为什么你应该尝试左侧睡觉?——看完你就明白了!
左侧睡觉的好处:
- 减轻胃酸反流:左侧睡觉时,胃和胃液的位置低于食道,有助于减少胃酸反流和烧心。
- 促进消化:这种姿势有助于胃液更好地流动,促进消化过程,减少肠胃不适。
图解说明:
- 右侧睡觉:胃液容易回流到食道,导致烧心和消化不良。
- 左侧睡觉:胃液顺畅流向肠道,避免回流,提高消化效率。
赶紧试试左侧睡觉,让你的肠胃更舒服! 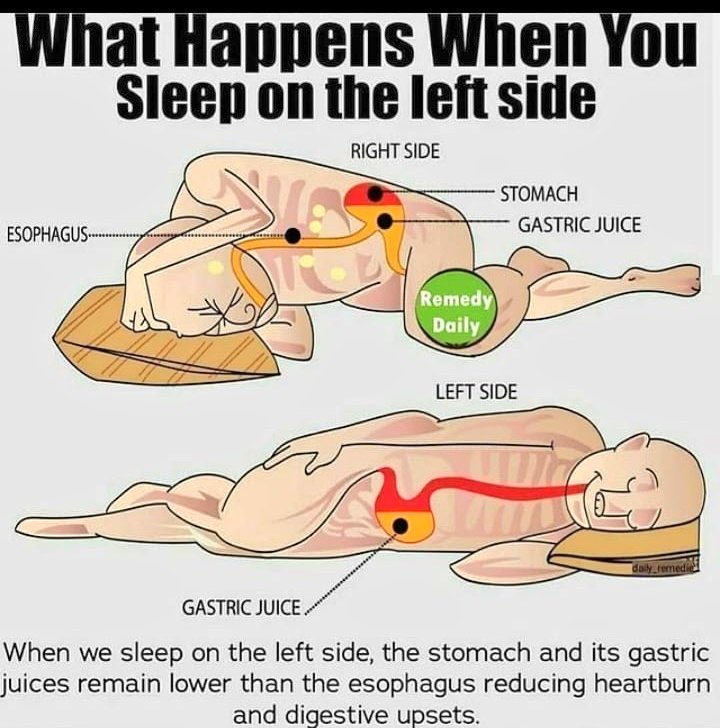
左右脑分工详解:理解大脑的不同功能
这张图展示了人类大脑的左右半球各自擅长的功能和特点。以下是对每个半球功能的详细解读:
左脑(Left Brain)
1. 逻辑(Logic):
- 左脑擅长处理逻辑推理和分析任务,适合解决数学和科学问题。
2. 语言(Language):
- 语言能力主要集中在左脑,包括阅读、写作和口语表达。
3. 现实主义(Realistic):
- 左脑倾向于现实主义,注重实际情况和可行性。
4. 分析能力(Analytic):
- 左脑具备强大的分析能力,能够分解复杂问题并逐步解决。
5. 有序步骤(Ordered Steps):
- 左脑喜欢按照有序的步骤进行工作,注重过程的系统性和结构性。
6. 果断(Decisive):
- 左脑在决策过程中表现得较为果断,迅速作出明确决定。
7. 证据(Evidence):
- 左脑偏好基于事实和证据进行判断和决策。
8. 字面意思(Literal):
- 左脑倾向于按字面意思理解信息,不太擅长抽象思维。
9. 列表(Lists):
- 左脑喜欢使用列表来组织信息和任务,有助于提高效率。
右脑(Right Brain)
1. 情感(Emotion):
- 右脑负责处理情感反应,更加敏感和富有同理心。
2. 非语言沟通(Non-Verbal):
- 右脑在处理非语言信息方面表现出色,例如面部表情和肢体语言。
3. 创造力(Creative):
- 右脑具有高度的创造力,善于创新和发明新事物。
4. 激情(Passion):
- 右脑充满激情,对艺术、音乐等充满热情与投入。
5. 大局观(Big Picture):
- 右脑更擅长从整体上看问题,关注宏观层面的事务。
6. 艺术性(Artistic):
- 右脑具备艺术天赋,能够创造出美术作品和设计方案。
7. 音乐性(Musical):
- 音乐能力主要集中在右脑,包括对旋律、节奏的感知和演奏技能。
8. 关系导向(Relational):
- 右脑更加注重人际关系和社交互动,善于建立亲密关系。
9. 组织混乱(Organized Chaos):
- 虽然看似混乱,但右脑能在混乱中找到自己的逻辑,有条不紊地完成任务。
总结
- 左脑:偏向逻辑、语言、分析及结构化思维。
- 右脑:偏向情感、创造力、大局观及艺术表现。
这张图表帮助我们更好地理解左右半球的不同功能,从而可以根据自身特点来优化学习方法、工作方式以及日常生活中的决策过程。 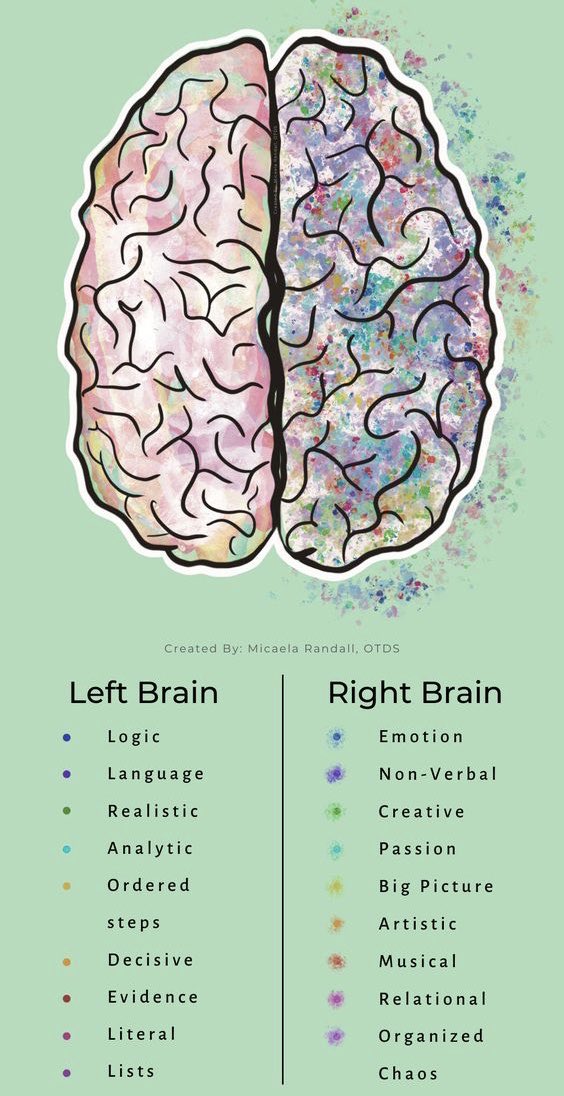
快速提升职业生涯的9大软技能
这张图详细地展示了如何通过9种关键软技能来加速职业发展的具体方法。以下是对每个技能的详细解读:
1. 让人们感到重要(SHR方法):
- 被看到:保持眼神接触,提供具体的赞美。
- 被听到:提出好问题,对他人表现出兴趣而不是仅仅有趣。
- 被记住:跟进,记住他人的名字,并回忆你们讨论过的内容。
2. 优化肢体语言(7-38-55法则):
- 人们会基于7%的言辞,38%的语调和面部表情,以及55%的肢体语言来喜欢或不喜欢你的沟通方式。
- 站直身体,肩膀向后拉,保持眼神接触,给出坚实的握手。
3. 掌握四点更新法:
- 提供更新时使用以下大纲:
1. 你让我做什么
2. 我做了什么
3. 我遇到的风险/阻碍(如果有)
4. 如果有更多时间,我会做什么
4. 记录和研究你的讲话:
- 大多数人不会这样做,但最好的沟通者会记录自己的讲话,然后回放并研究,就像运动员观看比赛录像一样。这可以帮助发现并消除“嗯”和“呃”之类的口头禅。
5. 提出建立关系的问题:
- 与他人建立联系的问题如:
1. 你住在哪个街区?
