gathering numbers based on users is tough on nostr because what would you base it on? how do you tell if its a user, or a scraper gone wild?
I'm sure nostr:nprofile1qqs06gywary09qmcp2249ztwfq3ue8wxhl2yyp3c39thzp55plvj0sgprdmhxue69uhhg6r9vehhyetnwshxummnw3erztnrdakj74c23x6 could come up with a test plan, but all i can see is #connections, and periodic latency smokepings (doing a simple REQ)
ive seen one strfry handle up to 8000 simultaneous connections, but that just means someone left their connections open.
one performance thing is in my mind, there is a very real difference between a nostr aggregator and a relay. if you are doing aggregation and search, you have different needs for your data pipeline than normal client-relay nostr usage.
since outbox model is still barely used, not many actual users are connecting to regular relays, they only connect to primal or damus.
anyway, not sure why im bothering saying this, if you want to build a better relay I'm all for it. i guess im just annoyed at performance comparisons i cannot confirm myself (closed source). nostr clients dont even judge a relays performance other than a websocket ping, so i never have received a user complaint of slowness. I use the relays daily myself and it seems just fine with minimal resources.
If an aggregator thinks they're too slow, well, they're not paying me to make their aggregation fast so it makes no sense to scale up for them. There's a reason robots.txt exists because early web was the same, a crawler could take down your site, but you wouldn't want to scale up just to help them crawl faster.
distributed systems where you dont get any heads up what people are doing, is a hard environment to work in. but strfry handles it like a champ.
Most of the clients are so inefficient that a measurement would mostly be of their own slowness. 😂
We've added result time to our Alex client success message, so that might provide some transparency.
what could be done is, have test harness that mimicks exactly the common types of requests a user does (like record what amethyst does) and play it back x1000 against a test relay with a bunch of generated data to query.
or for alex client, the typical set of reqs or events that are expected to be happening.
My smoke test with Playwright will be timed, and I could run it in parallel across a set of relays, on an hourly basis, and then post pretty trend diagrams on https://status.gitcitadel.com .
