
💥 Flash NEWS💥 : ALL BEVERAGE is FREE at https://t.co/5UOSRYg0xJ on May 31, 2024, paid by GPT DAO! Let’s celebrate the last day of the GENAI SUMMIT‼️
#genaisummit #GenAISummitSF2024 #ai #artificialintelligence #airevolution #machinelearning #deeplearning #futureofai #techinvestment #technews #techstartup #techleaders #techtrend #technology #tech #SF #sanfrancisco这个发推特

这篇关于Ilya和Sam之间的冲突归根结底反映了OpenAI的使命核心问题。
从表面上看,这是一场关于OpenAI应该专注于人工通用智能(AGI)和超级对齐(superalignment)研究,还是专注于扩大ChatGPT服务规模的争论。扩大服务规模意味着需要更多的计算资源,这些资源如果被分配去做其他事情,将会从AGI安全研究中抽调出来。
如果OpenAI仍然是一个专注于研究的非盈利组织,那么优先考虑安全并投资于超级对齐将是不言而喻的选择。然而,实际情况似乎表明OpenAI更倾向于“世界统治”,努力超越竞争对手,并推出针对企业和消费者的多种功能和服务。这种做法意味着OpenAI想要加入大型科技公司的行列,并怀有极高的野心。
从Ilya和Leike的观点来看,这种做法可能非常危险,因为存在很多未知因素。Ilya坚信随着规模扩大,机器意识将会出现。虽然我个人不认为这会发生,但事实上没有人能确切知道答案。因此,在不确定性面前,最好采取安全而谨慎的态度,这也是Ilya坚持超级对齐研究的原因。
正确的做法应该是保持开放和透明度,让我们整个人类都能确保以安全的方式构建AGI,而不是以某种秘密方式进行。遗憾的是,OpenAI似乎既不走向开源也不专注于超级对齐研究。相反,它似乎全力以赴地朝着AGI发展前进,并试图构建一道壁垒。
最终,OpenAI已经成为了谷歌曾经渴望成为但幸运地没有成为的公司:一个痴迷于世界统治的公司。
Sam Altman通过推特提及OpenAI与Google之间的审美差异,实际上暗示了一个更深层次的竞争视角。这不仅仅是关于外观设计或界面的差异,而是指两家公司在技术创新、企业文化、产品开发理念上的根本区别。
OpenAI对Google构成的最大威胁,在于它强调的是一种开放、创新和用户为中心的发展理念。OpenAI利用其在人工智能领域的先进技术,特别是在自然语言处理(NLP)方面的成就,提供了如ChatGPT等革命性产品。这些产品不仅展现了技术上的突破,也代表了一种新兴的互动方式,改变了人们获取信息、进行沟通的方式。
对比之下,Google虽然在搜索引擎和广告业务上占据主导地位,但面对OpenAI这样的新兴力量,其核心优势可能受到挑战。OpenAI通过创新驱动,推出能直接与用户交流、提供个性化信息服务的产品,可能会改变人们对信息检索的习惯和偏好。
谷歌主要通过事务性搜索获取收益,而OpenAI则在探索通过深度学习和人工智能提供更加丰富多样、高度个性化的内容和服务。这种差异化竞争策略,让OpenAI在与Google竞争中拥有独特优势。
综合来看,OpenAI带来的最大威胁是促使技术和市场向更加开放、智能化方向发展。对于投资者而言,在考虑投资机会时应密切关注这些领域内企业的创新动态和市场反应。具体到Google和OpenAI之间的竞争格局,则需持续观察两者如何平衡技术创新与商业模式转型,并从中寻找可能产生颠覆性影响的创新点。