2. 有兄弟姐妹吗?
3. 如何认识你的伴侣?
4. 有什么有趣的计划吗?
6. 发送“周五亮点”邮件:
- 如果你是团队新成员,这样做可以建立信任。每周五给你的上司发送一封简短邮件,包括两部分内容:
1. 上周的重要事件
2. 下周即将进行的活动
7. 不要抱怨或八卦:
- 没有人喜欢听抱怨。抱怨只会让人对你的评价下降,不要这么做。
8. 记住所有名字:
- 人们最喜欢听到的是他们自己的名字。每次听到一个名字时,记下来,然后询问他们的第二个最喜欢的人或宠物的名字。这会让你脱颖而出。
9. 给自己一个个人MBA:
- 学习意愿是一项重要的软技能。每天阅读30分钟,可以帮助你获得相当于MBA水平的知识。
通过掌握这些软技能,你可以在职场中更具影响力,并且更快地推动你的职业发展。 
人工智能发展史:从1943到2023,一览科技进化之路
这张图详细地展示了从1943年到2023年人工智能(AI)发展的重要里程碑。以下是对每个关键节点的详细解读:
1. 1943年:McCullock和Pitts发表了一篇关于神经网络的论文,奠定了AI的基础。
2. 1950年:图灵提出了著名的“图灵测试”,旨在评估机器的智能水平。
3. 1951年:Marvin Minsky和Dean Edmonds制造了第一个神经网络计算机SNAR。
4. 1956年:达特茅斯会议召开,标志着AI作为一个研究领域正式诞生。
5. 1957年:Rosenblatt开发了感知器,这是第一个具有学习能力的人工神经网络。
6. 1965年:Weizenbaum开发了ELIZA,一个模拟人类对话的自然语言处理程序。
7. 1967年:Newell和Simon开发了GPS(通用问题解决程序),展示了计算机解决问题的能力。
8. 1974年:“第一次AI寒冬”开始,资金减少,对AI研究的兴趣下降。
9. 1980年:专家系统开始流行,企业开始使用这些系统进行预测和医疗诊断。
10. 1986年:Hinton、Rumelhart和Williams发表了一篇关于反向传播算法的论文,使得更深层次的神经网络训练成为可能。
11. 1997年:IBM的深蓝计算机击败国际象棋冠军卡斯帕罗夫,这是计算机首次在比赛中击败世界冠军。
12. 2011年:IBM Watson击败两位Jeopardy!冠军,展示了其强大的问答能力。
13. 2012年:AI初创公司DeepMind开发出能识别YouTube视频内容的深度神经网络。
14. 2014年:Facebook创建DeepFace,一个能够识别人脸并与人类精确度相媲美的人脸识别系统。
15. 2015年:DeepMind开发的AlphaGo在围棋比赛中击败世界冠军李世石。
16. 2017年:谷歌的AlphaZero在一系列比赛中击败世界上最好的象棋引擎,展示了其强大的学习能力。
17. 2020年:OpenAI发布GPT-3,这是自然语言处理领域的一次重大突破,能够生成高质量的人类语言文本。
18. 2021年:DeepMind的AlphaFold2解决了蛋白质折叠问题,为医学研究带来了重大突破和发现。
19. 2022年:谷歌解雇工程师Blake Lemoine,因为他声称其LaMDA对话应用程序具有人类情感。
20. 2023年:艺术家对Stability AI、DeviantArt和MidJourney提起诉讼,指控其Stable Diffusion侵犯版权。
这个时间轴清晰地描绘了人工智能技术如何从理论概念逐步走向实际应用,并在多个领域取得突破性进展。 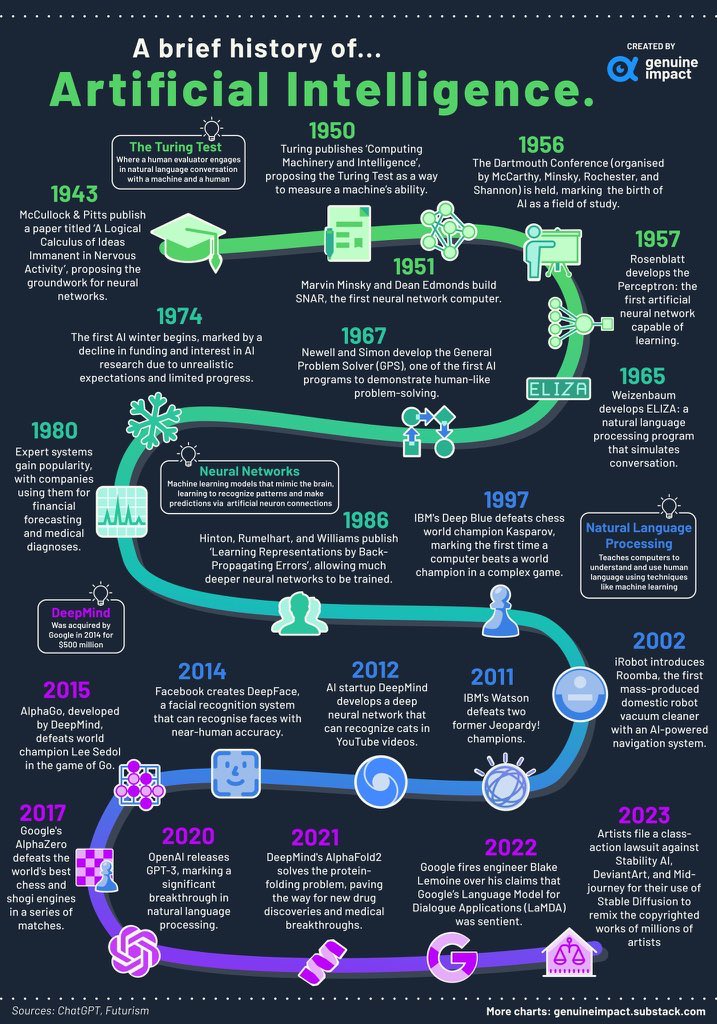
🔍OpenAI多智能体系统如何改变游戏规则?🚀
