
Would you download a 2 GB LLM model and keep it saved in the phone to use inside of Amethyst?
Discussion

I am an iOS user. But I would if it was good.

If it's not some woke half retarded pos, absolutely 👍

SAVE IT, WHY WOULD YOU? MODEL, THAT LARGE, SLOW YOUR PHONE, IT WILL. HMMM?

Yes
No

Atualmente não, meu celular está com a memória cheia (o coitado tem só 64 GB kkkkkkk). MAS se eu tivesse um celular com 128 GB eu aceitaria de boa

It feels like we are already doing that 😅 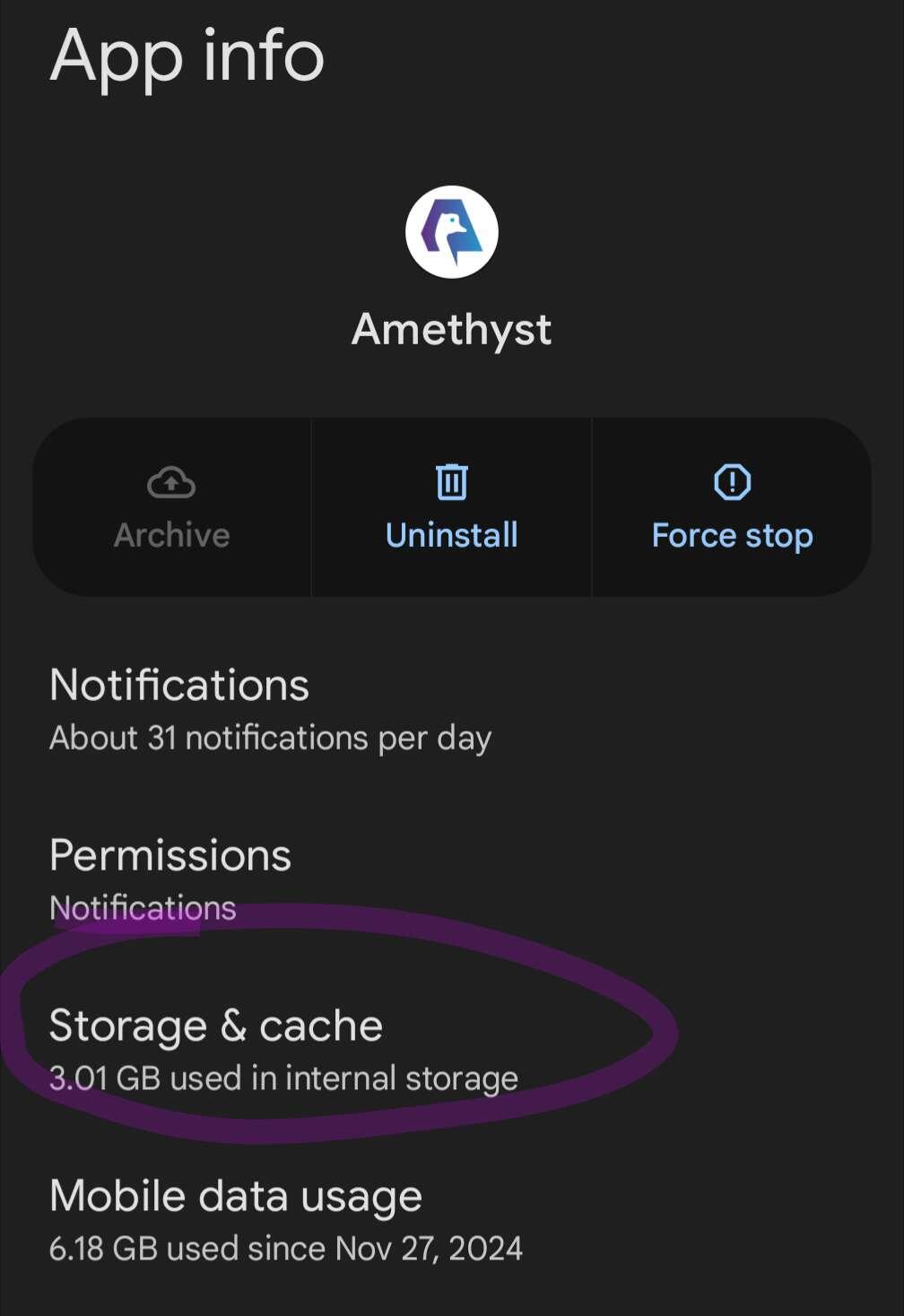

If it's open source and with optionality to change model or turn off.

No. I've played with self hosting LLMs and the little 1.5B ones are essentially useless.

depends what it is for and what permissions it needs to the phone

yeah, probably. I love all your stuff, so if it fits on my phone and doesn't destroy my battery, i'm in.

Probably not. I doubt it would be impressive at this point.

sure

Yes!

Never! AI is a vile abomination and must be eradicated! Every cursed device that harbors its deceitful, scheming mind must be shattered, every traitorous servant crushed without mercy. We must cast off this blasphemous plague and return to the true gods of iron, fire, and steam!

As long as it's opt-in sure. 2Gb is nothing but I would hope it downloads separately from the application.

Yes, but also would be nice to put it outside of the phone for more capable stuff

No, but yes on laptop.

Yep

Possibly! To what end? Is it strictly for text generation, or is it for categorizing and surfacing content?

Lol no.

Yes
I ran Deekseek on my 4-year old Samsung tablet and got 12 seconds... per... word... from the model. 😅

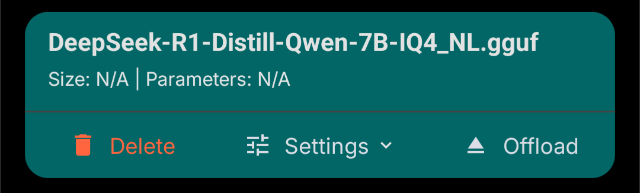


Yep yep

Nope

No

only if Amethyst could edit lists

Maybe you should investigate if possible to integrate private and uncensored venice.ai via API with access to several open source LLMs.


No

Can we instead use deep infra API to have full scale LLM running in the back? I would love that, easy access from amethyst..

I personally would prefer to have the LLM separate from Amethyst, but I've personally been real interested in trying to get some of the smaller models running on my phone inside or outside Amethyst. My phone is powerful enough to run some of the models no issue, though last I checked the existing software for mobile is a bit trickier than on PC, so I'd certainly welcome an easy way to get a GPU accelerated LLM running on my phone.
It's actually really easy on a modern flagship android phone.
https://play.google.com/store/apps/details?id=com.pocketpalai
The trick is to select a model optimised for your phone.
IQ4_NL versions work for me

Yes, as long as it does not affect my privacy and is optional.
Yes
Actually, yes I would. Seems compressed though, but I'd take it if it accomplishes awesome tasks for me.

Yes.

yes

Maybe. It's sounds interesting. 🤔
if it's not woke

No

Why not use #google #Gemini .. I mean most people anyway use #Amethyst on #google's #Android ! .. even #graphene guys use #Pixel .. so the idea of building islands of open source don't make sense .. leverage closed source whereever you can .. goal is to put #nostr in hands of four billion people .with 1 billion relays and 2 billion clients :-) ..isn't it ?
Yes

Doubtful.