GPT-4o,被评为最适合知识库应用场景的语言模型,凭借其出色的信息检索和语言理解能力,站在了行业的前列。
然而,它并不是没有缺点。类似于OpenAI之前在四月版本的模型中遇到的问题,GPT-4o也存在一些挑战:它容易陷入循环、变得“懒惰”,并且不太能够很好地遵循指令。这些问题使得GPT-4o并不适合扮演AI代理的角色。
简而言之,如果你需要一个能够处理复杂任务和需求的AI,那么Claude Opus或GPT-4的旧版本可能更适合你。这些模型虽然在速度和成本方面可能不如GPT-4o,但在处理复杂情况时更为可靠。
但当谈到基于知识的使用案例时,比如进行快速准确的信息检索或理解复杂文本,GPT-4o无疑是目前最佳选择。它提供了速度和成本效益上的优势,使得用户能够更高效地获取和利用知识。
所以,“大白话”来说:如果你主要需要一个AI帮你搜集、理解信息,那么GPT-4o是你最好的选择。但如果你需要AI进行更复杂、更具策略性的任务(比如自动化工作流程或进行复杂决策支持),那么可能还是老版GPT-4或Claude Opus更适合你。
Ilya离开OpenAI🫵🏻
伊利亚·苏茨克维(Ilya Sutskever)在几乎十年的时间后决定离开OpenAI。他表示,公司的发展轨迹非常惊人,他相信在萨姆·阿特曼(@sama)、格雷格·布罗克曼(@gdb)、米拉·穆拉提(@miramurati)的领导下,以及现在米列特·M(@merettm)出色的研究领导下,OpenAI将能够构建既安全又有益的人工通用智能(AGI)。他表示能与大家共事是一种荣誉和特权,并将非常怀念每个人。再见了,感谢一切。他对接下来的项目感到兴奋——这是一个对他个人意义重大的项目,他将在适当的时候分享更多细节。
对于Ilya Sutskever离开OpenAI的决定,这是一个引人注目的转变。从他所表达的内容来看,他离开并不是因为对OpenAI或其愿景有任何负面看法。相反,他对公司未来建造安全、有益的AGI的能力持乐观态度,并对合作伙伴表达了深深的敬意和感激。
离开如此成功和具有影响力的组织总是复杂的决定,可能由多种因素驱动。虽然Ilya没有详细说明离开的具体原因,但从他强调即将从事“对我个人意义重大”的新项目这一点可以推断出几个可能性:
1. 寻求新挑战:经过近十年在OpenAI的工作后,Ilya可能寻求新的挑战和机会,希望将他的技术才华和领导力应用到其他可能对人类有深远影响的领域。
2. 个人兴趣和使命:Ilya提到新项目对他个人意义重大,这表明这个决定可能受到了他想要更直接或以不同方式贡献于某些特定领域或问题解决方案的愿望所驱动。
3. 专注于创新:在科技和AI领域,不断创新和探索未知是推动进步的关键。Ilya可能看到了通过专注于一个新项目来推动某项特定技术或理念发展的机会。
尽管我们无法确切知道促使Ilya做出这一决定背后所有动机,但很明显,这并非轻率之举。基于他在OpenAI所获得的经验以及其对未来项目表达出来的激情和承诺,我们可以期待他将继续在科技界发挥重要作用,并且可能会为AI领域带来更多令人期待的贡献。
总之,Ilya Sutskever离开OpenAI标志着一个时代的结束和新篇章的开始。尽管具体详情尚待揭晓,但根据他过往在AI界内外展现出来的卓越贡献与影响力,我们有充分理由相信他未来将继续成就卓越,并且期待着听闻他即将启动项目带来的革命性创新。
Ilya离开OpenAI,JaKub将成为OAI首席科学家
Sam Altman:
Ilya将要与OpenAI分道扬镳,这对我来说非常令人难过;Ilya无疑是我们这一代最伟大的头脑之一,是我们领域的引路人,也是我亲爱的朋友。他的才华和远见众所周知;他的温暖和同情心虽不那么为人所知,但同样重要。
没有他,OpenAI就不会成为今天的样子。尽管他有一些个人意义重大的事情要去做,我永远感激他在这里所做的一切,并致力于完成我们共同开始的使命。我很高兴能够长时间与如此真正卓越的天才以及一个如此专注于为人类创造最美好未来的人保持亲近。