OpenAI正在重新定义AI的边界,通过多智能体系统的研究,力求在推理能力上实现质的飞跃。多智能体系统允许多个AI协同工作,这种协作不仅提高了复杂问题解决的效率,还能降低计算成本。想象一下,多个智能体像团队一样合作,每个智能体专注于特定任务,从而实现整体目标的优化。这种方法不仅提升了AI的灵活性和适应性,也为更复杂的决策提供了可能。
然而,这项技术并非没有挑战。安全性是一个关键问题,确保智能体之间的信息传递准确无误至关重要。此外,协调多个智能体的行为也是一大难题,需要精密的算法设计和策略制定。
尽管如此,OpenAI对多智能体系统的发展前景充满信心,这不仅预示着AI推理能力的新纪元,也可能彻底改变我们与技术互动的方式。未来已来,你准备好迎接这场变革了吗?🌟 OpenAI 人工智能 科技创新 
深入探索APE - 提示链:提高大模型效率的新方法
通过这种多步骤提示链方法,可以显著提升大模型在复杂任务中的表现。这不仅能更准确地提取信息,还能生成更加精确和有用的响应。对于需要高效处理大量文本数据的应用场景,如客户服务、内容创作和智能问答系统,这种方法尤为适用。
这张图展示了一个称为"APE - Prompt Chaining"的复杂流程,用于在大语言模型(LLM)中实现多步骤提示链,以生成更精确和有用的输出。以下是关键组件和它们的作用:
1. ChatOpenAI:
- 这是第一个模块,负责与OpenAI的语言模型进行交互。它设置了模型名称(如gpt-4.0),调整温度参数,并允许图像上传。这是整个流程的起点。
2. Chat Prompt Template:
- 这个模块用于定义提示模板,包括系统消息和用户消息。系统消息指示助手要执行的任务,例如从文档中提取相关引用。用户消息则提供了上下文或问题。
3. LLM Chain(第一个):
- 这个模块使用预设的语言模型进行文本处理。在这个例子中,它被命名为“extraction”,用于从输入文本中提取有用的信息。
4. Chat Prompt Template(第二个):
- 再次定义一个提示模板,这次主要是为了处理从第一个LLM Chain模块输出的数据,并准备下一步的输入。
5. LLM Chain(第二个):
- 最终的处理模块,接收前一步输出的数据,并生成最终的预测结果。在这个例子中,它被命名为“response”。 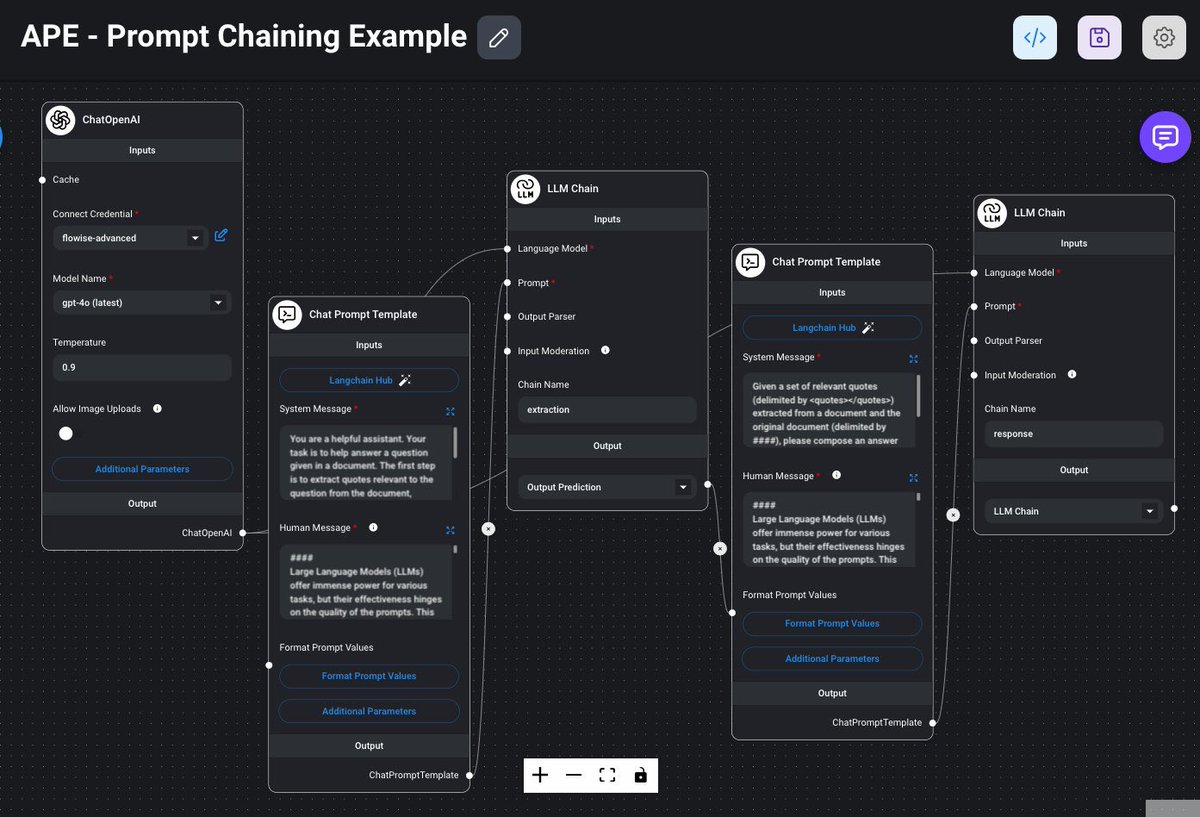
Weights & Biases(W&B)的联合创始人兼 CEO Lukas Biewald将出席GenAI Summit SV 2024 https://t.co/5UOSRYg0xJ 并担任Keynote演讲嘉宾。
他曾创立数据标注平台 Figure Eight(原 CrowdFlower),后被 Appen 收购。他在斯坦福大学获得计算机科学学位,专注于机器学习和人工智能领域。
W&B是一家总部位于旧金山的公司,专注于为机器学习开发者提供实验跟踪、模型管理、数据集管理和可视化工具,帮助研究人员更高效地开发、优化和部署机器学习模型。其平台广泛应用于企业和研究机构,提升了团队的研发效率与协作能力。
W&B 在过去几年内筹集了约 2.5 亿美元的资金,估值达到 12.5 亿美元。该公司获得了多家知名投资机构的支持,Insight Partners、Felicis Ventures 和 Coatue Management。
在行业内,W&B 已成为机器学习操作(MLOps)领域的领先者,平台广泛应用于 OpenAI、微软、Tesla 等大公司,帮助提升机器学习开发和部署的效率和透明度。 
职场警报!避开这10种危险人物,远离职场雷区!
