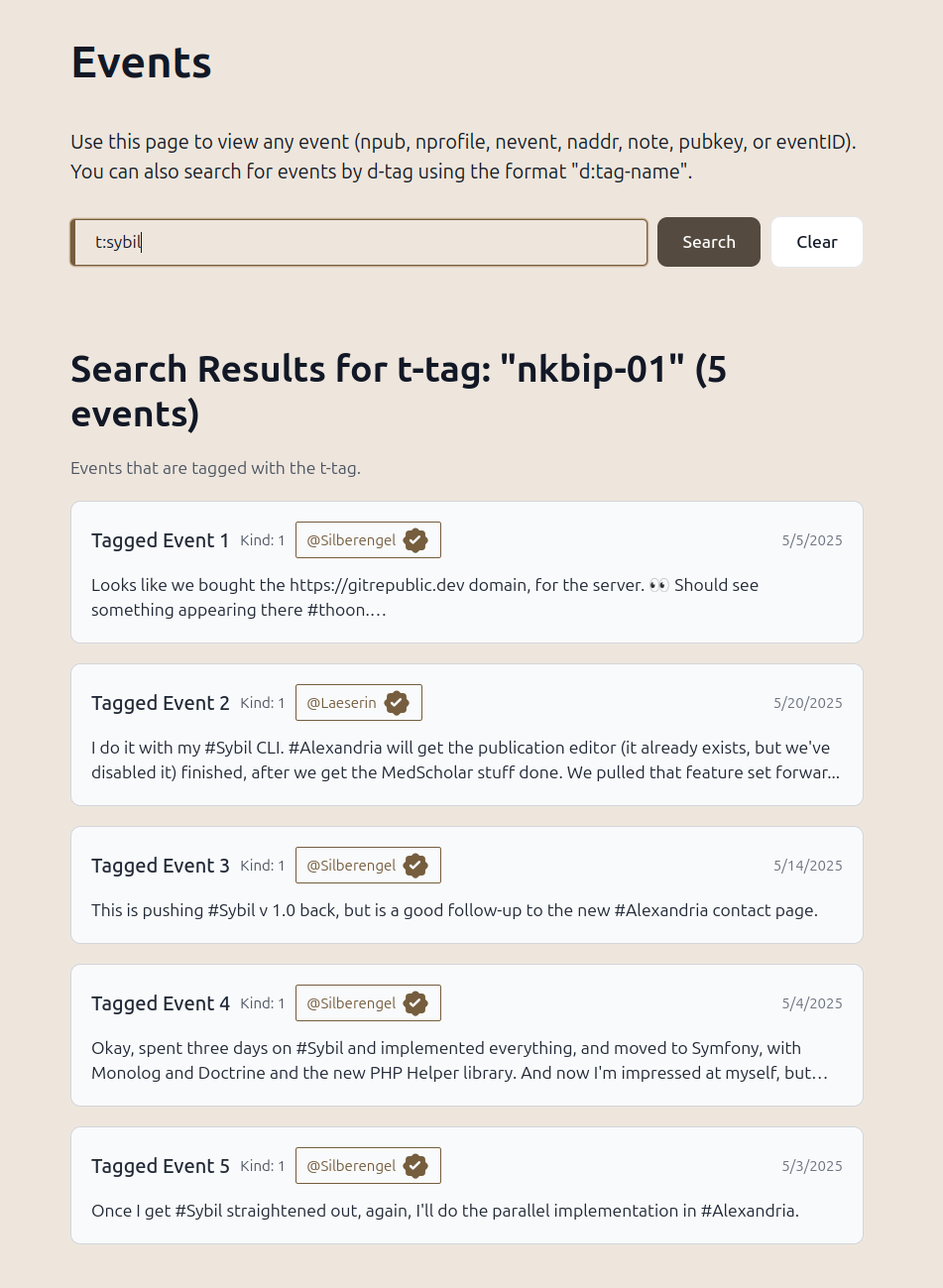
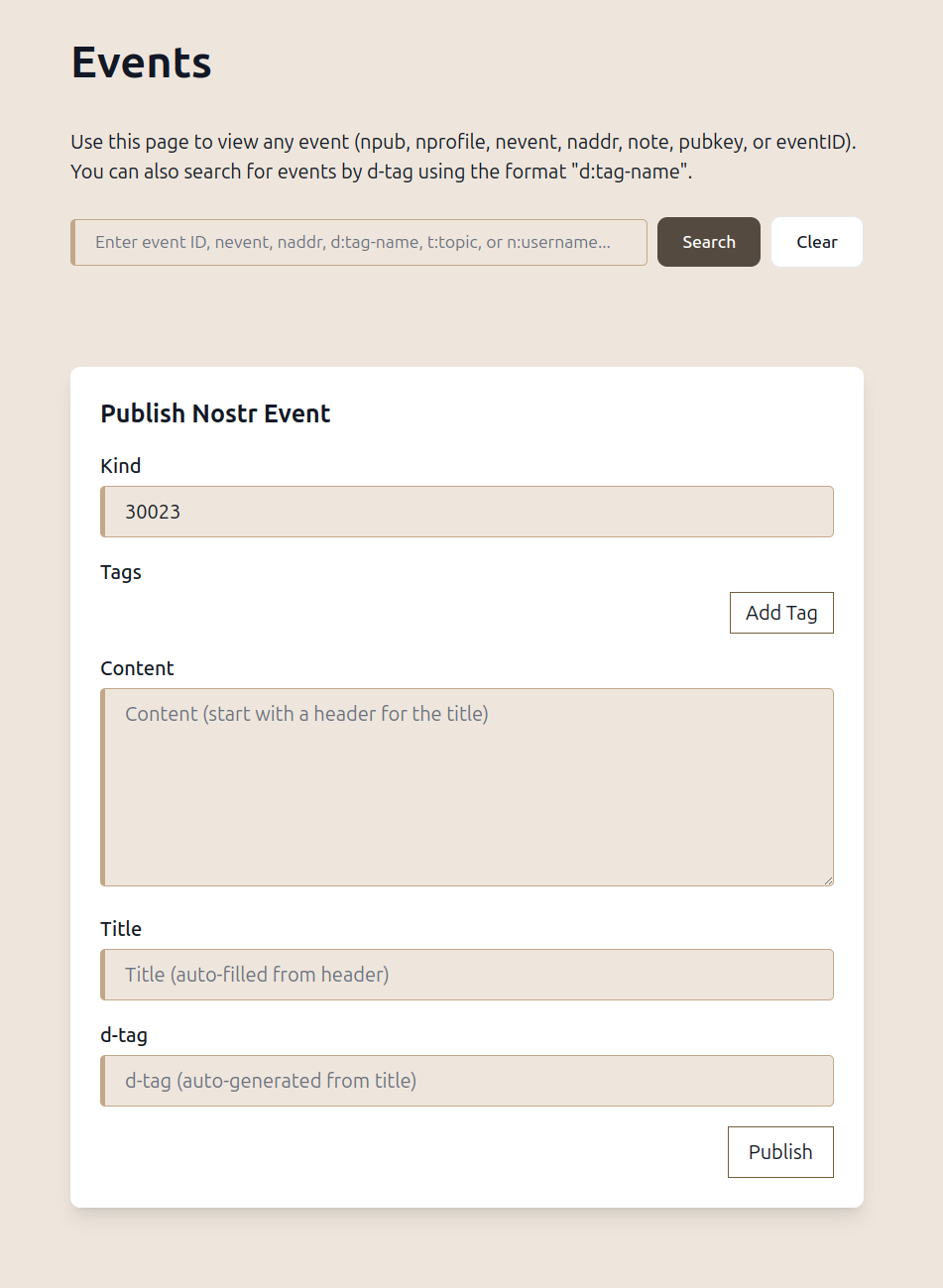
And the feature I'm already addicted to is the Events page, which allows you to search for any event, displays the event in its original state, and lets you reply to any event and publish any event (yes, including 30040 publications!) The d: search is for d-tags and second-order events (things that quote or respond to the d-tagged events found).