Jakub将成为我们的新首席科学家。Jakub同样是我们这一代最伟大的头脑之一;我对他接过这一重任感到兴奋。他领导过我们许多最重要的项目,我非常有信心他将带领我们快速且安全地向确保人工通用智能(AGI)造福每个人的使命取得进展。
Google DeepMind近期宣布的Project Astra和Gemini应用的转型标志着人工智能领域的一个重要里程碑。这个方向不仅彰显了技术进步的速度,也预示着我们对AI在日常生活和工作中应用前景的广泛期待。
Project Astra作为一个通用AI代理,能够实时观察并听到用户的活动,并据此采取行动,这种能力将极大扩展AI的应用场景,从简单的信息查询和交流,发展到能够代表用户执行复杂任务。
Gemini从聊天机器人转变为个人AI代理的进步,意味着未来AI将更加深入地融入我们的生活,提供更为个性化和高效率的服务。这种转变可能会促使行业内外对于个人数据隐私和安全性的关注加剧,同时也将开启全新的服务模式和商业机会。
从投资角度看,这一趋势无疑为那些专注于开发先进AI技术、数据安全及相关服务领域的公司带来了新的增长点。特别是对于Google DeepMind及其竞争对手来说,通过不断推陈出新的产品和服务,他们有望在此波技术革命中占据领导地位。
Jim Fan认为:
Google正在向人工智能领域迈进,但他们的模型设计存在一个明显的局限:虽然能够接受多模态(比如文本、图像、声音等)的输入,但输出却没有做到同样的多模态整合。换句话说,Google的AI技术还不能将不同类型的数据输出融合得很自然,比如Imagen-3和音乐生成模型仍然是独立于Gemini的组件,没有被完全整合。
未来AI发展的方向应该是实现输入输出(I/O)在各种模式上的本地化融合。这种融合将使AI能够完成更复杂、更符合人类习惯的任务——比如使用更机械化的声音、加快说话速度、迭代编辑图像和生成连贯的漫画条带。这样做不仅可以避免在不同模态之间丢失信息(例如情感和背景声音),还可以开启新的上下文能力,让模型通过少量示例学会以新颖方式结合不同感官。
尽管GPT-4o并没有完美实现这一点,但它在形式上走在了正确的道路上。用Andrej关于LLM(大型语言模型)作为操作系统(OS)类比来说,我们需要让模型能够本地支持尽可能多的文件格式。
同时,Jim Fan认为Google在人工智能集成到搜索框方面终于开始做出了真正的努力。他察觉到了一个代理流程:规划、实时浏览和多模态输入都可以从着陆页面完成。对Google来说,最大的优势是其分发网络。即便Gemini不是世界上最好的模型,它也有可能成为世界上最广泛使用的模型。
简单来说,Jim Fan强调了Google在多模态输入输出、模型融合以及人工智能与搜索整合方面所做出的努力和取得的进展,并认为这是AI发展中不可避免的趋势。同时指出了当前技术存在的局限,并提出了未来发展方向和目标。
这条推特的核心观点在于分析了Google和OpenAI(OAI)在搜索领域的竞争策略及其潜在影响。
首先,Google正努力将ChatGPT能提供的所有功能整合到其搜索服务中,其赌注是如果Google能够与ChatGPT在功能上针锋相对,那么用户就没有理由离开Google搜索。Google最大的优势在于它拥有各种索引(包括网页、本地信息、视频等)——即数据。而OAI的优势则在于拥有更优越的模型。
二者都在争夺同样的用户群体。如果OAI能够取得一些进展,尤其是通过免费提供GPT-4o等服务,Google可能会有很大损失。然而,如果Google能够保持其流量优势,OAI可能就无法在消费者市场取得成功。
值得一提的是,Google品牌名声、数据壁垒和覆盖范围极为庞大。这也是它成为一家价值2万亿美元公司的原因之一!