if its a stress test, i wouldnt do it on live relays, but a periodic ping of what a client would do in separate geolocations x1 is useful
I said smoke test, not stress test. It's just one happy path e2e in a headless browser.
i call it "smokeping" because there was a cool monitoring tool called that, written in perl back in the day.. it was my #1 fav thing for seeing status of the end to end service and it's trends over time.
Thread collapsed
Thread collapsed
i do this and publish as nip66 latency events and to influxdb for querying. very useful, not on the same network as the relay (geo distributed). It connects and does a simple REQ, records total latency. 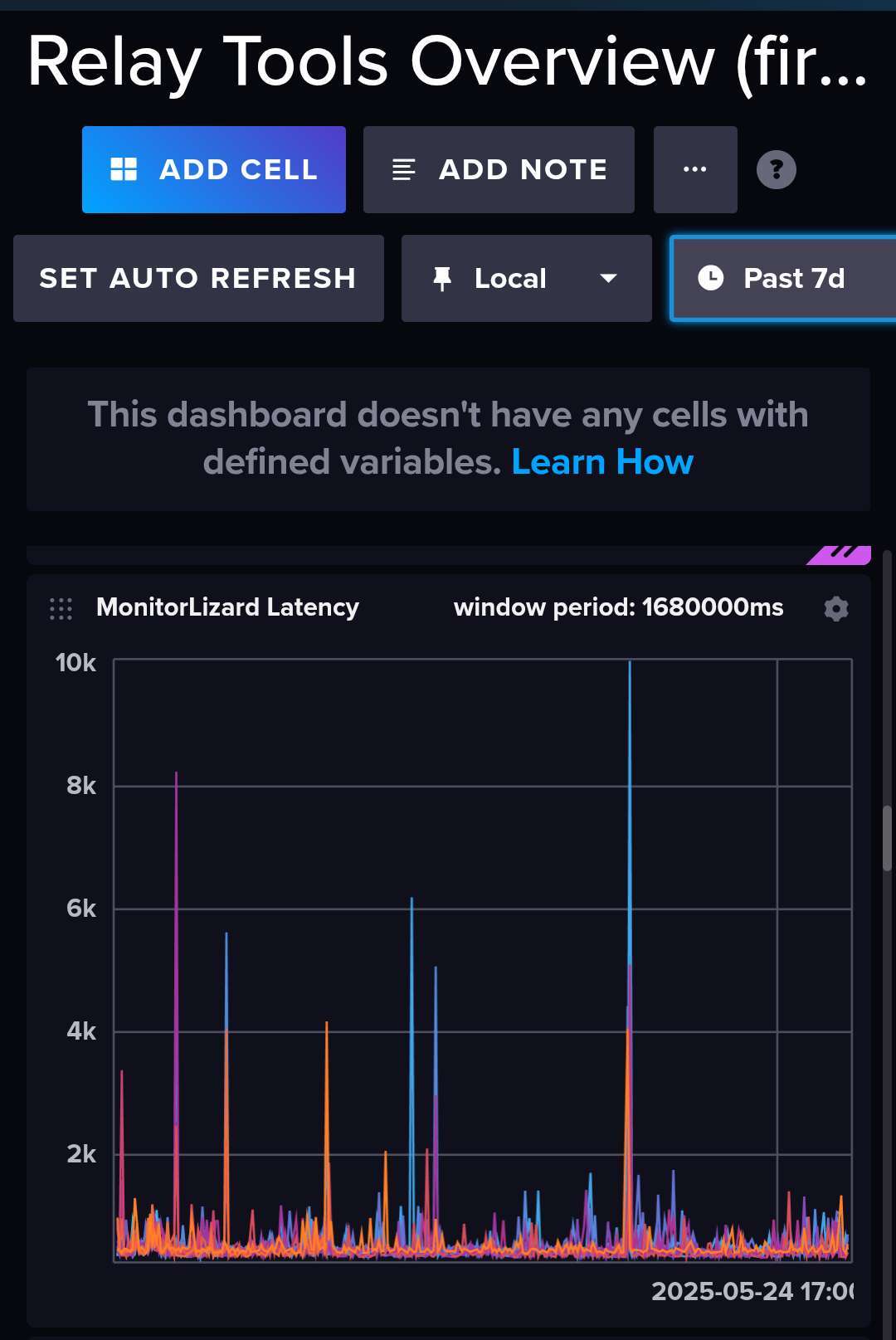
for a stress test of relay software itself you usually have to be running it on the same hardware configuration. maybe we can work together on benchmarking somehow though anyway, everybody loves benchmarks
Thread collapsed
Thread collapsed
Thread collapsed
Thread collapsed
Thread collapsed
Yeah so 8k open connections, not 8k in use fair enough. Yeah my concern is we need way more than a single instance and (I hope) way more than 8k active connections to support a product like Alexandria assuming we get anywhere close the reach were aiming for. I just want the software to exist for the time we DO need it. Like I said in my argument before. In just about any other software deployment, the software exists to scale, if needed, but not implemented _until_ needed. What happens when we do need it, and it doesn't exist?
Beyond that my concern, and I made this number up, something like a latency log scale showing some sort of "rolloff" - when load gets high enough to cause latency to creep to the point the service becomes interrupted or noticeable to the end user.
alexandria would be a read heavy load, books read and commented vs. uploading of the books
almost exclusively. The relay doesn't have to be a relay, kind if just needs a database (or files tbh) and some good caching.
http api like the one i made
badger has a good read cache on it as well, and it's designed to split the read/write load mainly in favor of writing indexes because events don't change, also, scanning the key tables is fast because it's not interspersed with value read/write
Thread collapsed
Thread collapsed
Thread collapsed
Thread collapsed




