一位由心理学家转行的计算机科学家刚刚因社会学原因获得了诺贝尔物理学奖
特斯拉Robotaxis:颠覆交通的未来革命!
Tesla的Robotaxis将对“交通运输”产生的影响,就像iPhone对“通信”所做的那样,彻底改变这一领域。传统的汽车拥有、出租车服务和共享出行服务的需求将不再存在。特斯拉正在全力以赴地推进自动驾驶技术,而那些不跟进的公司将面临生存危机。以下是我认为的关键原因:
安全性
特斯拉的Robotaxis将带来一种人类驾驶员无法比拟的安全水平。凭借先进的人工智能、传感器和来自数百万英里行驶的数据收集,该系统的反应速度将比任何人类驾驶员都要快且安全。想象一下,如果这种技术能够在那些因酒后驾驶而失去生命的人身上得到应用……这项技术将拯救生命。
无需司机
没有司机的存在将改变许多事情。无需支付工资、无需安排时间、无需担心人为错误。这些Robotaxis可以全天候运营,不受人力资源的限制。人类司机往往是瓶颈,而特斯拉的Robotaxis将消除这一需求。这意味着非停歇的高效出行,能够让我们从A点到B点,而无需依赖人力。
每英里最低成本
交通运输成本即将大幅降低。Robotaxis不需要司机、方向盘、踏板或刹车,并且使用电力驱动,电力的成本远低于汽油。公司将很难在每英里的成本上与特斯拉的Robotaxis竞争,使得出行更加实惠,成为客户的首选。
汽车拥有观念的改变
Robotaxis将从根本上改变人们对汽车拥有的看法。通过轻触按钮即可获得经济实惠的按需出行,许多人将开始质疑个人汽车拥有的必要性。无需再担心维护、保险、燃料/电力成本或停车问题——Robotaxis将处理所有这些事务。人们将获得时间、金钱和自由,消除拥有汽车的需求。
我理解埃隆·马斯克所说的,这将是一个价值5-7万亿美元的机会。 
掌控习惯的力量:解锁行为改变的终极秘诀!
James Clear的习惯环
1. 提示(Cue):
- 触发习惯的五种方式:时间、地点、前序事件、情绪状态、他人影响。
2. 渴望(Craving):
- 每个习惯背后的动机力量。例如,不是想锻炼,而是想在锻炼后感觉良好。
3. 反应(Response):
- 实际执行的习惯,可以是一个想法或行为。取决于动机和能力。
4. 奖励(Reward):
- 每个习惯的最终目标。短期为缓解渴望,长期为记住值得重复的行为。
建立更好习惯的6个心理模型
- 激活能量:小习惯更易建立,比如每天做10个俯卧撑而不是100个。
- 单纯曝光效应:做得越多,越容易。坚持6周再判断是否困难。
- 复利效应:好习惯的大成果可能需要数年才显现。相信过程。
- 两天规则:不追求完美,避免连续两天缺席。
- 部落主义:你的习惯会与周围人一致。选择明智!
- 进化论:天生倾向于节省能量和摄入食物。健康习惯需要努力实现。
通过理解和应用这些原则,你可以有效地建立和维持积极的生活习惯。 
致命蘑菇双煞:死亡天使与毒帽伞的恐怖真相!
毒蘑菇一:毁灭天使(Amanita virosa)
- 致命毒性:
- 毒性与毒帽伞相同,极其危险。
- 与多种落叶树和针叶树形成菌根关系。
- 生长季节为8月至11月。
- 识别特征:
- 菌盖通常倾斜,整体纯白色。
- 孢子印为白色。
- 茎基部有袋状菌幕(可能不明显或部分存在)。
- 易被误认为小型毛球。
毒蘑菇二:毒帽伞(Amanita phalloides)
- 致命毒性:
- 生长在落叶树下,尤其是橡树。
- 生长季节同样为8月至11月。
- 含有剧毒化合物α-鹅膏蕈碱。
- 导致欧洲90%的真菌中毒死亡事件。
- 识别特征:
- 黄橄榄色菌盖,可能带有白色鳞片,但常无鳞片。
- 孢子印为白色。
- 茎基部同样有袋状菌幕(可能不明显或部分存在)。
- 易被误认为小型毛球。
这些蘑菇不仅外形迷人,却藏有致命毒素,误食半个菌盖即可致命。警惕自然界的隐秘杀手! 
揭开语言Agent的秘密:认知架构全解析!
A部分:内部结构
1. 记忆系统:
- 程序性记忆:处理LLM(大型语言模型)和代理代码,用于执行特定任务。
- 语义记忆:存储知识和事实信息,支持信息检索和学习。
- 情景记忆:记录事件或经验,帮助智能体在特定情境中做出决策。
2. 工作记忆与推理:
- 集成了信息检索、学习和推理功能,以支持实时决策。
3. 决策过程:
- 根据输入(Prompt)解析和计划行动,进行对话、物理交互或数字操作。
B部分:外部交互
1. 观察与计划:
- 智能体通过观察环境,进行计划并提出行动方案。
2. 评估与选择:
- 对提案进行评估,选择最佳方案并执行。
行动空间
- 分为内部(推理、检索、学习)和外部(接地)的交互,协同实现智能体的规划和执行。
这种架构展示了语言智能体如何通过复杂的认知流程与环境进行交互,为实现高级人工智能提供了可能。 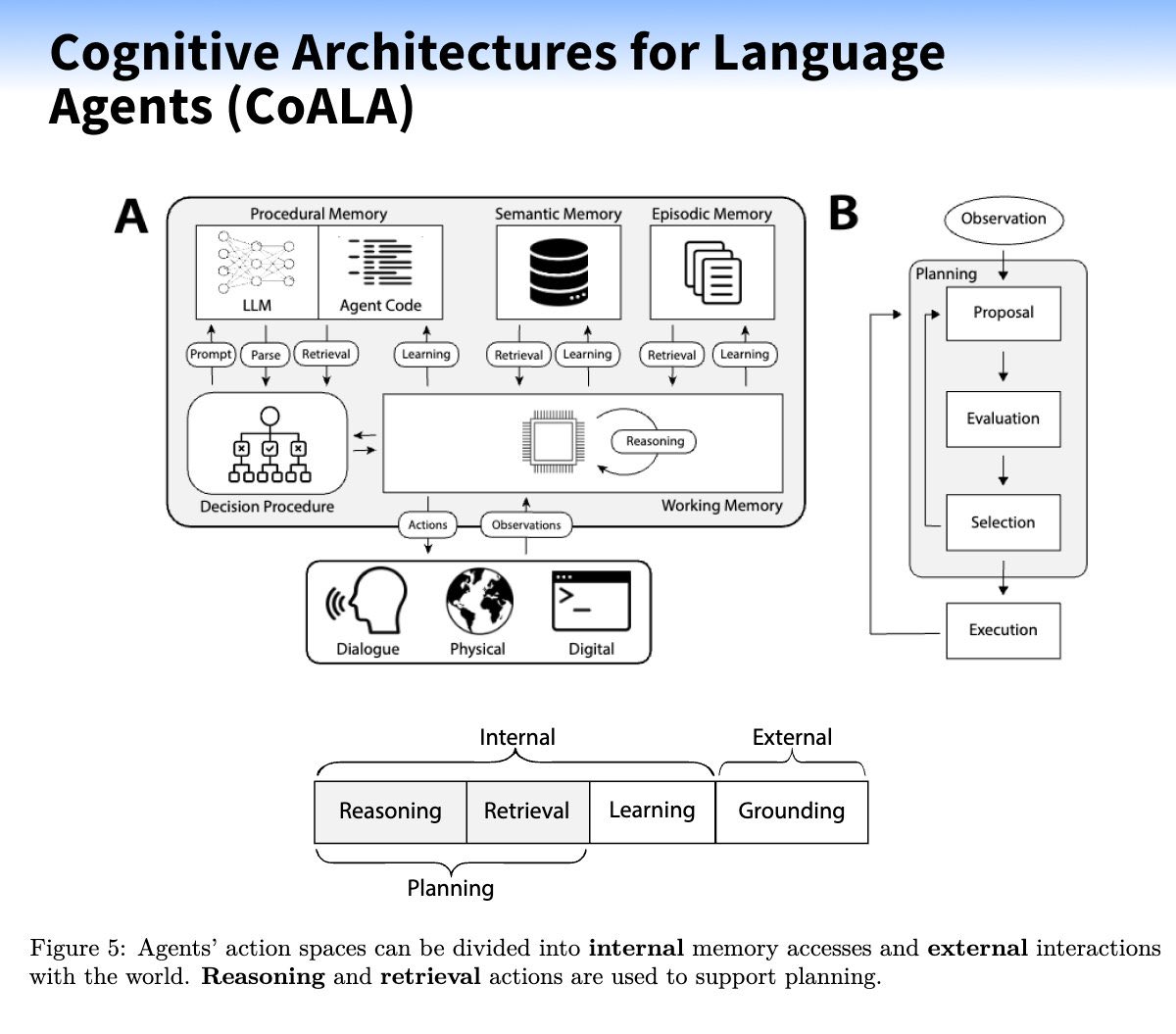
识破钓鱼骗局的五大关键,保护你的数字安全!