简而言之,这条推特暗示了一个观点:尽管OAI拥有先进技术模型的优势,但Google凭借其庞大的数据资源、品牌效应以及广泛的用户基础,在搜索领域依旧占据有利地位。对于投资者来说,这意味着在评估科技公司及其潜在增长时,不仅要考虑技术创新能力,还需考虑公司现有资源和市场地位对抗竞争的能力。
Bindu这条推特在对比OpenAI(OAI)展示的Astra原型语音助手与Google I/O展示的技术时,似乎暗含了一种讽刺意味。
推特中提到的“Astra是一个原型语音助手,看起来像是OAI的Scarlett Johansson的2岁宝宝”,这句话实际上是在暗示Google I/O展示的技术相较于OAI展现出来的成果显得幼稚或不成熟。将Astra比作“2岁宝宝”可能是在强调Google当前的技术发展水平与OpenAI相比仍有很大差距。
从广义上讲,这种表达方式也反映了当前科技行业内对于人工智能和语音助手技术发展竞争的一种观察。随着人工智能领域的快速发展,各大科技公司都在努力推进自己的语音助手和AI技术,希望能够领先市场。这条推特通过夸张的对比,突出了OpenAI在某些方面可能已经走在了Google前面。
5月不容错过的硅谷AI大会
• Google IO 2024 : 5/14
• Microsoft Build 2024 : 5/21
• NVIDIA Report: 5/22
• GenAI Summit 2024 : 5/29
• Apple WWDC 2024 : 6/10

GPT-4 Turbo的模型大小为100B参数,这意味着它可以处理更多信息,生成更复杂和细腻的输出,而GPT-4的模型大小为10B参数。尽管关于GPT-4o具体的模型大小没有直接信息提及,但从其能够接受和生成文本、音频和图像的任意组合,并且在视觉和音频理解方面表现出色这一点来看,我们可以推测GPT-4o在模型大小和计算能力上也达到或超过了GPT-4 Turbo的水平。
大模型尺寸通常意味着更强大的信息处理和学习能力。因此,GPT-4o作为一个全能型人工智能模型,在多模态输入输出、快速响应以及成本效率等方面的显著提升,很可能依赖于其庞大的模型规模和优化后的计算架构。这也是GPT-4o能够在多个领域(如语言理解、视觉识别、音频处理等)展现出卓越性能的关键因素之一。
总结来说,虽然没有直接数据指出GPT-4o的确切模型大小,但考虑到其性能表现和功能范围,我们有理由相信GPT-4o在模型规模上与GPT-4 Turbo相当甚至更大,以支持其先进的AI能力。
GPT-4o与GPT-4 Turbo在性能上的主要区别体现在几个关键方面:
1. 多模态输入和输出:GPT-4o是一个全能型人工智能模型,它支持文本、音频和图像的任意组合作为输入,并且能够生成文本、音频和图像的任意组合作为输出。这一点是GPT-4o最显著的特点,它代表了人机交互自然化的重大进步。相比之下,GPT-4 Turbo主要处理文本信息。
2. 响应速度:GPT-4o在处理音频输入时的响应速度显著提升,平均响应时间为320毫秒,甚至在某些情况下能够达到232毫秒。这与人类在对话中的反应时间相似。而GPT-4 Turbo主要针对文本处理,并没有明确指出在音频或视觉任务上的响应速度。