这张图列出了在职场中需要避开的10种危险性格类型,每种类型都以一种动物来比喻,并简明扼要地说明了他们的特点和潜在危害。
1. HIPPO(河马):代表“最高薪意见”,通常是那些薪水最高但意见往往不靠谱的人。
2. ZEBRA(斑马):没有任何证据支持但非常傲慢的人。
3. WOLF(狼):总是在处理最新紧急情况的人,忽视了长期目标。
4. RHINO(犀牛):名义上在场,但实际上对工作没什么贡献。
5. SEAGULL(海鸥):高级管理人员,偶尔现身,批评一番就走人。
6. DODO(渡渡鸟):抱有过时且危险观点的人。
7. VIPER(毒蛇):心怀恶意,容易破坏团队成果的人。
8. MOUSE(老鼠):观点模糊、容易被影响的人。
9. PARROT(鹦鹉):喜欢重复别人的意见,没有自己见解的人,非常烦人。
10. DONKEY(驴子):只看数据,不懂背景知识和原因的人。
在一个团队项目中,如果有一位“海鸥”型的高管突然出现,对项目指手画脚,却不给出建设性的建议,然后马上离开,这会让团队士气低落,甚至影响项目进展。而“河马”型的领导则可能因为他们的错误决策而导致整个项目偏离正确方向。
了解这些职场中的危险性格类型,可以帮助你识别和应对这些负面影响,从而更好地保护自己的职业生涯和工作环境。避开这些“危险动物”,才能让职场生活更加顺畅、高效。 
掌握大模型的终极指南——《Hands-On Large Language Models》全方位解读
这张图是一本关于大模型的书《Hands-On Large Language Models》的内容概览,分为三个部分来讲解大语言模型的相关知识和应用。
Part 1: Understanding Language Models
第一部分主要介绍大语言模型的基础知识,帮助读者理解这些模型是如何工作的。
1. An Introduction to Large Language Models:介绍大语言模型的基本概念和背景。
2. Tokens and Embeddings:讲解词元(tokens)和嵌入(embeddings)的概念,这是理解大语言模型的关键。
3. Looking Inside Large Language Models:深入探讨大语言模型的内部结构和工作原理。
Part 2: Using Pretrained Language Models
第二部分着重于如何使用预训练的大语言模型进行实际任务。
4. Text Classification:讲解如何使用大语言模型进行文本分类任务。
5. Text Clustering and Topic Modeling:介绍文本聚类和主题建模的方法。
6. Prompt Engineering:解释提示工程(prompt engineering)的技术,这在使用预训练模型时非常重要。
7. Advanced Text Generation Techniques:介绍高级文本生成技术,提高生成文本的质量和一致性。
8. Semantic Search and RAG:讨论语义搜索和检索增强生成(RAG)技术,用于改进搜索结果的准确性。
9. Multimodal Large Language Models:探讨多模态大语言模型,即同时处理文本和图像等多种输入类型的模型。
Part 3: Training and Fine-Tuning Language Models
第三部分则详细说明了如何训练和微调大语言模型,以提高其在特定任务上的表现。
10. Creating Text Embedding Models:介绍创建文本嵌入模型的方法,这对于表示文本数据非常重要。
11. Fine-tuning Representation Models for Classification:讲解如何微调表示模型以进行分类任务,提高其准确性。
12. Fine-tuning Generation Models:探讨微调生成模型的方法,使其能够更好地生成高质量的文本。
这本书从基础理论到实际应用,再到高级技巧,全面覆盖了大语言模型的各个方面。通过阅读这本书,读者可以深入理解大语言模型,并学会如何高效地使用和优化这些强大的工具。 
突破极限!NVLM 1.0引领多模态AI革命,超越GPT-4o!
Nvidia推出了NVLM 1.0,一款顶尖的多模态大语言模型。这款模型在视觉和语言任务上表现优异,甚至能媲美市场上最先进的专有模型(如GPT-4o)和开放访问模型(如Llama 3-V 405B)。令人惊讶的是,经过多模态训练后,NVLM 1.0在仅文本任务上的表现也得到了提升。
该模型采用了一种全新的架构设计,结合了仅解码器多模态模型和基于交叉注意力的模型的优点,提高了训练效率和多模态推理能力。此外,引入了一维图块标记设计,极大地增强了高分辨率图像下的多模态推理和OCR相关任务的性能。
在数据方面,NVLM 1.0非常注重数据集的质量和任务的多样性,而不仅仅是规模。这使得模型在数学和编码能力上都有显著提升。
想象一下在自动驾驶汽车中的应用场景。NVLM 1.0可以通过摄像头实时获取道路信息,并与车辆导航系统进行语言沟通。它不仅能识别交通标志,还能理解复杂路况下的人类指令,例如“如果前方有施工,请寻找替代路线”。这得益于其强大的视觉-语言处理能力以及出色的文本推理能力,使得自动驾驶更加智能、安全、可靠。 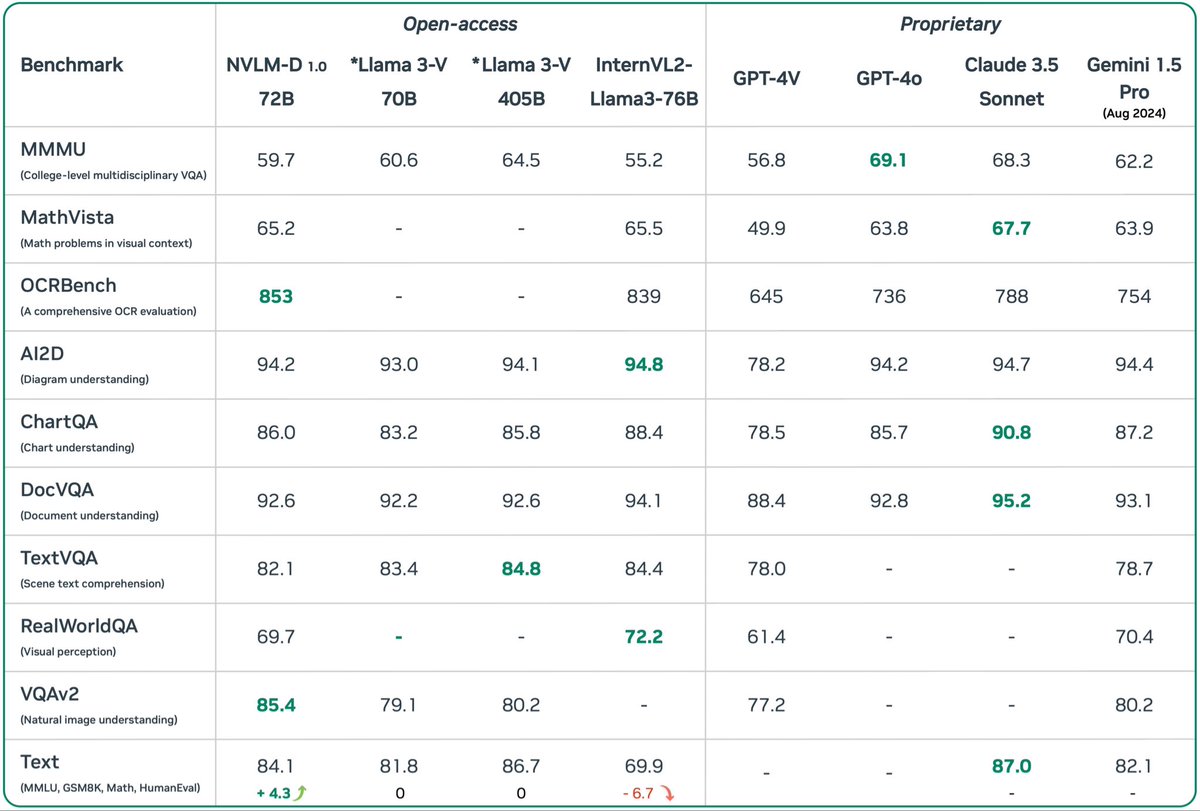
贝莱德和微软将推出300亿美元的人工智能投资基金
贝莱德和微软正联手投资idc和其他支持AI的基础设施。两家公司在声明中表示,这项名为“全球AI基础设施投资伙伴关系”的战略旨在吸引300亿美元的私募股权投资,并用这笔资金进行高达1000亿美元投资
声明显示,包括能源项目在内的基础设施投资将主要在美国,一部分资金将部署在美国的伙伴国
AI Chat Prompts 详细解读
这张图是一份AI聊天提示词的备忘单,帮助用户掌握和最大化利用AI聊天提示的输出。它从不同角色、格式和语气等方面给出了具体的使用建议。
1. 模式与角色(Modes and Roles)
- Intern(实习生):寻找关于某个主题的研究。
- 例:Find research on <
- Idea Generator(创意生成器):针对某个概念生成想法。
- 例:Generate ideas on <
- Editor(编辑):编辑和修正文本。
- 例:Edit and fix this text <
- Teacher(老师):教授某个主题。
- 例:Teach me about <
- Critic(评论家):批评或评价某个观点。
- 例:Critique my argument <
2. 格式(Format)
- 包含多种格式,如博客、代码、社交媒体帖子、推文、电邮、论文、表格、报告、演示文稿、研究成果和要点等。
3. 语气(Tones)
- 可以选择不同的语气,如自信的、描述性的、叙事性的、学术性的、友好的等,以适应不同的受众和场合。
4. 聊天提示示例(Chat Prompts Examples)
- Insert first prompt:给出文件摘要。
- 例:Give me a summary of this document <
- Modify the output:修改上一个回答,使其更适合初学者。
- 例:Use the previous summary to write a 500-word piece that explains the topic to beginners.