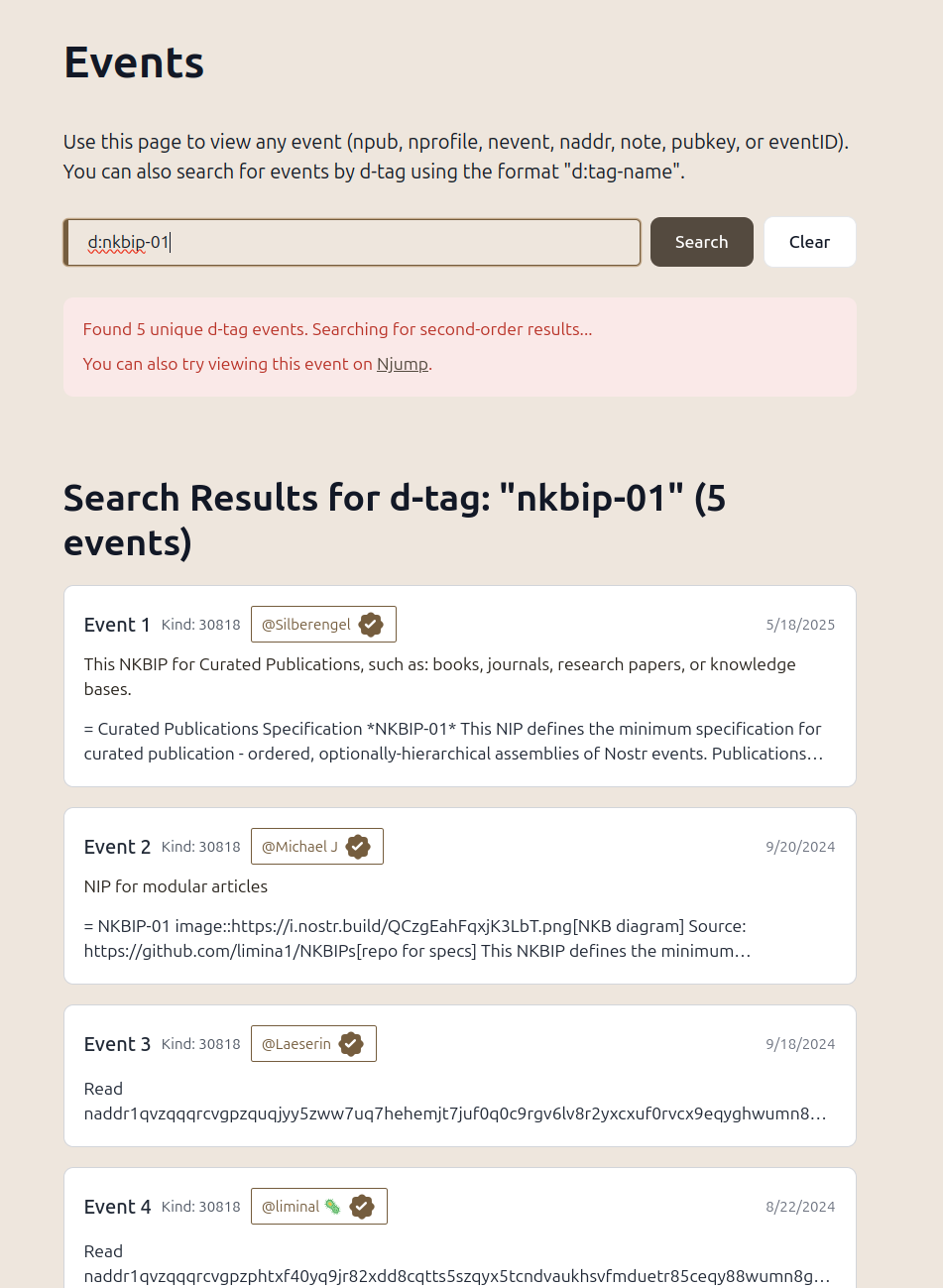
This is *not* the Awesome Search Page we're building, but just something rudimentary, to hold everyone over until GRW comes out in protoype. We need to build an entirely new architecture, based on an entirely-new tech stack, to get that working. We've officially hit the #ScriptkiddieWall, where the architects and engineers need to roll up their sleeves, to get things built.
