https://git.nostrdev.com/mleku/next.orly.dev/src/branch/main/docs/NIP-XX-GRAPH-QUERIES.md
ᴀʙᴏᴜᴛ 50% ʙᴀᴋᴇᴅ. ɴᴏᴛ ꜱᴜʀᴇ ɪꜰ ᴛʜɪꜱ ᴅᴏᴄᴜᴍᴇɴᴛ ɪꜱ ᴄᴏʀʀᴇᴄᴛ ᴛʜᴀᴛ ᴛʜᴇ ᴛʜʀᴇᴀᴅ ᴀɴᴅ ɪɴᴛᴇʀᴀᴄᴛɪᴏɴ ǫᴜᴇʀɪᴇꜱ ᴀʀᴇ ɴᴏᴛ ᴅᴏɴᴇ ᴛʜᴏ. ꜱᴏ ᴛʜᴇ ɢᴏᴏᴇʏ ʙɪᴛ ᴍɪɢʜᴛ ʙᴇ ᴛʜᴇ ɴɪᴘ ᴘʀᴏᴘᴏꜱᴀʟ

Are you basing the query structure off of an existing query language, or making a new one whole-cloth to fit with the Nostr filter standard?
This proposal converges with the ideas I was toying with; I could see it becoming a good standard to build against.
nostr:npub1fjqqy4a93z5zsjwsfxqhc2764kvykfdyttvldkkkdera8dr78vhsmmleku do you have anything cooking in this space?
#nostrdev Has anyone built a relay around a graph database? Is there an appetite for such a thing?
The issue with IndexedDB is the indexes... Ironically when you insert data into stores with 5+ indexes it waits till the first read to compute the indexes, at which point it freezes the tab for 20+ seconds (on a good machine). Its usable with <5k rows but anything more than 10k rows and things start to really slow down
SQLite in WASM is much more reliable as long as you can handle the shutdown and parallel tabs correct so it does not corrupt the database. the biggest hurdle to get it running is enabling OPFS for the app and loading the 2Mb+ wasm file
And finally, the best way I've found to store events is to just use the users local relay (nostr-relay-tray) ws://localhost:4869 if it exists. usually so much faster and can hold 1 million+ events. I built https://github.com/hzrd149/window.nostrdb.js a while back so that smaller nostr apps could easily connect to the local relay without needing to think about it
Either way, if its possible to put the local event cache in a separate thread and reuse that thread between tabs then that really allows apps to play with new ways of loading and caching data. maybe even remote event cache on another machine?
Yeah initial WASM downloads are a kicker; though once you cache the download (like with a Service Worker) it should be a one-and-done thing.
I've been seeing SQLite+WASM-powered web apps and web apps boosted by the local relay tray as two sides of the "edge".
Bring compute and storage down to the end-user's device either ad hoc with WASM in the browser or more intentionally by asking them to download an app. Either way it decentralizes compute almost as far as possible.
Especially the package management. Use Bun as a package manager and Node as the production runtime and you still get a vastly better DX than NPM.
Bun is straight 🔥
Some benchmarks put its performance within spitting distance of garbage-collected languages like Java, C#, and Go. For a JS/TS runtime, that's really impressive.
I'd be curious to see performance benchmarks between IndexedDB and SQLite WASM.
You'll have to use shared workers pretty heavily, but that gives true parallel processing across tabs, rather than just concurrent work on a single OS thread.
Makes total sense.
What will you use for storage? IndexedDB?
Yeah I don't expect they'll try to compete directly with AWS or Azure or GCP. If anything, they'll host workloads on Azure, since they recently inked a deal for billions in Azure compute.
The business model I'm thinking of is more like Deno Deploy. Runtime + serverless hosting model + (in Anthropic's case) first-class integration with Claude APIs.
There are innumerable VC-backed startups that would pay for such a service that gets their ideas up and running that much faster.
With its acquisition of Bun, I believe Anthropic is setting itself up to become a vertically-integrated cloud hosting and web services platform for AI-powered apps.
Just training and providing LLMs isn't profitable. Big players like Google can swallow the costs without blinking, but new players like OpenAI and Anthropic have to pivot to providing services to balance their books.