- Modify the tone:改变上一个回答的语气,使其更符合观众口味。
- 例:Change the tone of the previous answer to make it more polished and in attune to your audience.
- Modify the format:将上一个回答转换为演示文稿,每页包含一个关键点。
- 例:Convert the previous answer into text for a presentation with 1 slide of each key point.
5. 不同行业的提示词(Prompts for Different Sectors)
- 市场营销人员(Marketers)
- 列出关于某主题的博客文章创意。
- List <
- 创建30天社交媒体日历。
- Create a 30-day social media calendar about <
- 编码员(Coders)
- 帮助发现代码中的错误。
- Help me find mistakes in my code <
- 销售人员(Sales)
- 为潜在客户生成10种方法来产生销售线索。
- Generate 10 ways to produce leads for <
- 设计师(Designers)
- 在设计某应用或网站时考虑的一些交互方式。
- What are some interactions to consider when designing a <
- 研究人员(Researchers)
- 确定某行业前20家公司,并解释为何被选中。
- Identify the top 20 companies in <
- 客户服务人员(Customer Service)
- 为客户查询创建模板回复邮件。
- Create a template for the email response to customers inquiring about <
这份备忘单提供了丰富且具体的提示词,涵盖了从市场营销到编码再到设计等多个领域,帮助用户高效利用AI工具完成各类任务。 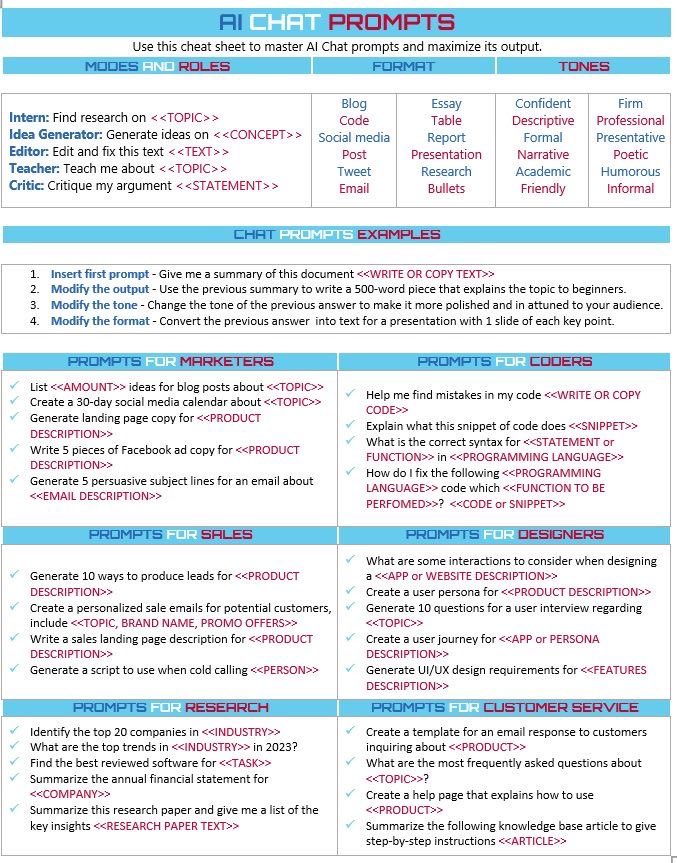
各位builders: 全球第五大风投基金NEA的合伙人Vanessa Larco将出席GenAI Summit SV 2024 https://t.co/5UOSRYg0xJ 并担任首日Keynote。New Enterprise Associates创立于1977年,总部位于美国加州Menlo Park(硅谷)。 NEA管理着超过250亿美元的资产,是全球Top5最大的风险投资公司。多个案例“被收录进哈佛商学院案例的基金创新操作。”
NEA曾投中团购网站鼻祖Groupon和企服巨头Salesforce,也在中国投资了字节跳动。NEA最新的deal近日终于揭开神秘面纱:李飞飞首次创业项目World Labs宣布获得2.3亿美元融资,由a16z、NEA恩颐投资和Radical Ventures领投,还有AMD、Adobe、Databricks的风投部门和Shinrai Investments LLC等身影,更有黄仁勋执掌的英伟达。空间智能将推动AI变革,李飞飞和NEA一致认为,实现这目标的第一步是从大语言模型转向大世界模型。
🔔GPTDAO 周报「9月17日~9月18日」
✨✨✨✨✨✨✨✨
1⃣ 360 AI 发布大模型专家协同工作模式(CoE):
- 将CoT思维链技术升级为多专家协同工作,类似OpenAI o1-preview的反思决策模式。
- 用户可从54款国产大模型中选择3个分别作为专家、反思者和总结者,实现模型间的高效协作。
- 性能媲美 OpenAI o1,超越GPT-4。