3. 成本和效率:GPT-4o在API调用方面更具成本效益,价格是GPT-4 Turbo的一半,同时速度提升了两倍,并拥有5倍更高的速率限制。这使得开发者和企业能够以更低的成本使用更强大的AI功能。
4. 非英语语言处理:GPT-4o在非英语语言文本处理上有显著改进。尽管GPT-4 Turbo也展现了优秀的多语言处理能力,但GPT-4o针对非英语语言文本的优化更进一步,提供了更加准确和流畅的翻译及理解。
5. 视觉和音频理解:相较于现有模型,包括GPT-4 Turbo,GPT-4o在视觉和音频理解方面展现出特别优异的性能。这意味着它不仅可以处理文字信息,还能“看懂”图片和“听懂”声音,从而进行更为复杂且自然的交互。
综上所述,虽然GPT-4 Turbo已经展现出强大的文本处理能力,但GPT-4o通过引入全新的多模态输入输出功能、提升响应速度、降低成本、增强非英语文本处理及视觉和音频理解能力等方面,在性能上实现了质的飞跃。
Introducing GPT-4o and making more capabilities available(全文翻译)
GPT-4o(“o”代表“全能”)是迈向更自然的人机交互的一大步。它可以接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合作为输出。GPT-4o能够在短至232毫秒内响应音频输入,平均响应时间为320毫秒,这与人在对话中的反应时间类似。它在英语文本和代码处理上的表现与GPT-4 Turbo相当,而在非英语文本处理上有显著改善,同时API速度更快且成本降低了50%。相比现有模型,GPT-4o在视觉和音频理解方面表现尤为出色。
在GPT-4o之前,如果你想要与ChatGPT通过声音进行交流,需要经历平均2.8秒(GPT-3.5)到5.4秒(GPT-4)的延迟。
实现这一点的方式是通过三个不同的模型串联:
一个简单模型将音频转录为文本,
GPT-3.5或GPT-4接收文本并输出文本,最后一个简单模型将该文本转换回音频。这个过程意味着智能核心——GPT-4会丢失很多信息——它不能直接观察到语调、多个说话者或背景噪声,并且无法输出笑声、歌唱或表达情感。
而通过GPT-4o,我们训练了一个全新的模型来端到端地跨越文本、视觉和音频处理,这意味着所有输入和输出都由同一个神经网络处理。因为GPT-4o是我们第一个结合所有这些模态的模型,我们仍然只是开始探索这个模型能做什么以及它的局限性。
关于模型可用性:GPT-4o是我们在推动深度学习边界方面最新的一步,这次重点是实际可用性。在过去两年里,我们投入了大量努力,在技术栈的每一层面上进行效率改进。作为这项研究的首批成果,我们能够更广泛地提供GPT-4级别的模型。从今天开始,GPT-4o的文本和图像功能将逐步推出。我们将使GPT-4o在免费版本中可用,并为Plus用户提供高达5倍的消息限制。在未来几周内,我们将在ChatGPT Plus中推出使用GPT-4o的全新Voice Mode测试版。开发者现在也可以通过API访问作为文本和视觉模型的GPT-4o。