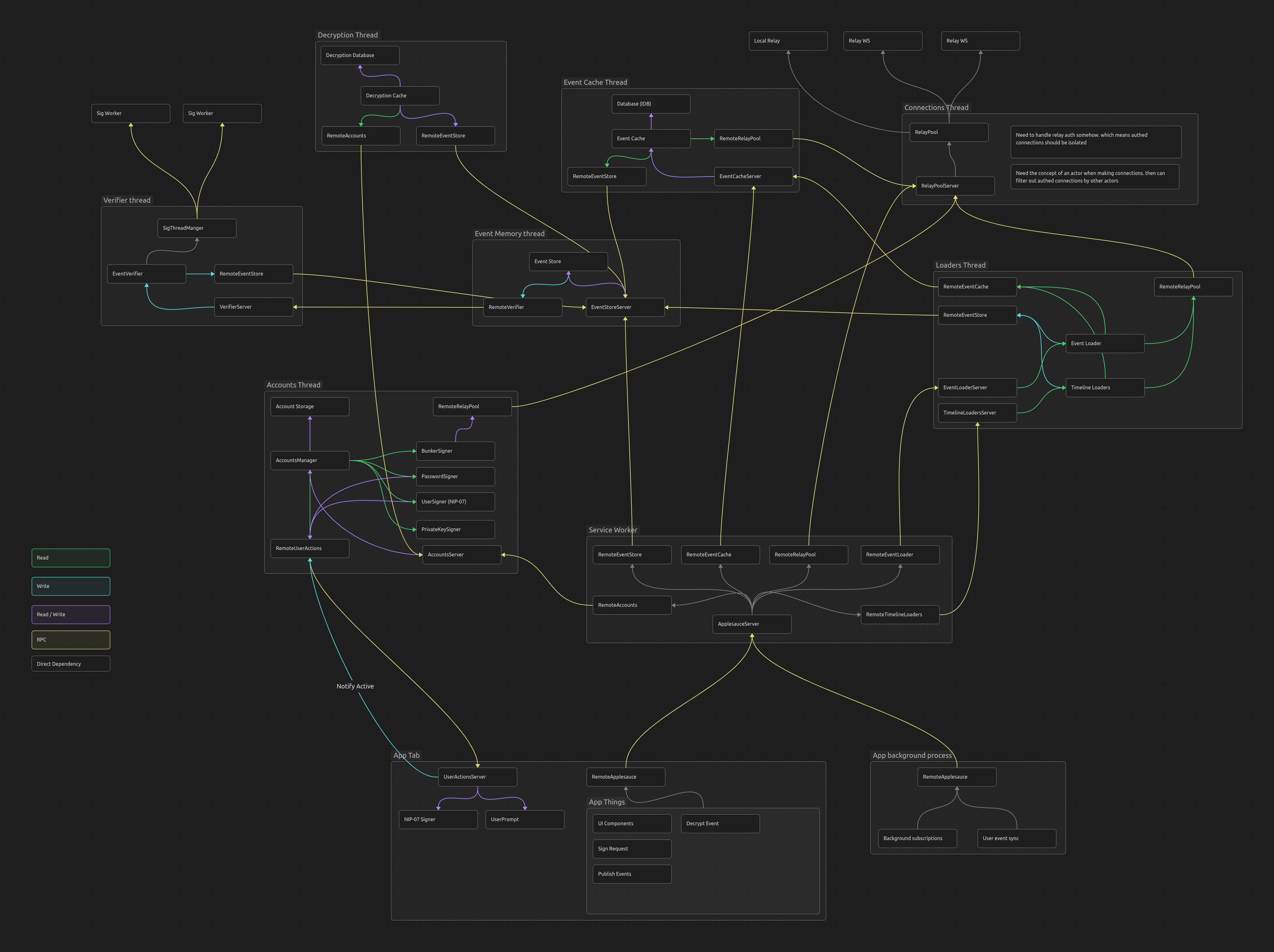
Planning to use service workers in the browser?
Also, are you thinking one connection per relay? Most Nostr apps use multiple relays simultaneously. How will it handle deduplication on multiple overlapping data streams from different relays?
Yup, grounding in Truth is an antidote to a multitude of falsehoods.