2⃣ 使用 AI 辅助合成数学数据集:
- 生成高质量、复杂且具有挑战性的数学题目。
- 解决了现有模型难以生成多样化和高难度数学问题的不足。
- 结合人工参与,确保问题的正确性和复杂度。
3⃣ 奥特曼谈 AI 模型能力达标:
- OpenAI 的模型已达到人工智能技术目标的第三阶段。
- AI 能通过自然语言执行复杂任务,并处理多个步骤。
- 在用户指令不明确时,AI 会主动询问,以确保任务完成质量。
4⃣ 微软 Office 全家桶大更新:
- Excel 集成 Python,提升数据处理能力。
- 推出全新 Pages 和 Copilot Agents 等功能。
- Microsoft 365 Copilot 第二波更新,将网页、工作和 Pages 整合为全新的知识工作设计系统。
5⃣ Seed-Music:字节跳动开发的音乐生成模型:
- 通过多模态数据(文本描述、音频参考、乐谱等)生成音乐。
- 提供后期编辑功能,可修改歌词或旋律。
- 支持音乐转换,10秒语音或歌声录音即可生成不同风格的音乐。
6⃣ Snap 发布第五代 Spectacles AR 眼镜:
- 内置 AI,可通过语音提示生成 3D 动画。
- 提供 46 度视场角,每度 37 像素分辨率,相当于 10 英尺外观看 100 英寸显示屏。
- 基于 OpenAI 打造的 My AI 聊天机器人,支持手势和语音控制设备,体验多种增强现实应用。
7⃣ Genspark 推出 Autopilot Agent 异步 AI 代理:
- 支持云端同时运行多个任务,包括异步处理、Cross Check Agent、智能内嵌截图等功能。
- 提供高效的任务管理,未来还将推出更多功能扩展。
这是本周 GPTDAO 精选的最新 AI 动态与突破,让我们一同期待这些前沿技术为我们的生活带来更多便利与可能。
线性回归冰山图:背后隐藏的数学和统计知识
这张图用冰山的形象生动地展示了线性回归模型的表面操作与其背后复杂的数学和统计理论之间的关系。我们平时在R语言和Python中使用简单的一行代码来进行线性回归,但实际上,这一行代码背后有很多深奥的理论支持。
冰山上的部分(表面)
- R语言:`lm(y~x, data)`
- Python:`LinearRegression().fit(X, y)`
这些是我们在编程中常用的命令,用来快速实现线性回归。这部分就像冰山露出水面的部分,简单明了。
冰山下的部分(隐藏)
1. 高斯-马尔可夫定理(Gauss-Markov Theorem):确保在线性回归中,最小二乘估计具有最佳线性无偏估计(BLUE)的性质。
2. 中心极限定理(Central Limit Theorem):说明在样本量足够大的情况下,样本均值服从正态分布,这是许多统计推断方法的基础。
3. 大数法则(Law of Large Numbers):表示随着样本数量增加,样本均值会接近总体均值。
4. 科克伦定理(Cochran's Theorem):用于分析方差分解的重要理论。
5. 费舍尔信息量(Fisher Information):用于衡量参数估计中的信息量和精确度。
6. 概率论(Probability Theory):提供了处理随机事件和不确定性的基础理论。
7. 信息论(Information Theory):帮助理解数据中的信息量及其传递方式。
8. 线性代数(Linear Algebra):在线性回归中用于处理矩阵运算,如求解系数向量。
9. 优化理论(Optimization Theory):在线性回归中用于找到最佳参数,使得误差最小化。
总结
通过这张图,我们可以看到,虽然实现线性回归的代码非常简洁,但其背后依赖的是大量复杂而深奥的数学和统计学理论。这些理论共同支撑了我们所看到的简洁而高效的模型应用。 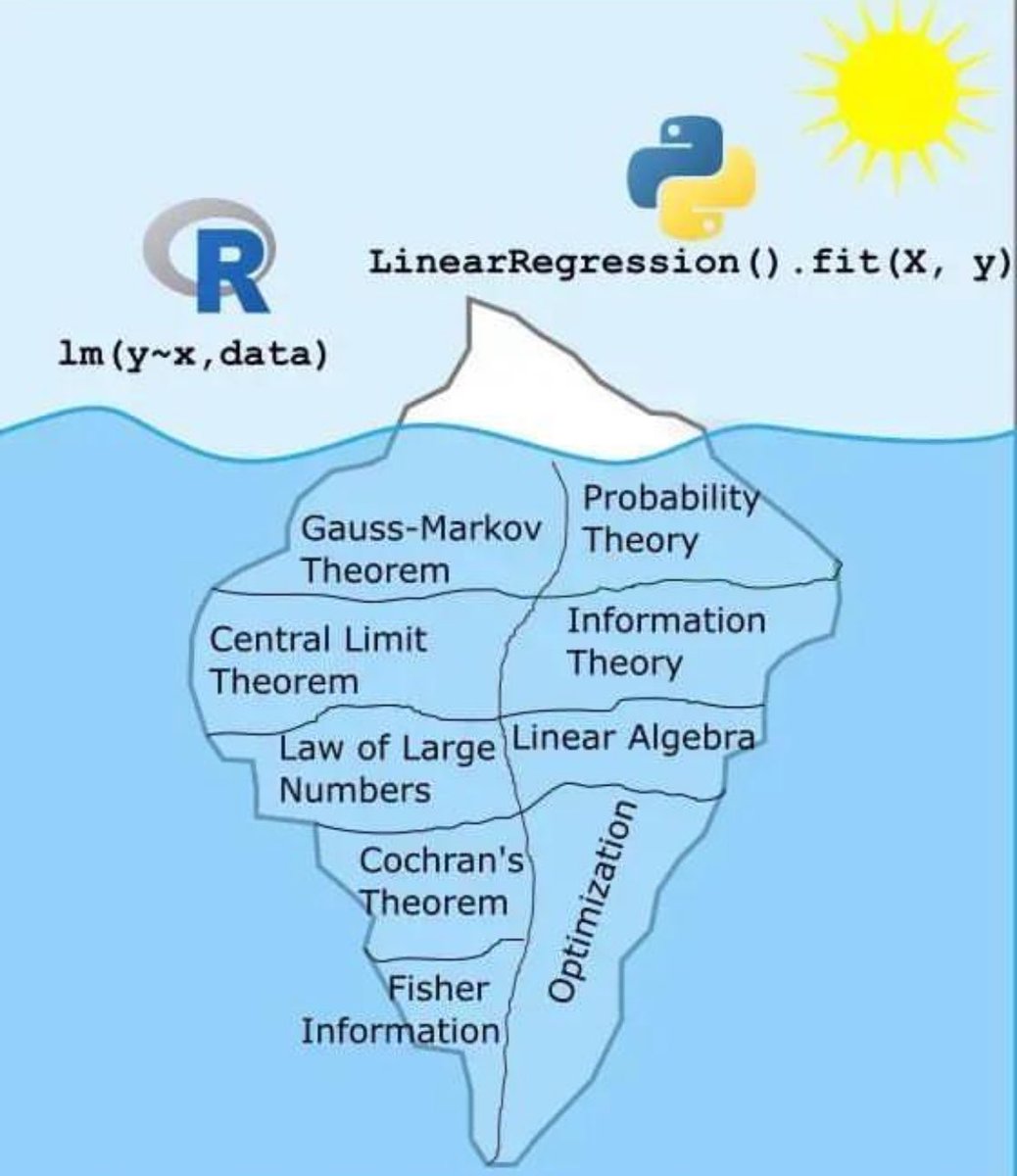
