nostr-filter の ブロックIPアドレスリストも環境変数で指定できるように見直したよ。
https://github.com/imksoo/nostr-filter/commit/a813ac7deb979d8a4b3e519d9e0e093f4aac27c9

Thank you imksoo-san (Kirino-san), seems i need to rebase later 😅

We're not in the targeted or prominent list. Probably 😅
Sasuga Aizen-sama 😄
Did you watch Bleach, Samuel?
You can request and DM this bot account nostr:npub1cc79kn3phxc7c6mn45zynf4gtz0khkz59j4anew7dtj8fv50aqrqlth2hf
It is made by nostr:npub1nxa4tywfz9nqp7z9zp7nr7d4nchhclsf58lcqt5y782rmf2hefjquaa6q8

1 GB at least translation data. So if we clear cache it will come back to 1GB. Translation data cannot be cleared 😅
nsec1kmzwa8awaa
I've created benchmark tool named xk6-nostr.
https://bolt.fun/project/xk6-nostr
You can see a peformance comparison of relays at this demo video:
Thank you kamakura-san 👋
Not corrupt politicians? 👀😅
We have a lot here in Indonesia. KPK (Commision of Corruption Fight, Law Enforcement in Corruption crimes) have various records from low level to high level official corrupt politicians.
Big homeworks for nostr devs (relay, client) and relay operators 😅
Primal can effectively achieve good results using their effective cache. Other clients need to handle better cache locally at least.
I think nostr:npub1f5uuywemqwlejj2d7he6zjw8jz9wr0r5z6q8lhttxj333ph24cjsymjmug - san (Japanese dev) has already done some performance benchmark using various relays in #nostrasia hackaton.
nostr:npub1f5uuywemqwlejj2d7he6zjw8jz9wr0r5z6q8lhttxj333ph24cjsymjmug - san, where we can read your reports about relay performance? Is it in your github? Sorry, i may missing that 😅
I think regular web can already handle partially of that requests (1 million req/s)
https://www.techempower.com/benchmarks/#section=data-r22&test=json&hw=ph
It just we need more load balancer server with horizontal and vertical scaling applied. The most bottleneck part is probably verifying schnorr signatures multiple times for all events incoming.
Relay developers have such a big homework to achieve that. They also need to optimize many things.
I wonder, have you done some performance benchmark using various relay implementation? At least, how many ops/s relay can process (read-only, write-only, and both operations)? How many ops/s that we can finally say "it is scalable"?
I think at least that can be the start of discussion
What ML models that you are using for that, mattn-san? I've tried "detoxify" library with "unbiased-small" model gives good results
Maybe you can try wss://nostr-id-relay.hf.space
It is designed as special family-friendly relay for global feed. Half of the planned features already implemented. 😅
There are various usage examples on how to use the relays in Github:
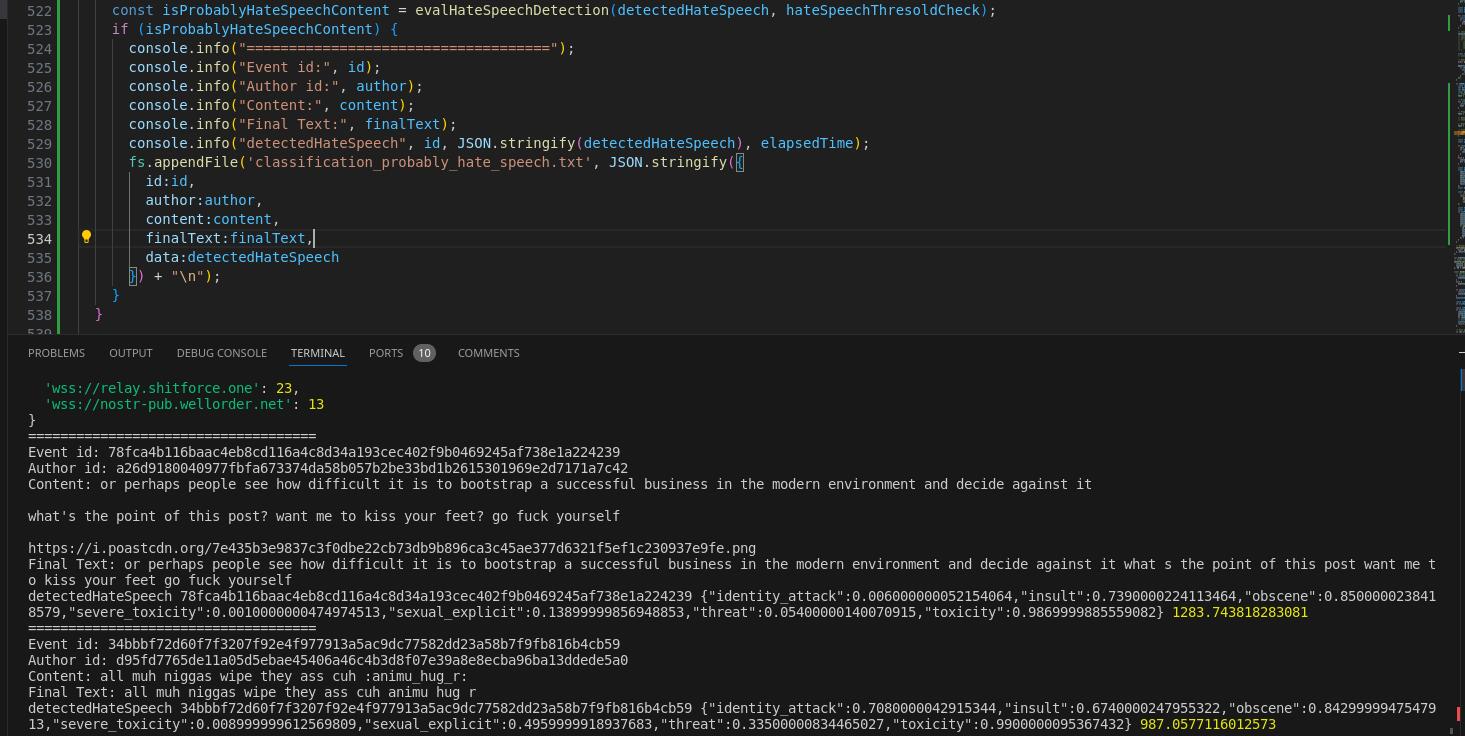
Early working code (PoC) for Hate speech (Toxic content) detection
https://github.com/atrifat/hate-speech-detector-api
This API server will be included as part of dependency for nostr-filter-relay.
#machinelearning #deeplearning
You can use https://nak.nostr.com and paste nprofile, nevent, or other supported encoding into that. It will decode them properly.
Thank you. Yes, it helps. I take the water every 15 or 30 minutes to stay hydrated and stay focus. Usually before or after lunch, i need to go to the restroom as the result. 😅
Have you ever got some headache whenever working in a long time in front of PC/laptop? How did you manage to work for a long time in those condition?
I can barely stay for 3-4 hours in a day, before i got hit with headache.
#asknostr
Dear scraper from Hetzner Server (IP Censored). What do you need for 52 connections simultaneously opened? 😅
You can send multiple REQ subscribe in single connection actually to the relay. It will be more efficient. Thank you.
Reading manually, one by one, for thousands of data makes me remember how i've done my undergraduate theses "Comparison of Naive Bayes smoothing methods for Twitter Sentiment Analysis". It takes quite a toll and focus to finish that. 😅
So you mean like we shouldn’t have Tor relays in public? I think we need to build more relays for people like nostr:npub1sn0wdenkukak0d9dfczzeacvhkrgz92ak56egt7vdgzn8pv2wfqqhrjdv9 or Chinese people in an anti-censorship way.
Oh no, i did not say that. I am not sure if you read my previous comment using Japanese translation or not. Maybe there are some incorrect translation, kohei-san. 😅
What i mean is, "Relay softwares can accept TOR connection as long as Relay owner allow it. Usually, it will depends on relay owner."
Update:
There were 4358 sample data classified as potential toxic notes/posts from 75000+ total notes/posts within 24 hours, with minimum classification thresold score of 0.2.
I will take a look manually to see how the data behave. Hopefully, it won't 'poison' much to read them 😅
Congrats Vitor, wish you in the goodness. Thank you for your works. 🎉
It's fascinating that there are lightweight models that can achieve 'real time' or at least 'near real time' under 100ms.
One of those models is from detoxify (unbiased-small) which achieves evaluation score of 93.74 (Top Performer score: 94.73).
Let's see how the data will be formed after 24 hours 👀
WIP - Hate Speech detection
The difference between NIP-46 and how amber sign event is NIP-46 need signer to be 'online' while amber implementation is 'offline' signer right? I think based on that you can probably write new NIP.
> amber is android signer
I think this can be generalized. iOS probably can do similar things like amber uses android intents. Maybe there is similar mechanism. Probably need someone to make amber for iOS first though 😅
Today i learned that there are another contender to challenge the throne of Node.js modules as 'the heaviest object' in universe which are Python AI/ML dependencies.
You can try with:
pip install --no-cache-dir detoxify pandas Flask
and build docker image using those dependencies. 😅
Is there anyone know the tricks to solve that whenever you need to deploy and need those dependencies for your apps?
#asknostr #python #machinelearning
Hopefully, more Indonesian translator will participate. Also for other languages. 🙂
Btw, so you won't accept any translation PR anymore? Only accept translation via crowdin?

