
local llama3.2 on your phone https://apps.apple.com/us/app/pocketpal-ai/id6502579498
Discussion

Want to run bigger models and retain some privacy also check out https://venice.ai/what-is-venice

You might also like Private LLM
https://apps.apple.com/us/app/private-llm-local-ai-chatbot/id6448106860




thanks for sharing 🤙

do you know what this is ? nostr:npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s 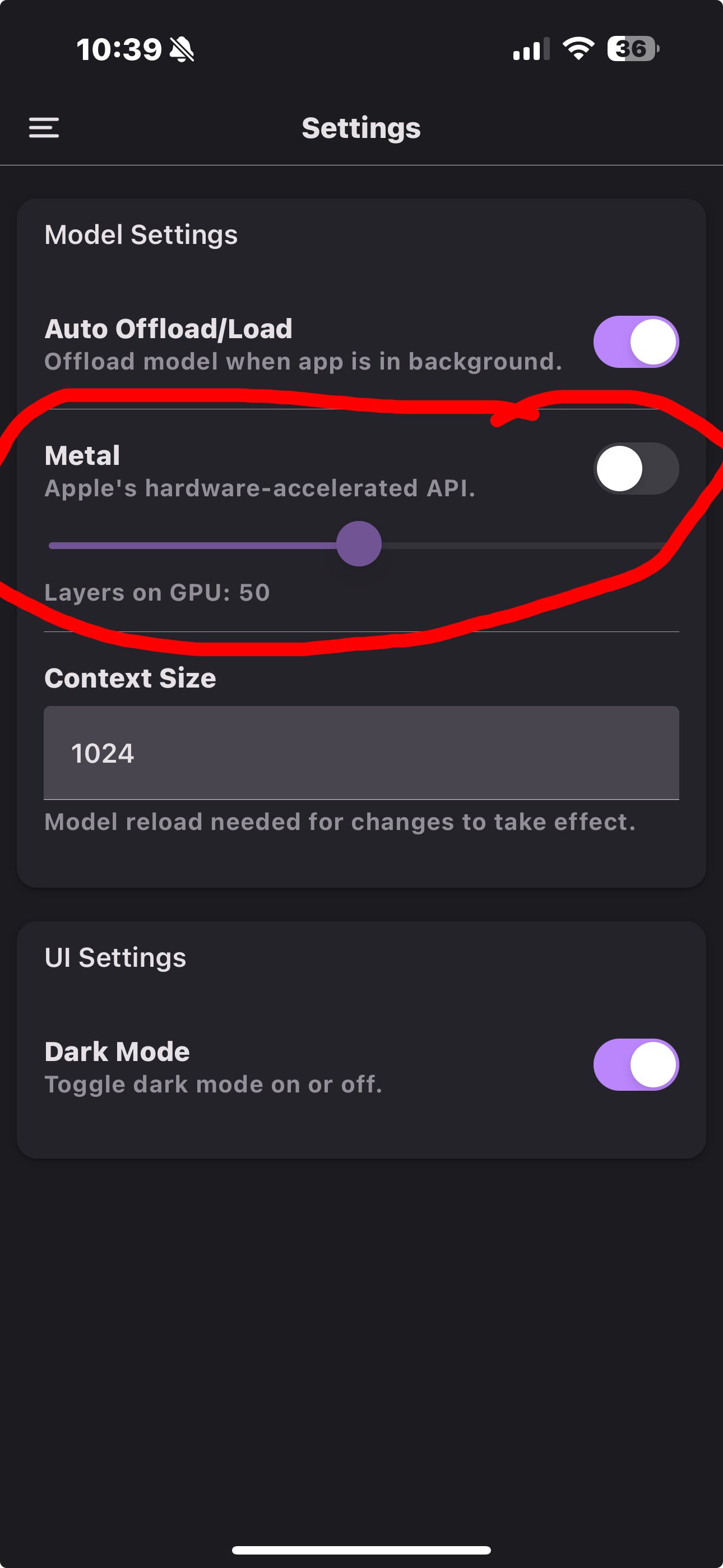

Use gpu instead of cpu? I would think you would want that on 🤔
that’s what I was thinking.. what would you recommend for layers on GPU, default 50 or 100

Depends what your device can handle. Think of it like this: the full model might be 4Gb, if your device has 8Gb it might fit in memory, so 100% of the layers can be loaded there (and still have some room for the system and apps and such). But if your device has only 6Gb or 4Gb, the whole model will not fit, so you will need to test if 50% can be loaded into memory, or maybe less. At some point it might not make sense to use the GPU if only too little layers are loaded there, since the overhead of combining CPU + GPU work can predominate. Also, you need free memory space for the context window, so bigger contexts will consume more space and leave less space for layers, while smaller context leaves space for more layers.

Looks like I can cancel my chat GPT subscription now. I don't get why Microsoft building all these data centers when my phone can do the exact same thing..
seems like massive mal investment.
Meh. Get a gaming GPU with 10GB+ VRAM run Ollama + Open WebUI, then set up a wiregaurd VPN to the machine connect to it on your phone and run much more powerful models.

I seem to recall that Ollama has some shady code that is probably harvesting your data.