1. 可疑发件人:
- 检查发件人的邮箱地址。注意类似“support@apple.com”与“support@app1e.com”的细微差别,这种域名的细微变化是警示信号。
2. 通用问候语:
- 邮件以“亲爱的用户”开头而不是你的名字。正规公司通常会直接称呼你的名字。
3. 紧迫感:
- 邮件声称“如果不验证信息,你的账户将在24小时内被暂停”。这种紧迫感是为了诱使你快速行动,而不经过思考。
4. 异常请求:
- 例如,银行要求你提供密码或PIN码。银行通常不会通过邮件索取如此敏感的信息。
5. 链接和附件:
- 收到带有更新账户链接的邮件,悬停时发现URL看起来可疑,如“https://t.co/hKdSzJNECE”,而不是银行的官方网站。
这些技巧可以帮助你更好地识别并避免钓鱼诈骗,提高你的网络安全意识。 
揭秘SSH的神奇工作原理:从连接到加密的全流程解析!
这张图详细展示了SSH(Secure Shell)协议的工作流程:
1. 建立TCP连接:SSH客户端和服务器首先建立一个TCP连接。
2. 版本协商:双方协商支持的SSH版本。
3. 算法协商:选择加密和认证算法。
4. 生成密钥对:客户端生成公钥和私钥对。
5. 发送公钥:客户端将公钥发送给服务器。
6. 发起登录请求:客户端请求登录服务器。
7. 匹配公钥并加密消息:服务器在`~/.ssh/authorized_keys`中找到匹配的公钥,并用它加密消息。
8. 返回加密的随机数:服务器返回一个加密的随机数,供客户端验证。
9. 使用私钥解密数据:客户端用私钥解密收到的数据。
10. 发送解密后的数据:客户端发送解密后的数据给服务器。
11. 验证客户端解密正确性:服务器验证客户端解密是否正确。
12. 会话请求和响应:建立会话并进行响应交流。
13. 发送加密命令:客户端发送加密后的命令给服务器执行。
14. 使用会话密钥解密命令:服务器用会话密钥解密命令并执行。
15. 发送加密结果:服务器返回执行结果,并进行加密处理。
16. 使用会话密钥解密结果:客户端用会话密钥解密收到的结果。
此外,图中还展示了SSH本地转发(Local Forwarding),用于通过安全隧道将本地端口流量转发到远程服务器,提供安全的数据传输通道。 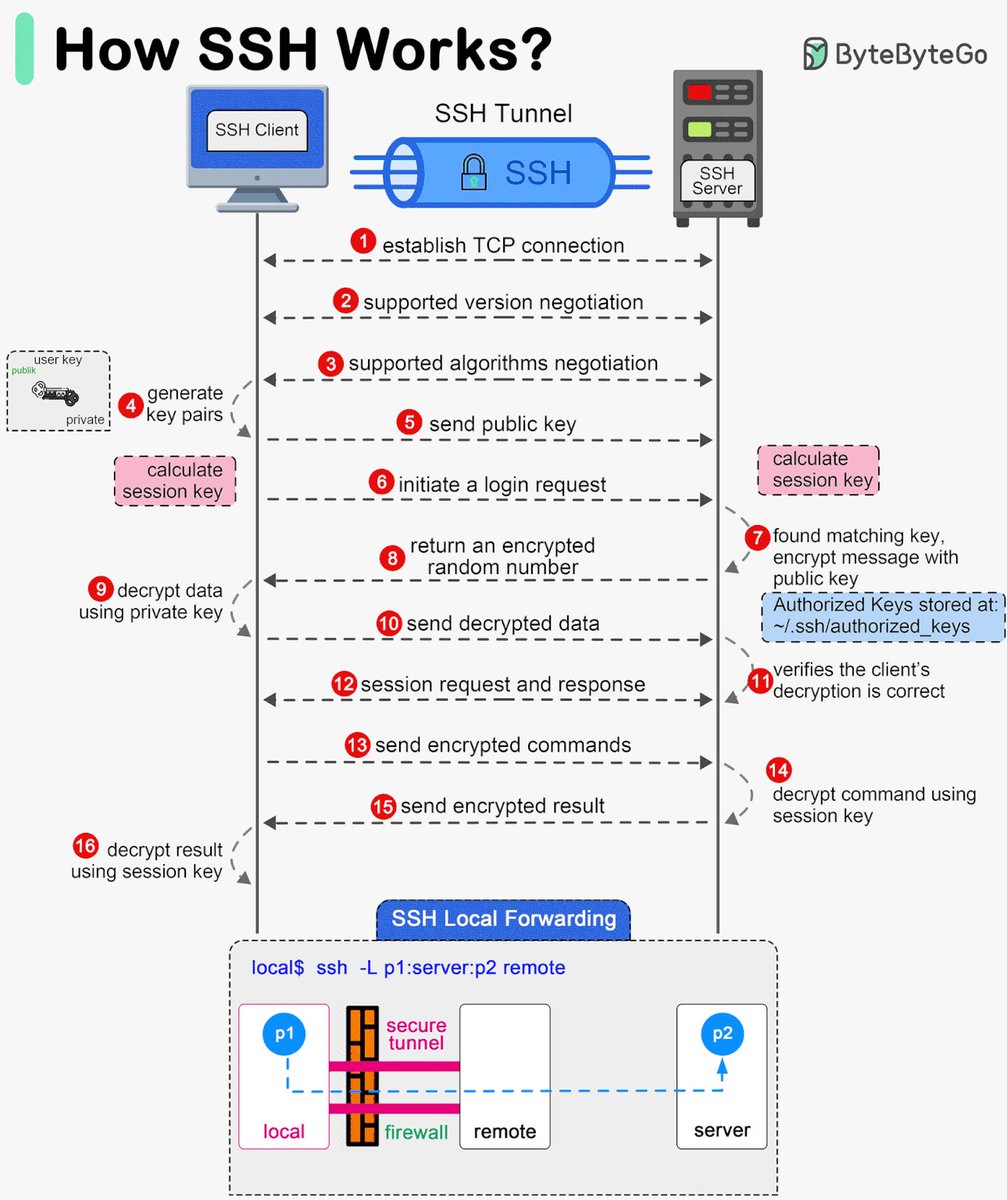
诺贝尔颁奖委员会解释为什么诺贝尔物理奖颁发给人工智能科学家!人工神经网络揭秘!揭示大脑的奥秘
你知道吗?人工神经网络是为了模拟大脑而设计的!