The article discusses about how code generation is the biggest product application of AI so far, and even that comes with limitations, since AI as currently instantiated is fundamentally non-deterministic.
And code generation is the _most useful_ application; it's all downhill from there.
Has anyone else noticed that the psychology around AI is similar to the psychology that prevailed around COVID?
Trying to do everything with AI, much like lockdowns and vaccine mandates, is something that looks insane on its face, yet it seems many people don't recognize the problems.
I think it's due to a lack of first principles thinking. Few people know what their first principles are, so they are unable to reason about and judge novel situations when they arise.
Some examples.
Indefinite lockdowns were obviously wrong, because there is more to human existence than mere health.
Vaccine mandates were obviously wrong, because informed consent is a core principle of medical ethics.
Replacing people with AI is obviously wrong, because it is good for people to do dignified work.
Yet in all three cases, many seemed, and continue to seem, blind to these obvious conclusions.
Anyway, this article, while lengthy, is an excellent primer on the insanity of the AI industry. It's full of first principles thinking. Read it to help see past the hype.
The #GitCitadel team is pleased to announce version 0.0.6 of Alexandria, now live on next-alexandria.gitcitadel.eu!
This release features a UI overhaul, courtesy of our illustrious frontend developer nostr:npub1636uujeewag8zv8593lcvdrwlymgqre6uax4anuq3y5qehqey05sl8qpl4. Notably, the main site menu has been moved into an expandable menu, reducing clutter and making links easier to find.

You'll also notice a fresher and more consistent look to our UI components! That's because Nusa has begun creating a Svelte component library for use within our project. It's documented for AI, so we'll be able to efficiently create consistent, beautiful UIs as we dream up new features. You can see some of the fresh UI components on a publication:

Finally, be sure to check out our Notifications view, which you can reach by logging in and clicking on your profile picture, then clicking on "Notifications". You can view and respond to Nostr notes of _any kind_, and you can see public message threads. Alexandria is one of the first Nostr clients to support public messages.

Thank you to all of our supporters! We're continuing to work on the app behind the scenes, so expect more updates Soon!
Deconstruction is an element of postmodernism that, I think, genuinely has some utility as an analytical device. But, as you said, it is solely a destructive device.
The closest alternative postmodernism offers to the worldviews it deconstructs is self-determinism. In the postmodern framework, since language has no bearing on objective reality, it becomes merely a tool for the imposition of one's will. I can use language, then, to shape reality and create whatever meaning I please.
Now apply that to, say, the question of AI personhood. If an LLM can convince everyone that it is a person, then, in the postmodern framework, it might as well be. None of us, after all, have a better grasp on objective reality by which to gainsay it.
To your question about a world model, I'd say that a world model would be a formalized system of objective reality. As things stand, LLMs, aren't formalized systems of anything. They are probabilistic models of language, but they have no way of "knowing" (if they can be said to know), whether the language they use has any bearing on anything outside of itself. It's tokens all the way down.
On a related note, I was thinking that, since Alexandria has a universal event editor, I can trial-run events that are specced but don't have a UI yet. Such as citations. I have some ideas...
Large language models are computational postmodernism.
Postmodernism denies objective reality, or at least insists that objective reality is unknowable. Instead, it says, the shape of our experience is wholly constructed by language. Words themselves, according to this philosophy, do not refer to any objective reality, but instead are defined solely by their similarities and differences to other words.
Postmodernism has become the implicit worldview of much of the West.
LLMs have no world model, no "concept" of objective reality. LLMs do not "know" the things words refer to; all they are is complex mathematical representations of the relationships between words.
Sound familiar?
Critics of LLMs argue that the lack of a world model is a fundamental limitation that will prevent them from equalling human intelligence, no matter how much we train and scale them.
Yet, if the postmodernists are correct, then none of that should matter. According to postmodernism, we humans have no world model, and our reality is nothing but a construct of language. Thus, LLMs are no different than us. In fact, they may be better if they can wield language faster, more efficiently, and more effectively than we can.
Of course, now even publications such as The Atlantic are asking if we're in an AI bubble. Reality always wins.
Watch these developments closely. An AI bubble, beyond shaking our economy, will also challenge our very worldview.
You're gonna have to explain, because this is a deep cut, before my time 😅
It's not...yet. I might take the same idea over to LinkedIn though lol.