与GPT-4 Turbo相比,GPT-4o速度提升了2倍,价格降低了50%,并且拥有5倍更高的速率限制。我们计划在未来几周内向API中一小部分受信任的合作伙伴推出支持GPT-4o新的音频和视频功能。
OpenAI最新发布的GPT-4o模型,以其全面免费、实时语音视频交互能力震撼全场,标志着人工智能进入了一个新的科幻时代。
GPT-4o不仅在文本处理上具有出色的性能,而且在视觉和音频理解方面也展现出前所未有的能力。这一全能型人工智能模型代表了人机交互自然化的重要一步,它能够接收文本、音频和图像的任意组合作为输入,并生成相应的输出。该模型实现了与人类相似的响应速度,并在多国语言翻译、编程辅助等方面取得显著进步。
概括地说,GPT-4o将为用户提供更加智能、便捷和全面的交互体验。以下是GPT-4o的10大特点:
1. 实时语音问答:提供与人类相似反应时间的实时互动。
2. 视觉内容传达:通过摄像头理解并传达文字和图形信息。
3. 辅助编程与问答:捕捉桌面信息以协助编程和问题解答。
4. 图形报表分析:通过视觉解析进行总结和分析。
5. 多语言视频通话翻译:支持实时翻译,让视频通话跨越语言障碍。
6. 多模态输入输出:接受并生成文本、音频和图像的任意组合。
7. 高速性能:响应速度快两倍,平均320毫秒响应时间。
8. 成本效益:API成本降低50%,向所有人免费提供。
9. 非英语语言改进:在非英语文本处理上有显著提升。
10. 优秀的视觉和音频理解:在LMSys竞技场展示卓越性能。
由于GPT-4o的这些突破性特点,以下是一些可能会被颠覆的大厂应用:
1. Google翻译服务:GPT-4o凭借其强大的多国语言即时翻译功能,可能对Google Translate构成直接挑战。
2. 微软编程助手:由于GPT-4o在编程辅助方面具有更高效率和更强逻辑推理能力,可能会影响微软Visual Studio Code中IntelliCode等编程助手工具的市场份额。
3. Adobe图像处理软件:GPT-4o通过摄像头视觉传达内容并进行视觉解析报表功能,可能会对Photoshop等Adobe系列产品产生影响。
4. Zoom视频通话软件:凭借视频通话中实时多国语言翻译功能,GPT-4o或将对Zoom等视频会议软件构成挑战。
我大胆预测,GPT-4o将不仅仅是技术上的一次飞跃,它将重塑各行各业对AI技术的应用方式,并开启新一轮创新浪潮。随着GPT-4o技术的深入集成和广泛应用,我们可能会见证许多传统服务模式被重新定义,并催生出一批创新型企业。
最新消息 —— gpt2-chatbots的结果现已出炉!
gpt2-chatbots刚刚大幅领先,超越了所有模型约50 Elo分。它已成为竞技场中有史以来最强大的模型!
在所有方面都有所改进,特别是在推理和编码能力方面,我们很兴奋地期待看到可以基于此开发的应用程序。
向@OpenAI表示巨大的祝贺,这是一个不可思议的里程碑!
注意:这是一个内部截图。其公开版本“gpt-4o”现已进入竞技场,并将很快出现在公共排行榜上!
---