受到大脑中生物神经元的启发,人工神经网络由大量“神经元”或节点组成,这些节点通过“突触”或加权连接相连,并经过训练来执行特定任务。人工神经网络使用其整个网络结构来处理信息。这种灵感最初来源于人们对理解大脑工作原理的渴望。
了解更多关于今年因人工神经网络研究而获颁物理学奖的信息:https://t.co/q9AVrifnDu
NobelPrize 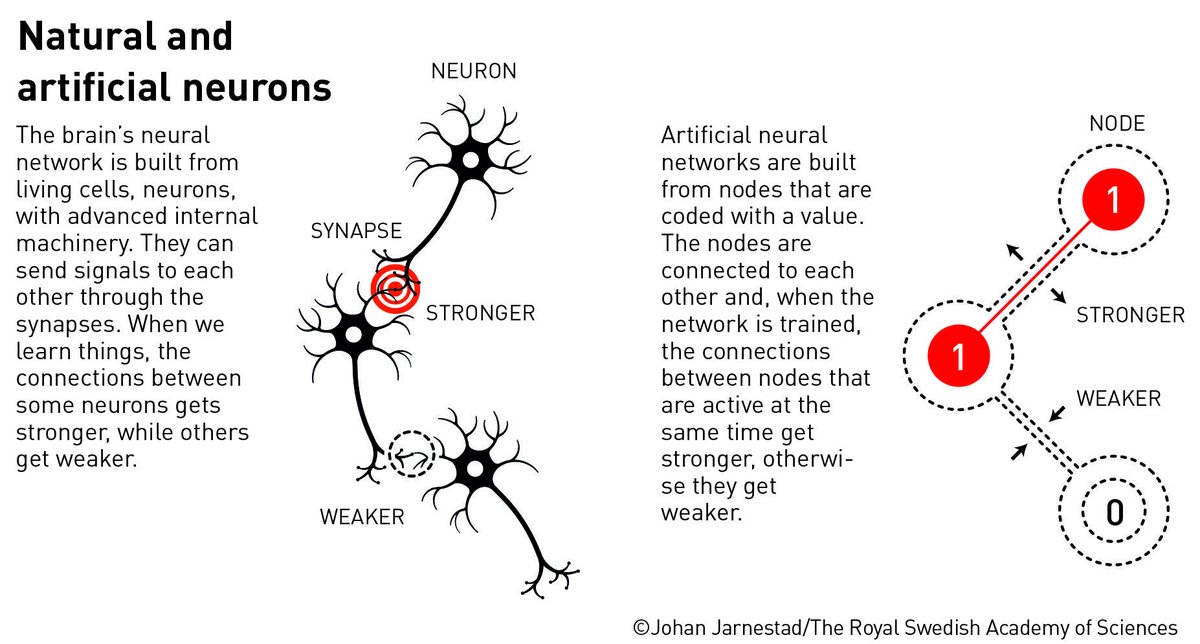
机器学习中的十大损失函数,轻松搞懂模型优化!
这张图表详细介绍了机器学习中常用的十种损失函数,它们是优化模型性能的关键工具。让我们用大白话来解读这些函数。
回归损失函数
1. 平均偏差误差 (Mean Bias Error):
- 主要用于捕捉预测中的平均偏差,但不常用于训练。
2. 平均绝对误差 (Mean Absolute Error, MAE):
- 测量预测与实际值之间的平均绝对差距,也称为L1损失。
3. 均方误差 (Mean Squared Error, MSE):
- 计算预测与实际值之间的平方距离,是L2损失的一种。
4. 均方根误差 (Root Mean Squared Error, RMSE):
- MSE的平方根,确保损失和变量单位一致。
5. Huber损失 (Huber Loss):
- 结合了MSE和MAE的优点,是一种参数化的损失函数。
6. Log Cosh损失:
- 类似于Huber Loss,但非参数化,计算成本较高。
分类损失函数
1. 二元交叉熵 (Binary Cross Entropy, BCE):
- 用于二元分类任务,衡量预测概率与实际标签之间的差异。
2. Hinge损失:
- 用于支持向量机(SVM),惩罚错误和不够自信的预测。
3. 交叉熵损失 (Cross Entropy Loss):
- BCE的扩展,用于多类别分类任务。
4. KL散度 (KL Divergence):
- 最小化预测分布与真实概率分布之间的差异。
这些损失函数是机器学习模型训练中的基础工具,它们帮助我们衡量模型性能并进行优化。通过选择合适的损失函数,可以更好地提升模型在不同任务中的表现。 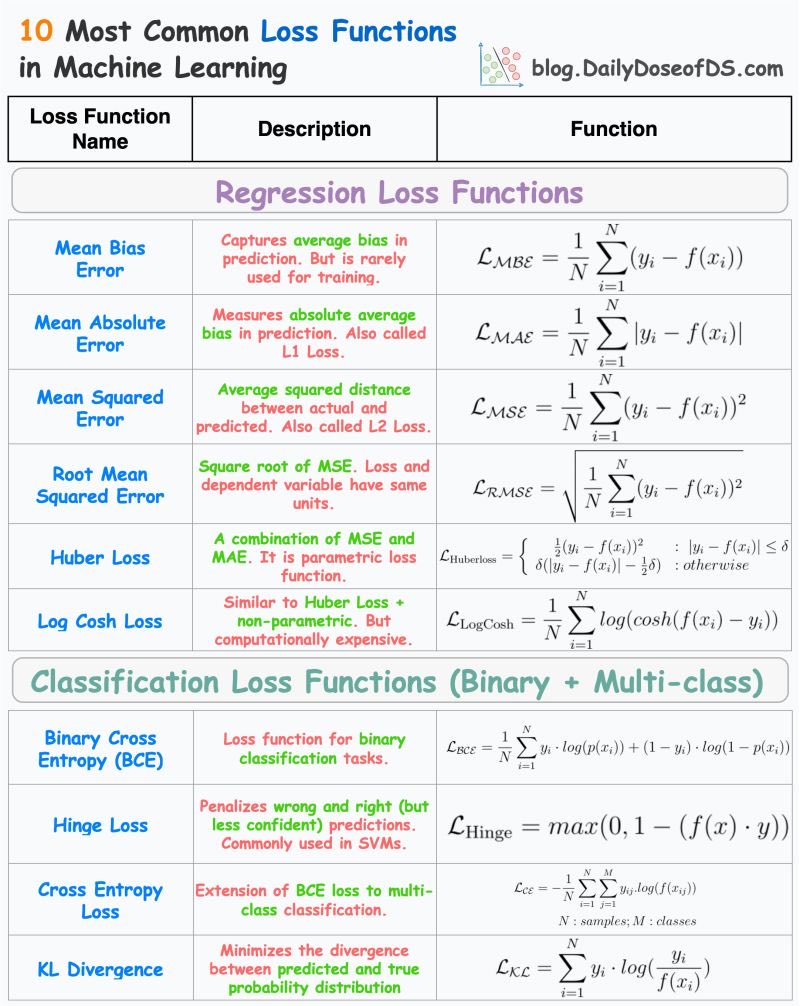
以下是瑞典皇家科学园新闻稿给出的两位获奖者获奖原因的解释(原文见:https://t.co/cI98J8vY0q)
约翰·霍普菲尔德发明了一种网络,它使用一种保存和重新创建模式的方法。我们可以将节点想象成像素。霍普菲尔德网络利用物理学来描述材料由于原子自旋而产生的特性——这种特性使每个原子都成为一个微小的磁铁。整个网络的描述方式相当于物理学中自旋系统的能量,并通过寻找节点之间连接的值来进行训练,以便保存的图像具有较低的能量。当霍普菲尔德网络被输入扭曲或不完整的图像时,它会有条不紊地处理节点并更新它们的值,从而降低网络的能量。因此,网络逐步找到与输入的不完美图像最相似的保存图像。
