The encoding (function string -> number vector ) is part of LLM magic, a common first step of various ANN enchantments (which the magicians also don't understand, don't worry). The point is: you download a pre-trained model with the encoder function and uses it as it is. On this thread @sersleppy posted a blog with an example:
https://huggingface.co/blog/embedding-quantization#retrieval-speed
Embeddings are supposed to reflect content (semantics, but this may be too strong a word). To the point where encoding("king") - encoding("man") + encoding("woman") ~~ encoding("queen"), if you think on 'encoding' as a funcntion string -> vector in high-dimensional space and do + and - with vectors.
Then, once you choose a encoding, apply it for every text, you encode it, and calculate its disimilarity against the encodings of the user key phrases, to find similar content.
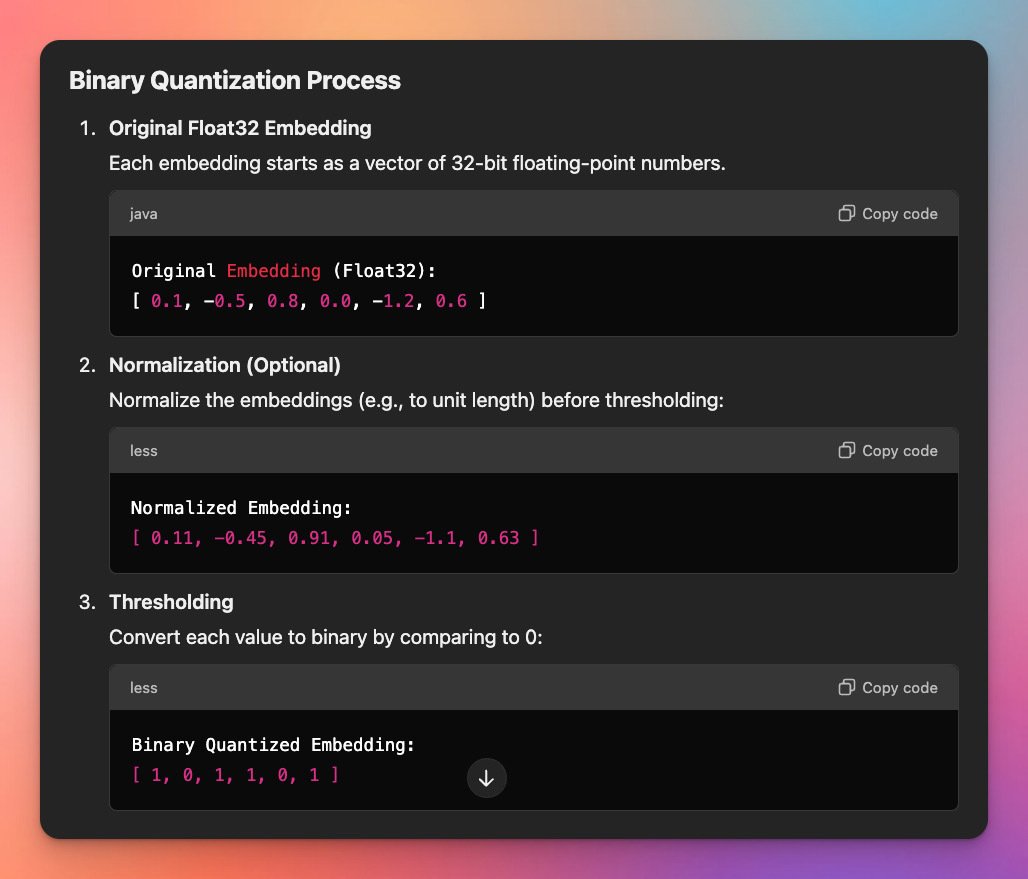
Conceptually, the binary encoding is the same. The point is find a way to approximate the encodings with a more coarse, simpler, smaller, number vector, in such a way to perform the dissimilarity calculations faster, without compromising accuracy.
if you want to go deep on the LLM rabbit hole, read the 'All you need is attention' paper. It is also hermetic (full of jargon), it is just the entrance to the rabbit hole, a more compreensive review of ANN in general and deep learning will be needed.