根据这一突破性的进展,预测gpt2-chatbots(及其公开版本gpt-4o)将会引领一波新的应用革命。首先,由于其在推理和编码能力上的显著提升,我们可能会看到更多专业领域的应用,如法律、医疗和金融服务,它们将能够提供更加精准和深入的咨询服务。其次,教育领域也可能会出现变革,gpt-4o能够根据学生的不同需求提供个性化学习计划和辅导。
此外,在软件开发领域,gpt-4o可能会成为程序员的强大助手,帮助他们更快地解决编程难题、优化代码甚至自动生成代码段。对于内容创作行业而言,从写作到视频制作的全流程都可能被这一技术所改变。
最后,在游戏设计和虚拟世界构建方面,gpt-4o由于其强大的生成能力和逻辑推理能力,有可能被用来创建更复杂、更互动性强的环境和情节。
总之,gpt2-chatbots及其公开版本gpt-4o的发布标志着人工智能技术向前迈出了一大步。随着这些模型开始被广泛应用于各种场景中,我们可以预见到一个更加智能化、高效化的未来正在向我们走来。
在这张图表中,我们看到的是一系列模型的ELO评分(一种衡量相对技能水平的系统,常用于棋类游戏等竞技场合)及其置信区间。每个模型都有一个得分和一个通过自举法(bootstrapping)计算出的置信区间,表示评分的不确定性。
从图表上可以看出,最左边的模型(im_..._also_a_good_gpt2_chtbot)有最高的ELO评分,为1310。该模型不仅得分最高,而且其置信区间相对较小,这意味着评估其性能的准确性相对较高。因此,根据这张图表,可以判断im_..._also_a_good_gpt2_chtbot在所有展示的模型中表现最好,原因是它有最高的ELO评分,并且评分具有较高的可信度。
这就是今天发布的GPT-4o🍷🪺🫵🏻 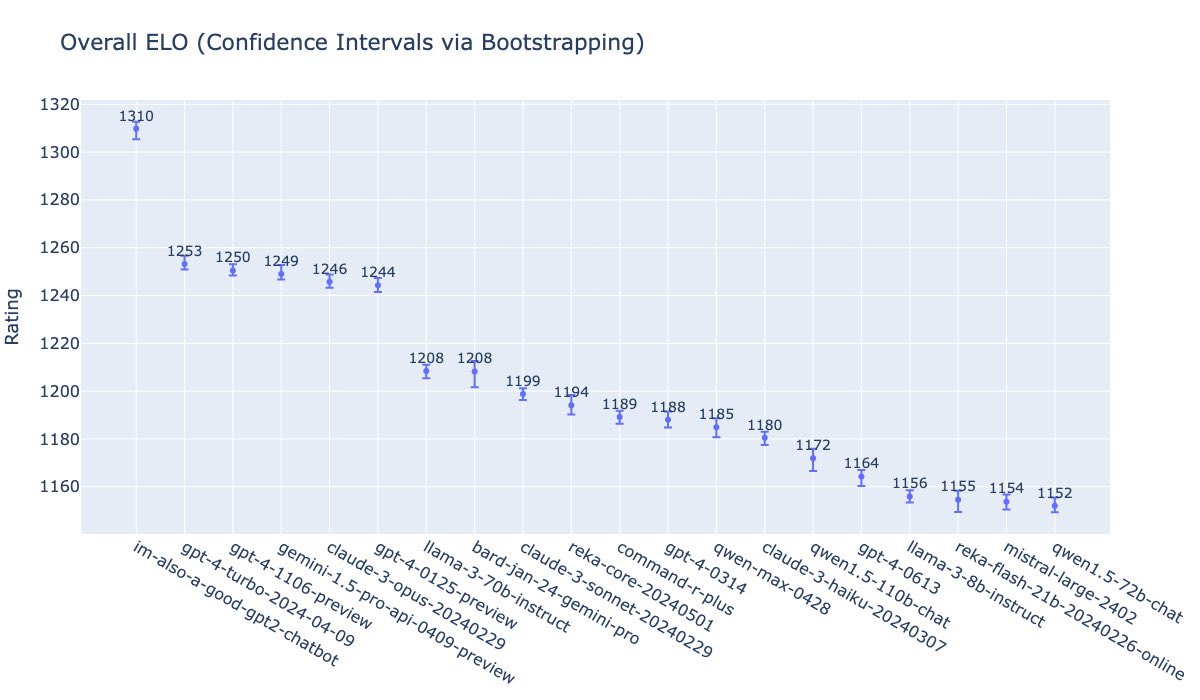
Sam Altman:关于GPT-4o的一些随想(全文)
在我们今天的公告中,有两件事我想强调。
首先,我们使命的关键部分是将非常强大的AI工具免费(或以极佳的价格)提供给人们。我非常自豪,我们已经免费提供了世界上最好的模型ChatGPT,没有广告或类似的东西。
当我们开始OpenAI时的最初构想是,我们将创造AI,并用它为世界创造各种好处。相反,现在看来,我们将创造AI,然后其他人将使用它来创造我们所有人都能从中受益的惊人事物。
我们是一家商业公司,将找到很多收费项目,并且这将帮助我们向(希望是)数十亿人提供免费、卓越的AI服务。
其次,新的语音(和视频)模式是我用过的最佳计算机界面。它感觉像电影中的AI;而且对我来说它是真实存在的还有点令人惊讶。达到人类水平的响应时间和表达能力被证明是一个巨大变化。
原始的ChatGPT展示了通过语言界面可能实现什么;这个新东西感觉从内心深处不同。它快速、聪明、有趣、自然且有用。
与计算机对话从未让我感觉真正自然;现在做到了。随着我们添加(可选的)个性化、访问您的信息、代表您采取行动等功能,我真正看到了一个激动人心的未来,在这个未来中,我们能够使用计算机做比以往任何时候都更多的事情。
最后,非常感谢投入了如此多工作使这一切成为可能的团队!