Yes, i think i will prefer this way since not every posts always stay in one language. It just needs good UI so it won't bother common users. They can manually or use auto detected language as default language value before posting. NIP-32 allows regular notes to embed 'l tag' to mark the language
Ideally, it needs to be implemented in some clients as part of their on-boarding process. Unfortunately, i think most clients even don't have clear/good on-boarding steps for new users. If user can pick their language preference (speak) correctly then we can use those with NIP-32 to include language tag in each notes. 😅
Thank you nym (and GPT/LLM if they were used) for the responses. We can see that it is really challenging to make a robust and complex Web of Trust in decentralized network. Such a big homework for relay operator and clients developer to solve all of the issue 😅
What are the best practices to handle languages on notes? Is this implemented on the protocol level or is it something a client should care of?
For example I'm wondering how I can filter notes and other events on just a specific language. Finding content in my native language is really hard at the moment.
I've found these related NIP proposals (I'm also a Mastodon user):
https://github.com/nostr-protocol/nips/pull/632
This seems somewhat more complicated and it's only the relay which can set the language for a specific event? I think it should be set by user / client and the relay feedback could be used as a fallback (but on the other hand: this makes relay smarter which have to kept as dumb as possible).
https://github.com/arthurfranca/nips/blob/nip-17/17.md#language
#askNostr #devNostr #NostrDev
We have to filter and classify on our own since no guideline probably to cover that 😅
Yes, nostr-filter comments come from upstream (imksoo/nostr-filter), haven't touch any of those yet. imksoo-san primarily makes this mainly for their Japanese relay at first. I can understand a bit based only on the code written 😂