Good thing we have some architects and engineers. 😊
But, first, they must work through the Merge Conflict From Hell.
Discussion

What y'all are doing is hella impressive. Pumping out quality work with a shoestring budget, exquisite minds, and hearts of gold.
We need to get it merged, tho. 😭
We can barely build new things because they depend upon other new things that depend upon other new things, that only exist to allow for other new things...
Concrete example is the ToC. When he started building it, we had a viewer that just loaded and displayed 30040s with 30041s listed using "e" tags.
Easy-peasy.
Then we switched to "a" tags and broke the ToC.
Okay, hide ToC and update ToC.
Then we switched to lazy-loading.
Okay, update ToC.
Then we added support for viewing individual articles.
Okay, update ToC.
Then we added support for blogs.
Okay, update ToC.
Then we added support for wikis.
Okay, update ToC.
Then we added support for longform.
Okay, update ToC...
ToC never gets merged. 😂🤦🏻♀️
So, there's now this powerful everything-viewer, but there's no ToC. Everyone like WHERE TOC??


this reads like the story of me trying to contribute to LND
Yeah, and it's a never-ending story because our publication viewer is going to support any event with a content field, regardless of kind, and integrate the display of citations, and render everything everywhere, so things are gonna get even crazier.
And the ToC just has to

And that's why nostr:npub1wqfzz2p880wq0tumuae9lfwyhs8uz35xd0kr34zrvrwyh3kvrzuskcqsyn is the one stuck in the development basement, while we all stand around and stare at him, battling the ToC on his own. Nobody else can build it and he's the boss, so the bugs stop with him.

Gitserver is the same deal, except that it's nostr:npub1qdjn8j4gwgmkj3k5un775nq6q3q7mguv5tvajstmkdsqdja2havq03fqm7 in the ditch. 😂
Me: So... you done building Thing I Don't Really Understand?
nostr:npub1qdjn8j4gwgmkj3k5un775nq6q3q7mguv5tvajstmkdsqdja2havq03fqm7 : Ummm... No, not yet, sorry. I've got to Incomprehensible Tech Blah Blah and then I need to integrate this portion of the Complex Scribbles on a White Background With Arrows and Boxes diagram and then nostr:npub1ecdlntvjzexlyfale2egzvvncc8tgqsaxkl5hw7xlgjv2cxs705s9qs735 will move on the Etc Etc Something Something script thingy.
Me: Oh, okay. Umm, okay. Sounds great. Well, I built an app that integrates all of that and I've got 18 PRs all set up for your review. So, look at them, when you get a chance. But finish the other stuff first, real quick. Whatever it is.


Apologies for the delay.
I truly am sorry for being unable to find enough for time to push it through 😢
also, there probably is a problem in that you need to have the titles of sections in the index event? as the third or usually "relay" field of the tag? otherwise you'd end up having to load and parse all the sections which i guess you already sorted this out but just made me think of it because a ToC on a segmented document has to have some reasonable text to load without touching the segments
The section headers get removed from the content and placed in the section events' "title" tag, with discrete headers untouched.
We lazy-load the sections, as you scroll down and as you open up levels in the ToC. We therefore have to handle someone opening up a level in the ToC, that hasn't been loaded into the reading panel, already, like a fast-forward viewer, but just of that section. The sections inbetween get filled in, as they scroll toward the already-renderd sections.
Or something like that. I think. 😂🤷🏻♀️
When you try it out, it is really underwhelming. Click ToC text, jump to section in publication.
That the publication can have 30k sections and you've only loaded the first 200, but you can still jump to sections 8018-8020, and render them on the fly, is completely invisible to the user.
But that's the Biblical use case and we promised that would work, so we're making it work.