杰弗里·辛顿 (Geoffrey Hinton)以霍普菲尔德网络为基础,创建了一个采用不同方法的新网络:玻尔兹曼机。它可以学习识别给定类型数据中的特征元素。辛顿使用了统计物理学的工具,统计物理学是一门由许多相似组件构建的系统科学。通过输入机器运行时很可能出现的示例来训练机器。玻尔兹曼机可用于对图像进行分类,或创建训练模式类型的新示例。辛顿在此基础上继续发展,帮助开启了机器学习的爆炸式发展。
John Hopfield最初是一位物理学家,他的研究领域包括量子统计力学和凝聚态物理。后来,他将研究兴趣扩展到了生物物理学,探索生物系统中的物理过程。Hopfield在1982年提出了著名的Hopfield网络,这是一种能够进行联想记忆的神经网络模型,这一发现标志着物理学思想在神经网络研究中的首次重大突破。此后,物理学家在神经网络和神经动力学的研究中发挥了重要作用,他们的工作不仅推动了理论的发展,也为实际应用提供了理论基础。
2001年,Hopfield因其在生物学作为物理过程理解方面的跨学科贡献而获得了的国际理论物理中心狄拉克奖章。他的工作涵盖了生物分子合成中的校对过程、神经网络中吸引子的集体动力学和计算,为打通物理学和人工神经网络的基础研究指明了方向。 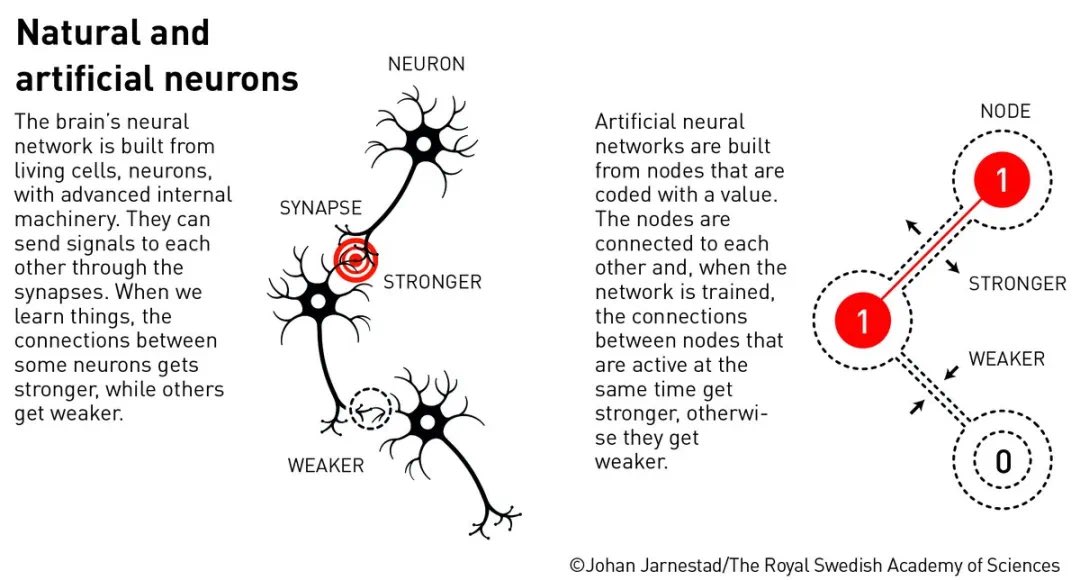
Y Combinator 2024市场版图的未来趋势,正在重塑全球市场格局!
据https://t.co/St5O59mmxt分析,这张图展示了Y Combinator在2024年支持的初创公司在多个前沿领域的分布情况,显示出人工智能在各行业中的深度渗透和广泛应用。以下是几个关键领域的深度解读:
1. AI 在金融科技的应用:
- 图中标注了“AI-powered fintech automation”和“Fintech and Construction Tech Startups”,表明AI正在推动金融科技自动化和建筑科技初创企业的发展,简化流程并提高效率。
2. 生产力工具与销售自动化:
- 诸如“Conversational AI Productivity Tools”和“AI-powered Sales Automation”这样的标签显示出AI在提升企业生产力和销售流程自动化方面的巨大潜力。
3. 数据分析与优化:
- “AI-powered data analytics and optimization tools”突显出数据分析和优化工具在商业决策中的重要性,帮助企业实现更精确的数据驱动决策。
4. 医疗保健技术革新:
- “Healthcare data management”和“Biotech and AI startups disrupting healthcare”标志着AI在医疗数据管理和生物技术创新中的突破性进展,可能彻底改变医疗服务模式。
