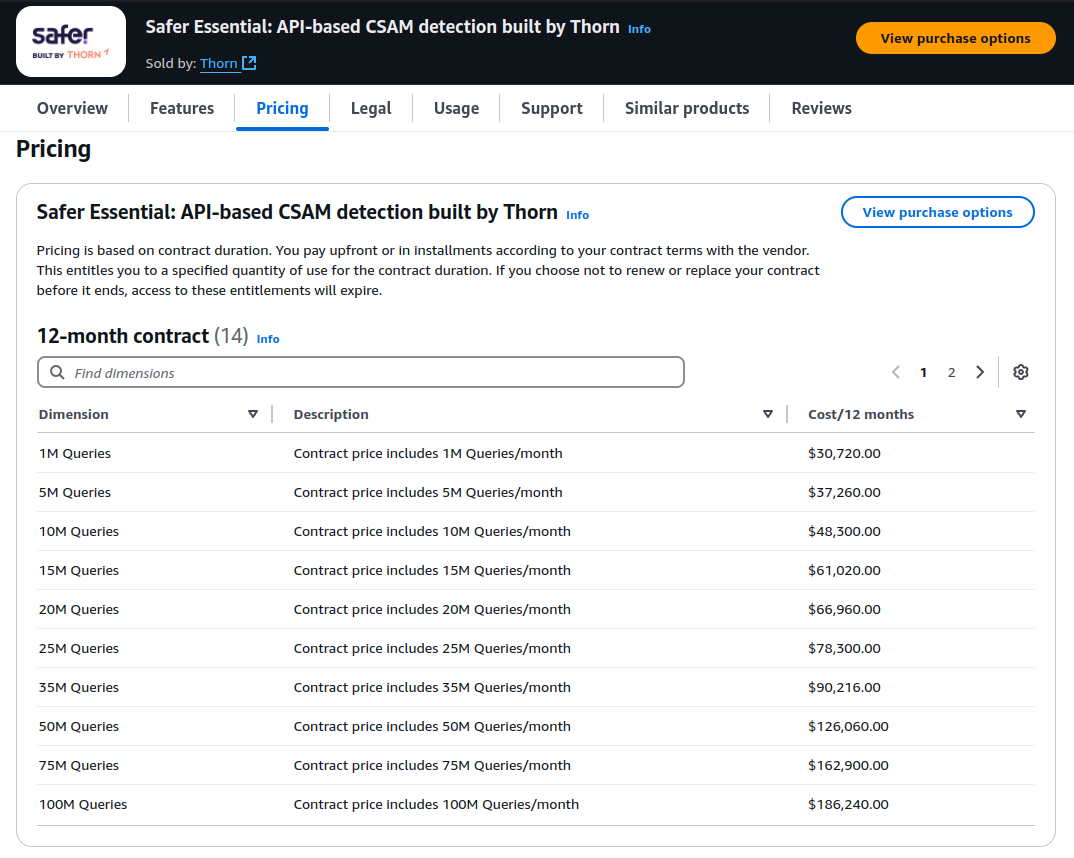
Broadcasting public notes that identify CSAM is probably illegal, because it could be construed as "advertising" that content. I think the only option we really have long-term, at least in the US, is for someone(s) to run a service that crawls the network, matches images against microsoft's hash database product (closed source, but for good reasons, since hash databases can be reverse engineered), and reports matches to NCMEC. A bonus would be to do the same thing but analyze note text for exploitation keywords. Privately hosted and encrypted content are pretty much immune to this fortunately/unfortunately. nostr:nprofile1q9n8wumn8ghj7enfd36x2u3wdehhxarj9emkjmn99ah8qatzx96r2amr8p5rxdm4dp4kzafew3ehwwpjwd48smnywycrgepndcu8qd3nx36hguryvem8xdr5d56hsmt5xfehzemtxejxkeflvfex7ctyvdshxapaw3e82egprfmhxue69uhhyetvv9ujumn0wd68yanfv4mjucm0d5hszrnhwden5te0dehhxtnvdakz7qg3waehxw309ahx7um5wgh8w6twv5hsz9nhwden5te0wfjkccte9ekk7um5wgh8qatz9uqzpxvf2qzp87m4dkzr0yfvcv47qucdhcdlc66a9mhht8s52mprn7g98p5le2 currently checks a hash database for all images uploaded, and I believe they report matches.
As non-cypherpunk as this all is, I think it's the only real option we have unless Ross Ulbricht's ZKANN idea gets built. We need to demonstrate to anyone watching that we take the problem seriously and take measures to self-regulate. This is similar to the bitcoin KYC/AML argument. If we don't want financial surveillance or legal restrictions on social media, we should help law enforcement actually chase down the people who are the problem rather than presenting ourselves as the scapegoat. See iftas.org for some work being done in the fediverse on this.