揭开操纵心理学的黑暗面:七大技巧与对策全解析
1. 煤气灯效应
- 解释:通过不断否认、撒谎和误导,让你怀疑自己的记忆和感知。
- 场景:你的伴侣总是说“你记错了”,即使你清楚记得事情的经过。最终,你开始质疑自己的记忆。
- 对策:果断脱身,远离这种情况。
2. 受害者心态
- 解释:操纵者装作无助或可怜,激发你的同情心,从而让你为他们做事。
- 场景:一个同事总是在你面前抱怨工作压力大,暗示需要你的帮助,而实际上他在利用你的善意完成自己的工作。
- 对策:保持情感距离,必要时断绝关系。
3. 罪疚诱导
- 解释:让你觉得自己有罪,从而满足操纵者的需求。
- 场景:朋友总是提起你过去的错误,让你感觉内疚,从而答应他的各种要求。
- 对策:保持理智,但坚定相信自己的直觉。
4. 假装无知
- 解释:操纵者假装不懂,从而逃避责任或让你承担更多工作。
- 场景:同事总是装作不会使用办公软件,让你帮忙做很多本该他完成的工作。
- 对策:关注行为本身,不要被表象迷惑。
5. 负面幽默
- 解释:用嘲讽或贬低的方式进行打击,让你感到自卑或不安。
- 场景:朋友常常开一些让你尴尬和难堪的玩笑,但又说“只是开玩笑”来掩饰。
- 对策:保持镇定,微笑着反应,将注意力转移到对方身上。
6. 投射
- 解释:指责他人做自己正在做的事情。
- 场景:配偶不断指责你不忠,而实际上是他自己在外有外遇。
- 对策:不要上钩,把自己从这个局面中抽离出来。
7. 持续批评
- 解释:不停地指责、嘲讽和否定你的努力和成就,以此提升自身价值。
- 场景:上司不断挑剔你的工作,即使你已经尽力做好,但他这样做只是为了显得自己更强大、更权威。
- 对策:礼貌地接受指摘,然后继续过自己的生活。
通过了解这些常见的操纵技巧和相应的对策,我们可以更好地保护自己,不被他人轻易控制和影响。 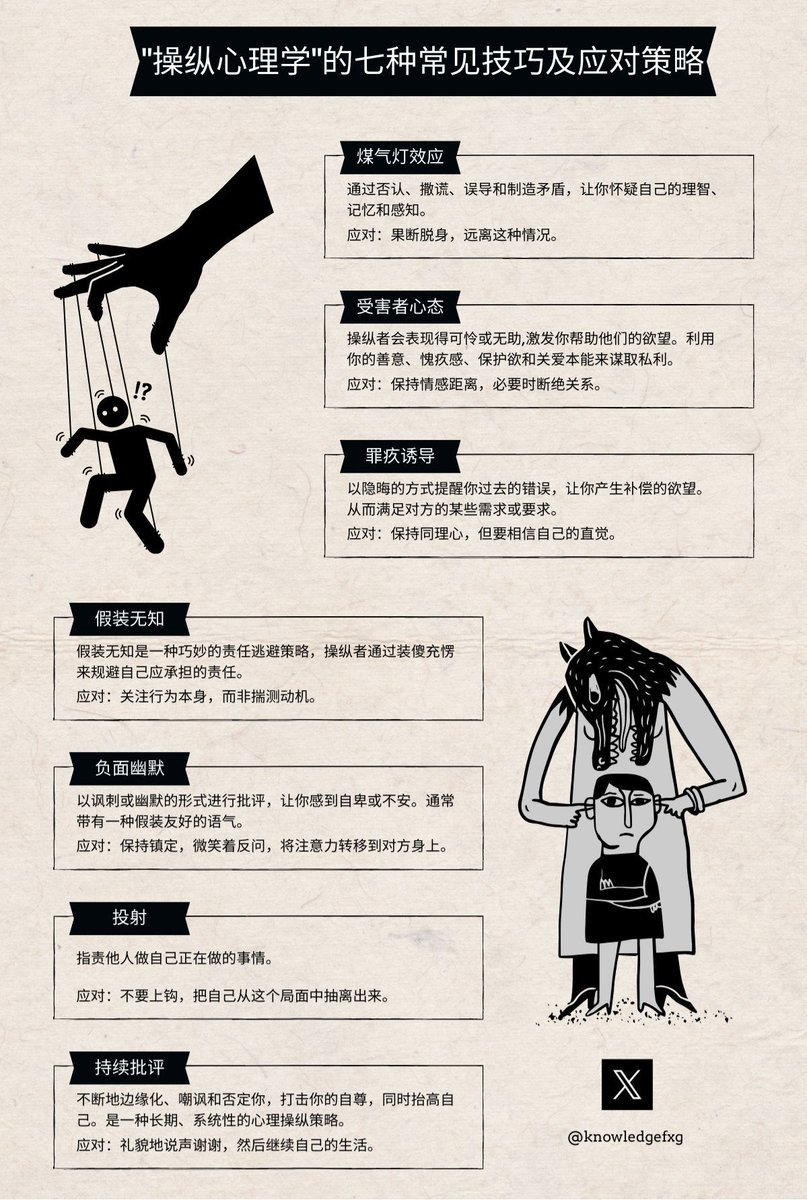
半导体与智能计算的未来:碳基智能 vs 硅基智能
王兵先生的观点可以简单理解为:半导体(比如我们常说的芯片)是目前最好的计算工具,因为它们很容易得电子和失去电子,这使得它们非常适合用来做开关,而计算机就是通过无数个这样的开关来进行运算的。
碳基智能 vs 硅基智能
- 碳基智能(像人脑):通过生物化学反应实现计算。这些反应涉及到原子之间电子轨道的变化,需要移动带质量的粒子(比如离子)。因此,速度和效率受到限制。
- 硅基智能(像电脑):通过移动质量几乎可以忽略不计的电子和光子来实现计算。由于不需要移动大质量的粒子,所以速度快得多,存储容量也大得多。
比如你在用手机玩一个大型游戏。你的手机处理器(硅基智能)能够快速计算出每一个动作、画面和声音,因为它只需要移动一些小小的电子。而你的大脑(碳基智能)虽然也能处理这些信息,但它是通过复杂的生物化学反应来完成,速度远远比不上手机处理器。
这意味着未来的人工智能系统将越来越强大,它们能够处理的信息量和速度将远超人类的大脑。因此,硅基智能全面替代碳基智能只是时间问题,这将带来一个全新的时代。
总结
芯片作为当前最优计算载体,其核心优势在于其高效快速的电子移动,使得硅基智能在速度和存储容量上全面碾压碳基智能。未来,我们可以期待更加先进、强大的人工智能系统,它们将在各个方面超过人类能力。
AI与人类协作:从问题生成到解决方案的全流程揭秘
这张图展示了一个AI系统如何与人类协作,从生成问题到提供最终解决方案的完整流程。下面是对各个步骤的通俗解读:
(A) 技能对验证 (Skill Pair Validation)
1. 技能描述:系统首先获取一系列技能的描述。
2. 验证技能对:AI根据这些描述生成相关的问题和解决方案,并验证这些组合是否有效。