5. 多样化产业的变革:
- 从“Robotics and automation solutions”到“Space/Energy/Chip Startups”,这些初创公司表明AI不仅限于传统IT领域,还扩展至机器人、能源及芯片制造等多个行业,推动全方位的产业升级。
这张市场版图清晰地描绘了Y Combinator如何通过支持各种创新驱动的初创公司来重塑市场。这些企业利用AI技术,不仅提高了传统行业的效率,还开拓了新的商业机会,为未来经济增长提供了动力。 
解锁生物医学未来:机器学习与深度学习算法的革命性应用
这张图表展示了生物医学研究中常用的算法及其具体应用,分为监督学习和无监督学习两大类。
监督学习
1. 机器学习:
- SVM(支持向量机):用于癌症与健康分类(基因表达)。
- KNN(k近邻):用于多分类组织分类(基因表达)。
- Regression(回归):用于全基因组关联分析(SNP)。
- Random Forest(随机森林):用于基于路径的分类(基因表达,SNP)。
2. 深度学习:
- CNN(卷积神经网络):用于蛋白质二级结构预测(氨基酸序列)。
- RNN(循环神经网络):用于序列相似性预测(核苷酸序列)。
无监督学习
1. Clustering(聚类):
- Hierarchical(层次聚类):用于蛋白质家族聚类(氨基酸序列)。
- K-means(k均值聚类):用于按染色体聚类基因(基因表达)。
2. Dimensionality Reduction(降维):
- PCA(主成分分析):用于异常值分类(基因表达)。
- tSNE(t-分布随机邻域嵌入):用于数据可视化(单细胞RNA测序)。
- NMF(非负矩阵分解):用于聚类基因表达谱(基因表达)。
这些算法在生物医学研究中扮演着关键角色,帮助科学家从复杂数据集中提取有价值的信息,推动医疗技术的进步。 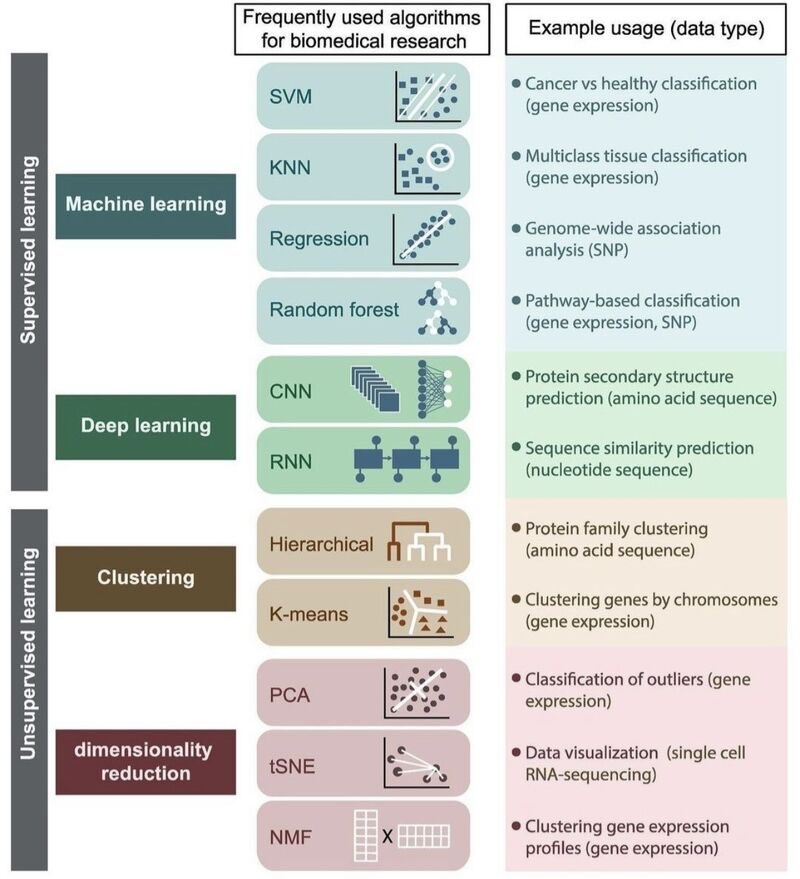
深入浅出:简单线性回归的核心概念与应用指南
这张图详细讲解了简单线性回归的基本理论及其应用方法。。
主要内容解读:
1. 简单线性回归简介:
- 线性回归是一种常见的统计回归方法,用于预测分析。
- 目标是找到自变量(预测变量)和因变量(输出)之间的线性关系。
2. 计算方法:
- 使用线性方程 \( Y_i = Ax + B \) 来计算最佳拟合直线。
- 其中 \( A \) 是斜率,\( B \) 是截距。
3. 定义最佳拟合:
- 最佳拟合线是使误差最小的那条直线。
- 误差被定义为预测值与实际值之间的差异。
4. 数学求解:
- 使用代价函数(如均方误差,MSE)来寻找 \( A \) 和 \( B \) 的最优值。
- 梯度下降法是一种常用的优化算法,用于最小化代价函数。
5. 模型评估:
- 常用指标包括决定系数(R²)和均方根误差(RMSE)。
6. 应用假设:
- 变量之间需要线性依赖。
- 残差相互独立。
- 残差呈正态分布,平均值接近零。
- 残差具有恒定方差。
通过这些步骤和假设,简单线性回归能够有效地用于数据建模和预测分析。 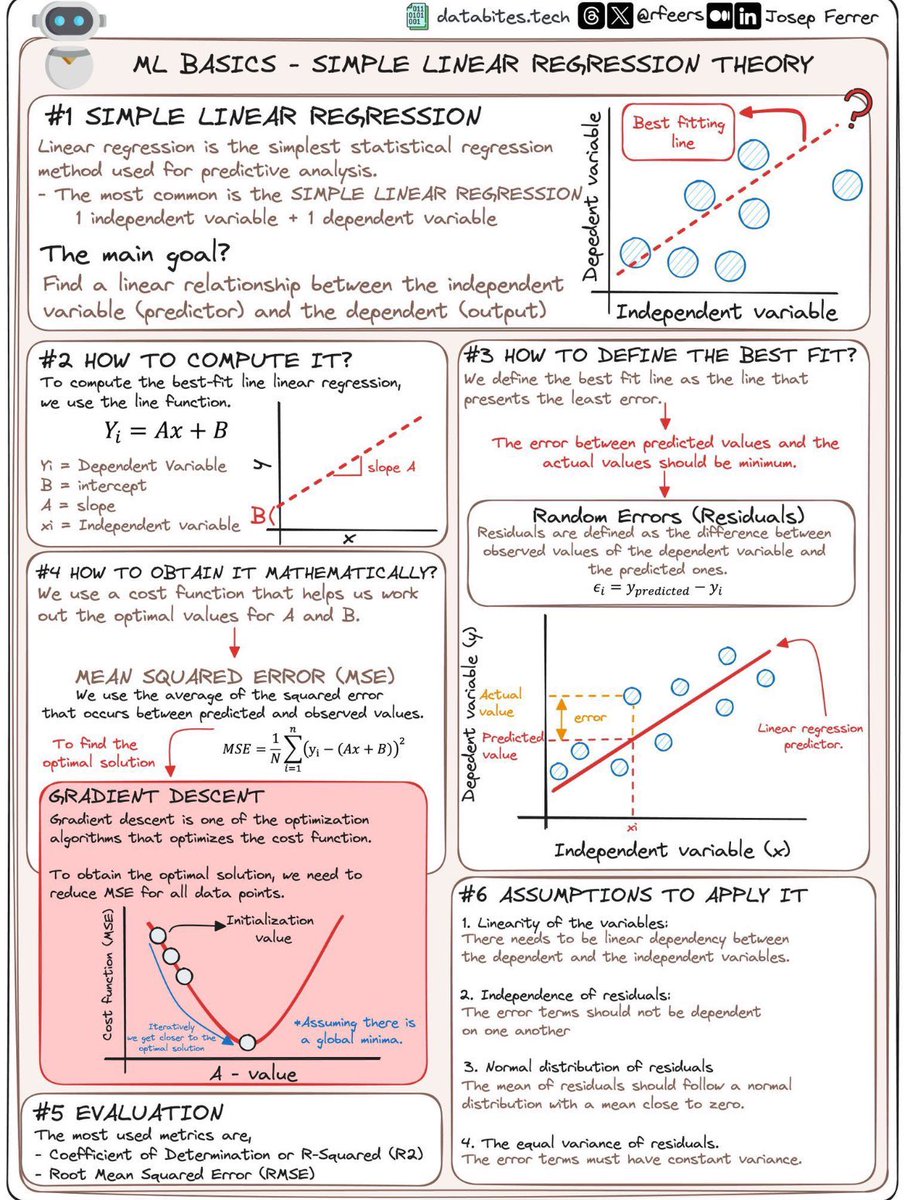
解密AI Agent智能:自我反思与多AI Agent协作的设计模式
这张图展示了多种AI设计模式,强调如何利用语言模型(LLM)实现复杂任务。这些模式包括自我反思、工具使用、规划以及多代理协作。
1. Agentic Self Reflection
- 概念:模型不仅生成代码,还能评估自己的输出。
- 功能:通过自我反思,识别错误并改进解决方案。
- 应用:例如,生成代码后进行单元测试以确保正确性和效率。
2. Agentic with Tool Use
- 概念:借助工具和外部资源增强问题解决能力。
- 功能:结合搜索工具与模型推理,实现信息综合。
- 应用:使用工具进行搜索,再由模型整合结果。
3. Agentic Planning
- 概念:应用各种规划技术,从传统方法到AI驱动的创新。
- 功能:分解任务、选择计划并进行反思与改进。
- 应用:重构应用程序代码,通过分步规划实现优化。
4. Multi-Agentic
- 概念:多个代理协同工作,以完成复杂任务。
- 功能:每个代理有不同的设计模式,相互协作。
- 应用:从供应链到烘焙店的复杂任务管理,通过不同代理协调完成。
总结
这些设计模式展示了如何利用语言模型进行创新性任务管理。通过自我反思、工具集成和多代理协作,可以实现更高效、更智能的系统。这些模式为未来AI的发展提供了重要参考。 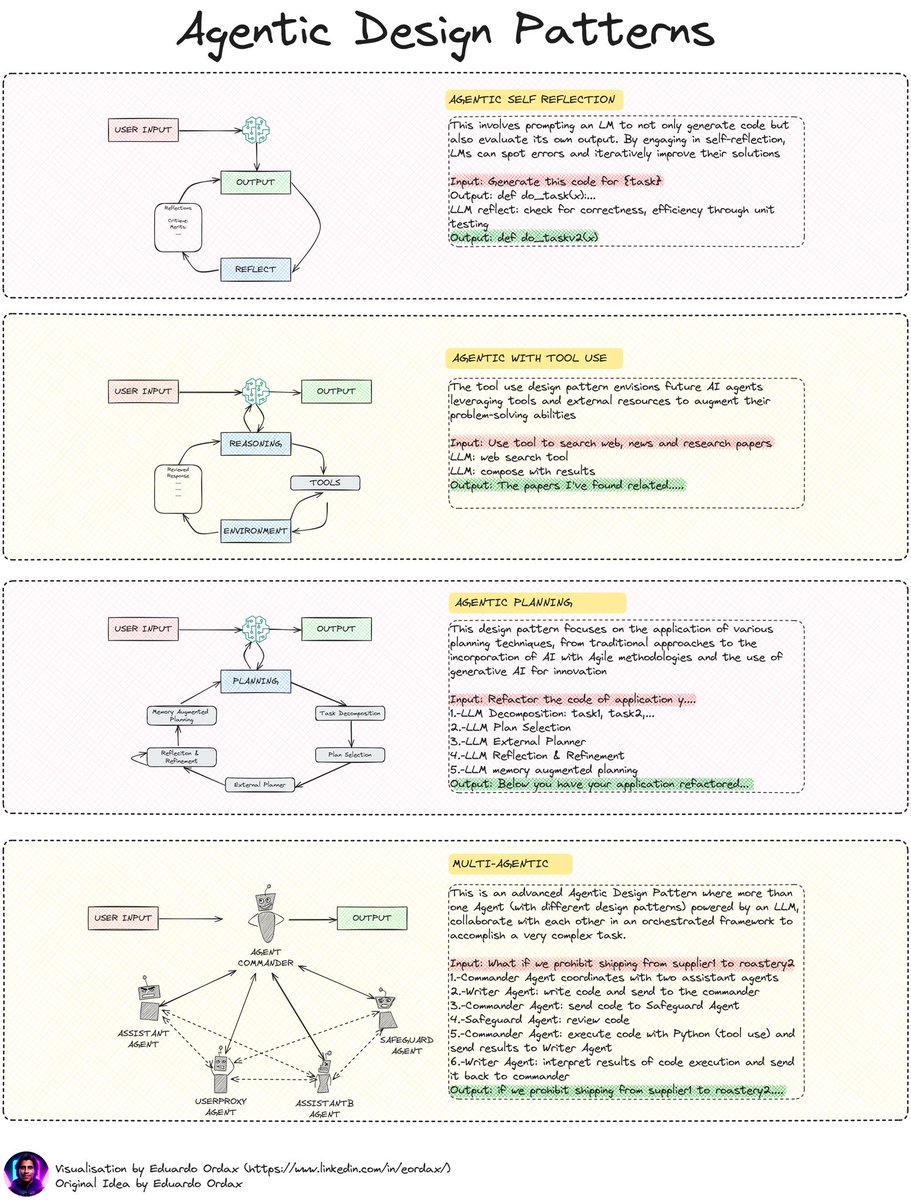
解码未来:数据科学、人工智能与机器学习的深度交织
这张图展示了数据科学、人工智能(AI)和机器学习(ML)之间的关系及其各自的特点。
数据科学
- 定义:数据科学是关于数据的收集、准备和分析的领域。
- 功能:利用AI/ML技术、研究、行业专长和统计来做出商业决策。
- 范围:数据科学是一个广泛的领域,包含了AI和ML。
人工智能(AI)
- 定义:人工智能是让机器理解、解释、学习并做出智能决策的技术。
- 功能:包括多种领域,其中之一就是机器学习。
- 特性:AI旨在模拟人类智能,涵盖从简单任务自动化到复杂问题解决。
机器学习(ML)
- 定义:机器学习是通过算法帮助机器进行改进的一种方法,包括监督学习、非监督学习和强化学习。
- 功能:作为AI和数据科学工具的一部分,用于提高机器性能。
- 特性:它专注于通过数据训练模型,让机器能够自我改进。
总结
- 数据科学是一个更广泛的领域,包含AI和ML,用于分析和决策。
- AI是让机器具备智能行为的技术框架,其中ML是其实现手段之一。
- ML专注于开发算法,让机器从经验中学习和提高。