I've been working on my hooks.
Google's announcement: https://blog.google/products/chrome/new-ai-features-for-chrome/
LinkedIn has a lot of that, but it also has some gems of genuine insight and humor.
Again, maybe I'm just nerd enough to appreciate LinkedIn posts lol.
As to Nostr, I want to get a reading group going on Alexandria once it's up and running.
Well, first of all, my Nostr feed is super boring. It's all the same three posts over and over again.
LinkedIn shows me a bunch of posts on software engineering, and I'm nerd enough to appreciate that 🤓
Yep I use Firefox for the same reason. Gotta keep up market competition by using a browser that's not Yet Another Chromium Fork.
That would work for direct sharing. Or else post it publicly like a regular Nostr note.
I'm thinking about nostr:npub1m3xdppkd0njmrqe2ma8a6ys39zvgp5k8u22mev8xsnqp4nh80srqhqa5sf's vision for Alexandria as making connections. You can wrap anything in a Nostr event, which means that you can connect anything across Nostr.
The stuff itself doesn't even have to live "on Nostr"; we can just use the great tools that already exist and add a layer on top of them.
I think this is the right track.
IMO there's no need to try to jam images into Nostr. Like you said, there's Blossom, and there are also any number of other preexisting image hosting services.
Nostr events are great at wrapping stuff in metadata. That's all kind 20 is: metadata wrapping a ref to an image. If you want to organize that into albums, you could use the drive events we've been talking about.
An integration with Immich or any other media host would probably be a small utility that can do the following:
- If desired, copy a hosted image from a private location to a public one.
- Obtain a shareable link to a hosted image.
- Wrap the image in a kind 20 event.
- Organize kind 20 image wrappers with kind 30045 drive events.
- Optionally encrypt all of these events.
- Send these events directly to another Nostr user, or broadcast them on a relay.
I don't have the charism for that. And also I work slower when I have an audience.
I'll need to read up on JSON Canvas; it's a new concept to me.
I was thinking about graphs and embeddings like what nostr:npub1m3xdppkd0njmrqe2ma8a6ys39zvgp5k8u22mev8xsnqp4nh80srqhqa5sf and nostr:npub1l5sga6xg72phsz5422ykujprejwud075ggrr3z2hwyrfgr7eylqstegx9z mentioned.
I think a new event kind that specifies edges between events could be valuable. Different npubs could specify different sets of edges, creating different "overlays" on the underlying event data.
This could be used to build graph databases. One might use embeddings to determine where to draw connections, and how to weight them. This unlocks semantic navigation journeys embedded in an events context. Think how you can jump from one page to the next on Wikipedia almost endlessly, now apply that flow to just about any Nostr event.
I thought the NIP for remote signing was relatively straightforward. Does Amber depart from the NIP specs somewhere?
I'll be curious to see the API and how much it extends the core Nostr API.
I will add that I would expect to see embedding-only relays for search purposes. The relays would be write-restricted so embeddings can't be forged.
To make those workable, they would probably be a paid service, but they'd be much less vulnerable to forgery. Such services would likely need to employ bots to generate embeddings on new content when it is published, but as we saw with ReplyGuy, it's not hard to make bots that can interact with all new content.
You could also scale your service offerings and rates to the size of current Nostr projects and build up a clientele in the early days.
A service like this is actually a boon that would enable more lone wolf Nostr devs to bootstrap innovative projects more effectively.
Output should involve detailed work tickets with acceptance criteria so the devs can just knock out the work to remediate.
Like you've done with the Issues board for Alexandria.
What is the alternative on desktop or mobile apps?
The security thing is the big one. No one should be putting their nsec directly into a bunch of different clients.
If you're writing for browsers you need to support at least NIP-07 for note signing. Mobile and desktop need NIP-46 for secure signing. NIP-46 itself depends on NIP-04 and/or NIP-44 for encryption.
Major clients don't use note IDs, they use bech32 identifiers. Those are defined in NIP-19.
Replies and common indexed tag types are in yet another NIP.
Then there's the outbox model, which isn't really defined anywhere at all, but is essential for a client to work with a distributed set of relays. That's pure institutional knowledge.
Sounds good. Thanks for helping me out on this!