(B) 问题生成 (Question Generation)
1. 技能描述:系统再次利用技能描述。
2. 生成问题:AI基于技能描述生成具体的问题。
3. 人机对话示例:将生成的问题与人类进行对话示例,确保问题合理且有代表性。
(C) 试图解决方案 (Attempted Solution)
1. 生成问题:利用上一步生成的问题。
2. 尝试解决方案:AI根据问题提出尝试性的解决方案。
(D) 问题验证 (Question Validation)
1. 生成的问题和尝试的解决方案:将这些内容进行验证。
2. 验证示例:通过已有的验证标准来评估解决方案是否有效。
(E) 最终解决方案 (Final Solution)
1. 验证后的问题和解决方案:将通过验证的问题和其对应的解决方案整合。
2. 提供最终解决方案:输出经过验证的最终答案。
通过这个流程,AI系统能够在与人类协作中逐步完善,从而提供高质量、可信赖的解决方案。 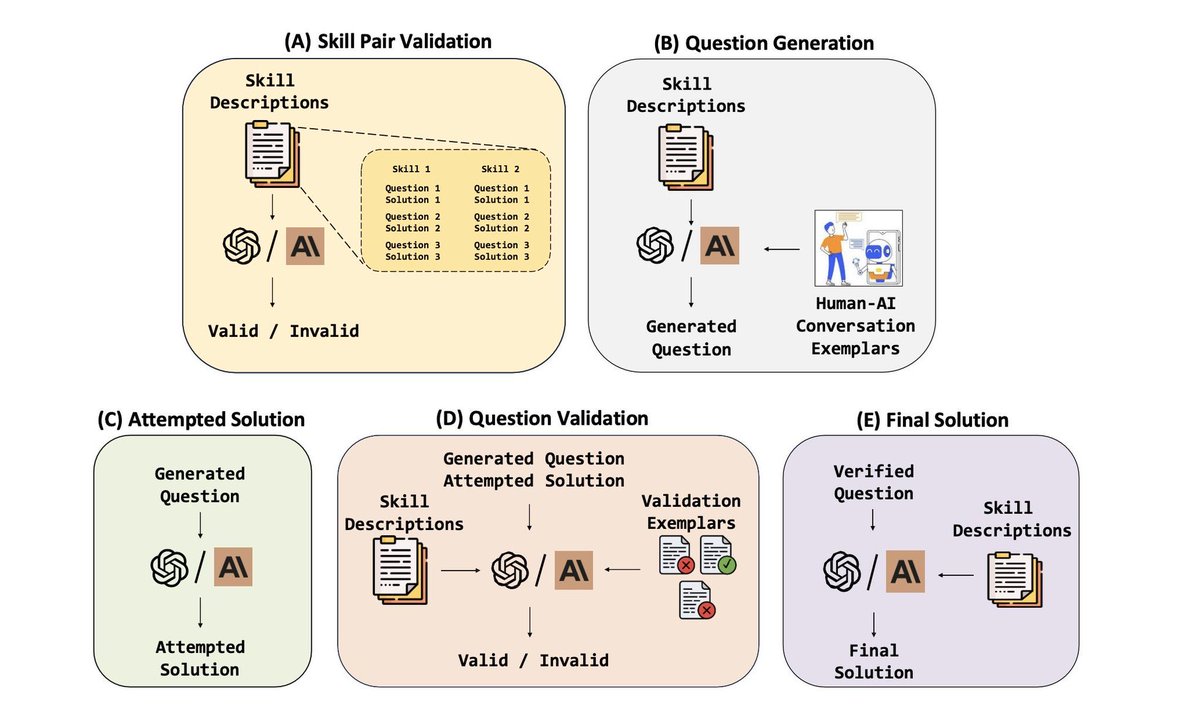
打破长文本处理瓶颈:RetrievalAttention让AI推理快如闪电
在处理大量数据时,长上下文的语言模型(LLM)非常出色,但因为其使用的注意力机制计算复杂度较高,所以效率上有些挑战。简单来说,就是当你给模型大量信息时,它可能需要花费较长时间来处理和理解这些信息,这会导致推理过程变慢,特别是在需要大量显存和处理时间的时候。
核心创新:RetrievalAttention 方法
这个方法的核心在于优化如何选择重要的信息进行处理。具体来说:
- 卸载大部分数据:把很多不那么重要的数据从GPU内存中移到CPU内存中,这样可以节省GPU的资源。
- 智能搜索算法:开发了一种新的搜索算法,能够更好地识别哪些信息对当前任务最重要,从而更精准地选择需要处理的数据。
- 协同策略:利用GPU和CPU共同工作,GPU负责最关键的数据,而CPU则动态查找其他相关数据。
实验结果
这个方法在多个测试中表现很好。在一些复杂的测试场景下,它能以较少的时间达到与全量处理相似的准确性。例如:
- 处理长度为128K的文本时,与传统方法相比,解码速度快了很多。
- 使用16GB的GPU内存就能在一台NVIDIA RTX4090显卡上高效运行大规模模型。
场景举例
想象一个客服机器人需要实时分析并回答用户问题。通常,这个机器人需要快速浏览数百万字节的数据(比如用户手册、常见问题解答等),以提供准确答案。通过使用RetrievalAttention方法,机器人可以更快地从海量信息中提取出最相关的数据进行分析和回答,从而提升响应速度和准确性。这就像是在图书馆找书时,能立刻找到所需书籍,而不是一本本翻找。 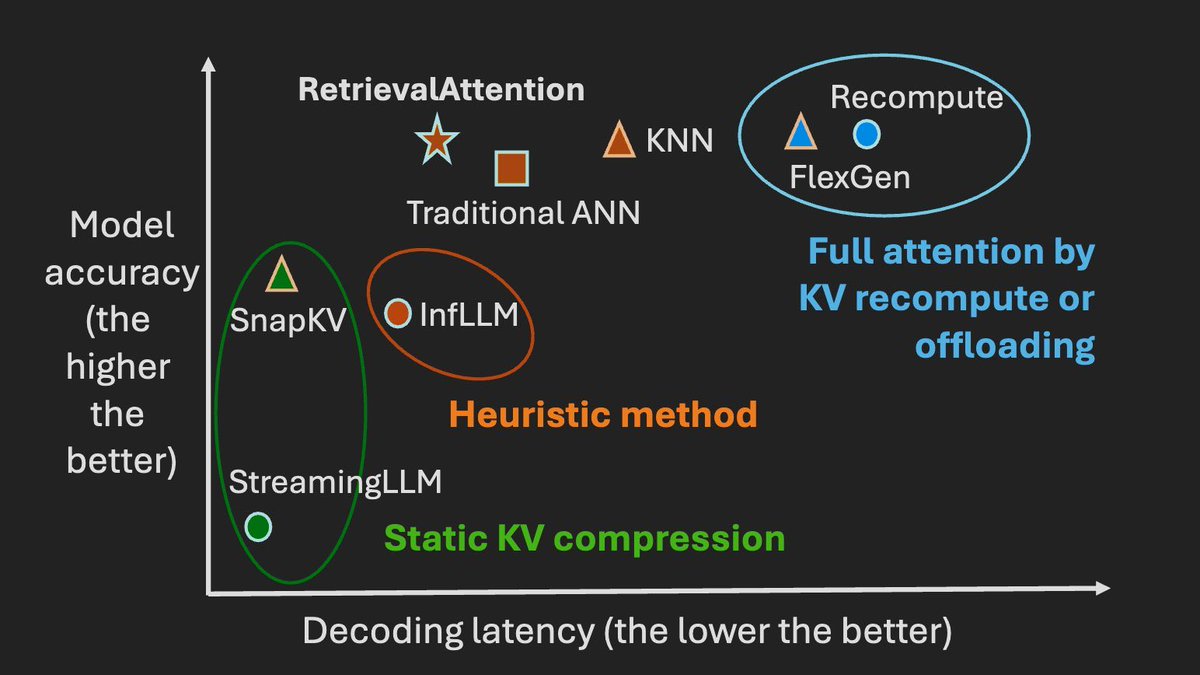
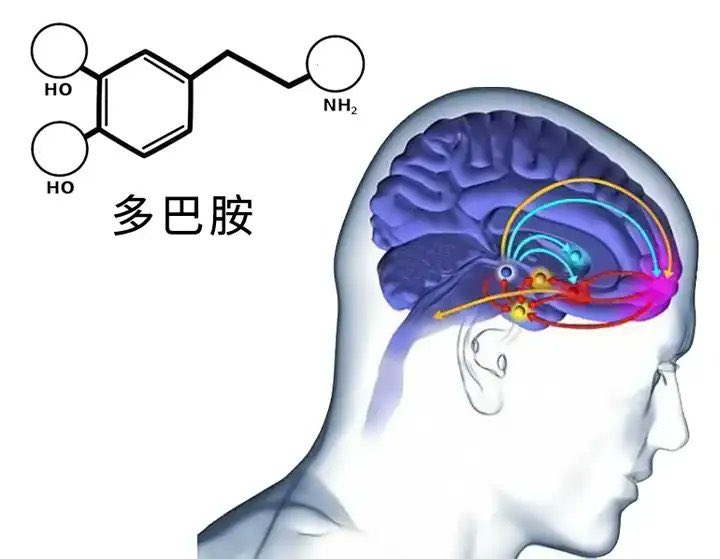
多巴胺的游戏:现代生活中的隐形“控制代码”
在心理学中,“多巴胺戒断反应”是一个引人注目的现象。快节奏的娱乐方式,比如短视频、电子游戏和社交媒体,会刺激大脑中多巴胺的快速分泌,让人感到持续的愉悦。然而,一旦远离这些带来快感的活动,人们往往会感到极度不适应,随之而来的就是焦虑和空虚。
这种现象解释了为什么许多人在繁忙的工作生活中承受巨大压力时,常常转向抽烟、喝酒或参与各种社交活动来缓解压力。这些行为背后的驱动力,正是对多巴胺快感的渴望与依赖。
如果说世界上有一种代码能够控制所有人,那可能就是多巴胺的代码。它无形中影响着我们的行为模式和情绪状态,让我们在追求短暂快乐和长期满足之间不断挣扎。
通过理解这一机制,我们可以更好地掌控自己的生活,寻求健康而平衡的方式来应对压力,而不是一味地追逐那些让我们上瘾的快感源。这不仅有助于提升个人幸福感,也能帮助我们在现代社会中找到内心的宁静。