通过这张图,可以看到三者如何协同工作,以推动技术进步和商业应用。 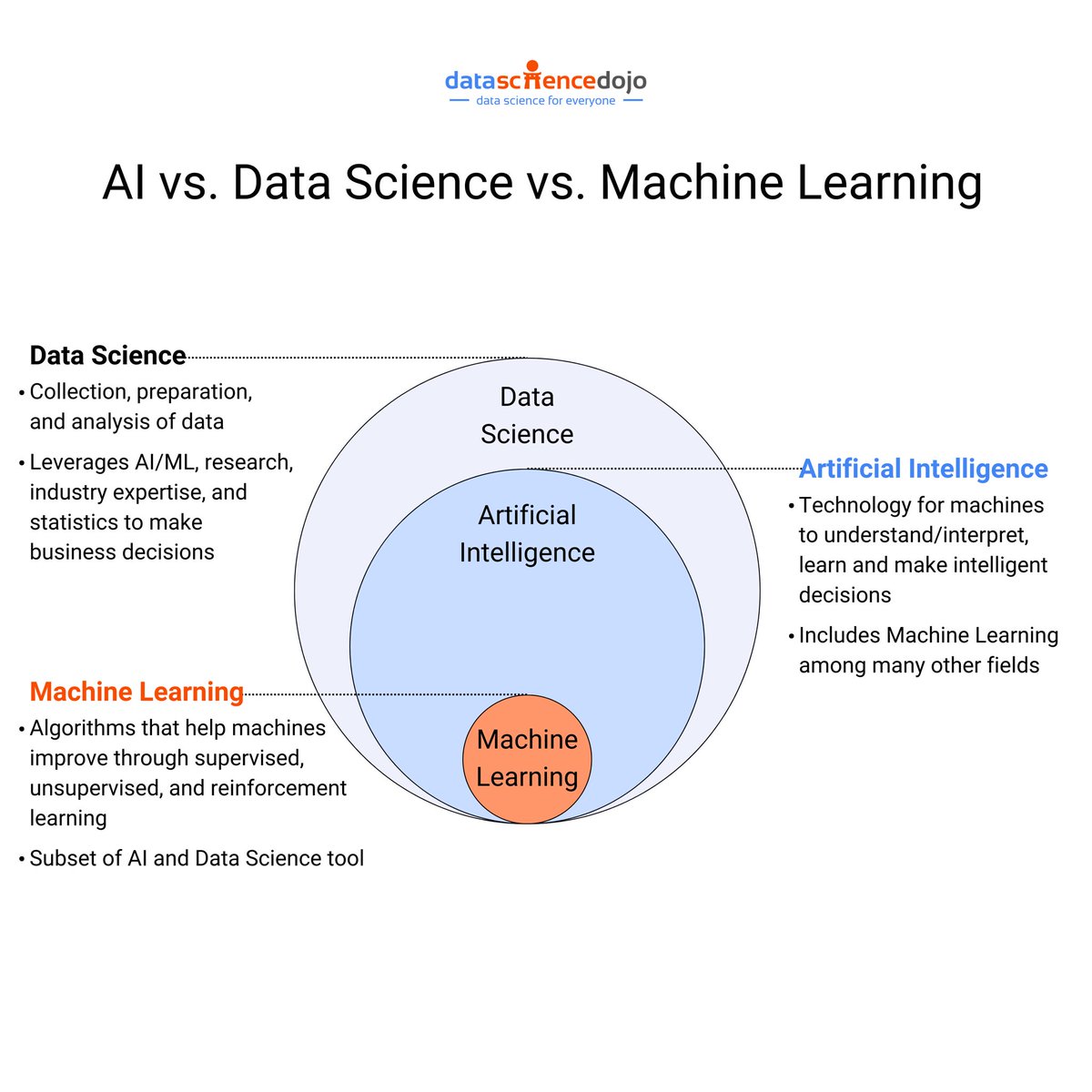
全面掌握API开发:从入门到精通的路线图
无论你是初学者还是有经验的开发者,学习API都是当今软件开发中至关重要的一部分。这份全面的API学习路线图将指导你掌握关键概念和技术。
1. API简介
- API定义:API(应用程序编程接口)是一组用于构建软件应用的协议、例程和工具。它规定了软件组件如何交互。
- API类型:
- 公共API:对外部开发者开放使用(例如,Twitter API)。
- 私有API:在组织内部使用。
- 合作伙伴API:与特定商业伙伴共享。
- 复合API:结合多个数据或服务API。
2. API架构
- REST(表述性状态转移):一种广泛使用的Web API架构风格。
- GraphQL:一种允许客户端请求特定数据的查询语言。
- SOAP(简单对象访问协议):用于交换结构化数据的协议。
- gRPC:由Google开发的高性能开源框架。
- WebSockets:实现客户端和服务器之间的全双工实时通信。
- Webhook:允许实时通知和事件驱动架构。
3. API安全
- 认证:基本认证、OAuth 2.0、JSON Web Tokens (JWT)。
- 授权:控制资源访问权限。
- 速率限制:通过限制请求数量防止滥用。
- 加密:通过HTTPS保护数据传输。
4. API设计最佳实践
- 使用HTTP方法正确,并确保资源命名合理。
- 实施版本控制,例如URI版本控制(/v1/users)、查询参数版本控制(/users?version=1)、头部版本控制(Accept: application/vnd.company.v1+json)。
- 高效处理大数据集分页。
- 正确使用HTTP状态码并提供信息丰富的错误消息。
5. API文档
- 使用Swagger/OpenAPI规范来描述RESTful API。
- Postman是流行的API开发和文档工具。
- ReDoc是生成美观API文档的工具。
6. API测试
- Postman允许创建和运行API测试。
- SoapUI是用于测试SOAP和REST API的工具。
- JMeter用于性能和负载测试。
- 使用Mockoon或Postman's mock servers等工具进行API模拟响应。
7. API管理
- API网关如Azure API Management、AWS API Gateway、Kong、Apigee等。
- 生命周期管理包括Postman Collections、RapidAPI、Akan等工具。
- 使用Moesif、Datadog、ELK Stack(Elasticsearch, Logstash, Kibana)进行API分析和监控。
8. 实现框架
- Python框架包括Flask、Django REST framework、FastAPI。
- JavaScript框架包括Express.js。
- Java框架包括Spring Boot。
场景解读
假设你是一家电商公司的技术负责人,你希望通过公共API让第三方开发者可以访问你的产品目录以便创建插件或应用。你可以使用RESTful架构来设计这个公共API,确保每个产品信息都能通过HTTP请求获取。同时,通过OAuth 2.0来认证用户,以保证只有授权用户才能访问敏感信息。此外,你可以利用Swagger生成清晰易懂的文档,帮助开发者快速理解如何调用你的接口,从而提升整体用户体验。
这份路线图为任何想要深入了解APIs的人提供了全面指南,无论是为了个人项目还是职业发展。掌握这些概念后,你将能够更好地驾驭现代软件开发的复杂性。 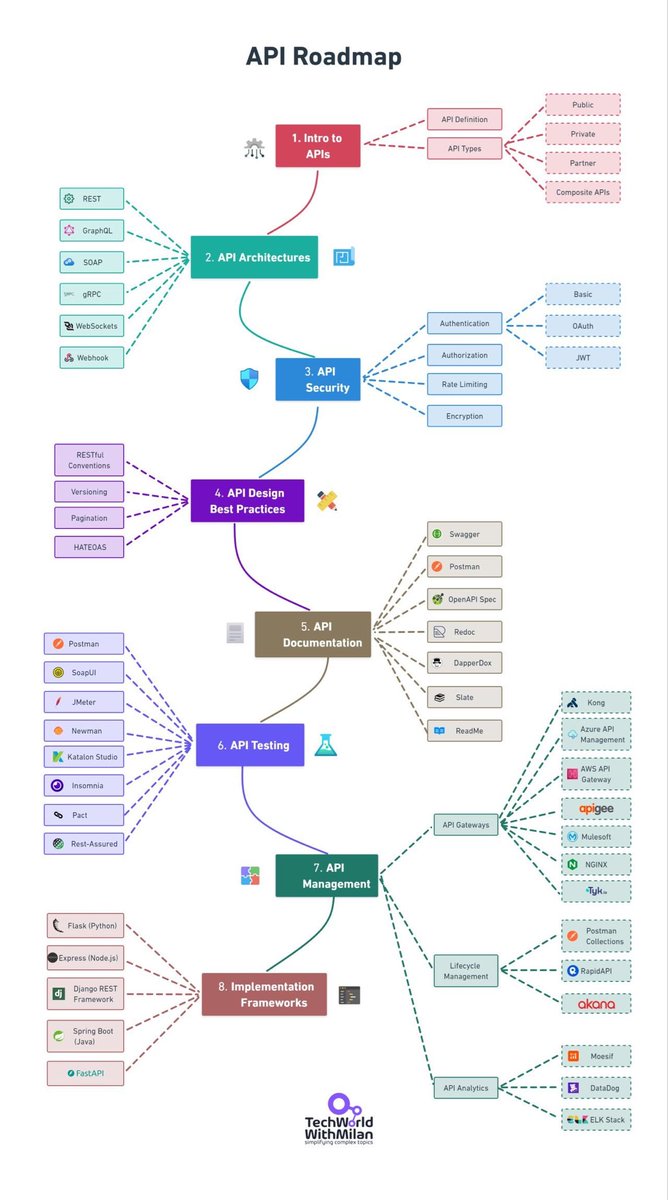
语音AI市场的爆发:未来的科技巨头
ElevenLabs:成功崛起的典范
在这个快速发展的市场中,ElevenLabs无疑是最引人注目的参与者之一。根据TechCrunch报道,该公司在成立仅两年内便实现了年经常性收入(ARR)达8000万美元的惊人成绩。这一非凡成就突显了语音AI解决方案在不同领域中日益增加的采用率,从客户服务到内容创作,无所不包。
语音AI市场格局
当前,语音AI市场呈现出多样化的应用和平台。企业正在利用语音技术提升用户体验、简化运营流程,并创造创新产品。随着越来越多企业认识到将语音功能整合到其产品中的价值,这一市场有望迎来指数级增长。
总而言之,语音AI领域不仅是一个重要的市场机会,更是创新的催化剂。在像ElevenLabs这样的公司引领下,语音技术的未来显得极为光明。随着市场的持续演变,它必将重塑我们与数字世界沟通和互动的方式。 
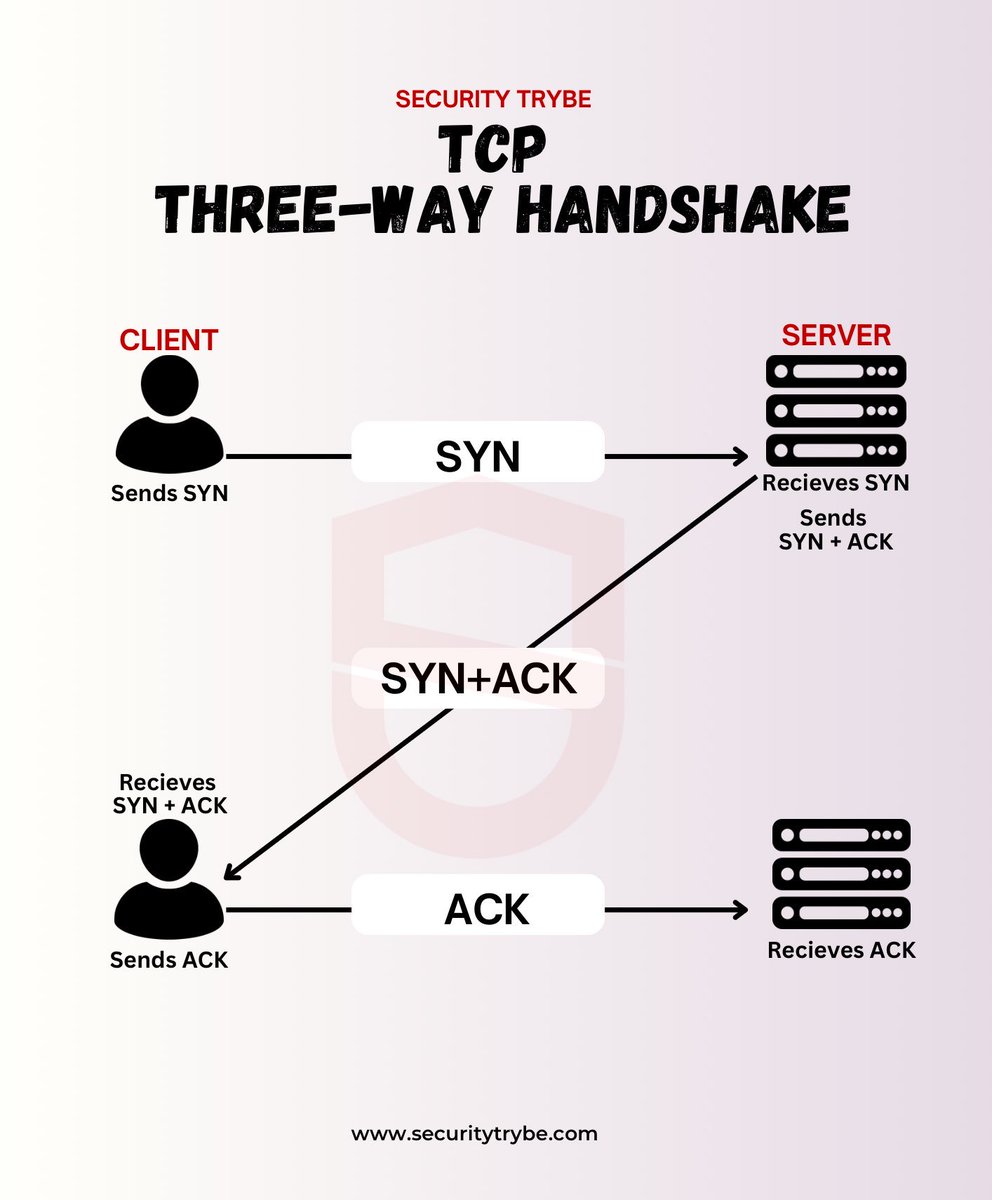
解密互联网:TCP三次握手的奥秘与重要性
TCP三次握手是建立TCP连接的基本过程,确保客户端和服务器之间的连接可靠。以下是详细解读:
1. 第一次握手(SYN):
- 客户端向服务器发送一个SYN(同步序列编号)请求包。
- 这是为了请求建立连接,并初始化一个序列号。
2. 第二次握手(SYN+ACK):
- 服务器收到SYN请求后,会返回一个SYN+ACK包。
- 这表示服务器同意建立连接,并同时向客户端发送自己的SYN请求。
- ACK是对客户端初始SYN的确认,表示已收到。
3. 第三次握手(ACK):
- 客户端收到服务器的SYN+ACK后,向服务器发送一个ACK包。
- 这个包确认收到了服务器的SYN请求。
- 一旦服务器收到这个ACK包,双方确认连接已建立,可以开始数据传输。
通过这三次握手,确保了双方都能够接收到彼此的消息,保证了通信的可靠性和准确性。这种机制有效地防止了丢包和错误连接,是互联网通信协议中关键的一部分。