
Yup. They're maybe-eventually-consistent-if-you-try-hard-enough distributed storage.
Discussion

one simple thing that would enable stronger consistency is where you expose the event sequence number to clients so they can just store the latest and pick up on a sync from that point without wasting any bandwidth
negentropy is so retardedly stupid in that respect, but it was invented to work around the lack of easy extension of the interface because it was made so complex and brittle
Yeah if you added a sequence you'd have an event queue.
Relays could be an open alternative to Amazon SQS/SNS.
Maybe we need a whole new kind range for sequenced events, as those would probably require a different implementation in the relay code.
no, sequence numbers are completely subjective to a relay, they are literally a record of when they saw an event
i already implemented it, go look:
https://realy.mleku.dev/api#tag/events/GET/api/eventidsbyserial/{start}/{count}
yes it was that simple
and btw, the fact that i came up with it in collaboration with semisol is part of why i'm so salty about his behaviour
anyway, it's in there, and i put it there *so he could sync faster with realy*, you see the tone of that?




NFDB fixes this to some extent by introducing stronger consistency and actual scalability.
Having local data stores is great but beyond some load a single local disk won’t cut it. And at large scale, full DB replicas like strfry/immortal/realy won’t cut it either.
NFDB separates the query compute required, from the storage layer, as well
The next wave of relays will have to be enterprise scale, like NFDB, I think.
Nostr has been playing in the kiddie pool for a while.
the core of NFDB is one of the most rock-solid, well tested databases ever
it is a part of my core technology stack which is a very short list of DBs/tools/etc I use for 99.9% of my projects
NFDB is a vertical scaling solution
nostr is about horizontal scaling
missing the point that the relay itself is a shard in the data store is a fatal mistake
NFDB is a horizontal scaling solution, though
it can scale to hundreds of hosts, sharing the same relay DB, without any issue at the base configuration, with tens of TB and an insane amount of clients
that can be extended to do cross-cluster sharding to achieve significantly more throughput as well
this is all within the constraints of full NIP-01 compliance still, and with strong consistency across every host
if you are able to forego some of that, and/or can give up some amount of consistency, you can go way higher…
I see a place for both, as relays are hubs and there can be different sized hubs, or one hub could be a set of relays.
exactly, the only real question is how to divvy up the data you push to the relays
it's a sharding problem, really, we don't have an easy solution for that but making all records into events is part of teh solution
i was already building a relay as a "cache server" a year ago
What Nostr solved for is for the need for every hub to be the same size and contain the same information. Nostr is useful, even if you only store your own notes in it.
That makes it extremely useful for storage that can be very tiny or very large, like git or a UNIX file server.
yep, you can make it more capable by concurrency and faster hardware, but it doesn't change the fact you have atomized the database by making it smart enough to do subscriptions and storage
> Yup. They're maybe-eventually-consistent-if-you-try-hard-enough distributed storage.
YES THIS IS THE PROBLEM
No seriously, please explain how I'm supposed to have a farm of relays servicing on domain?? No one has been able to tell me that yet.
I don't care how slow or bloated a database can get if I can just add more and stuff Envoy in between them and have realtime replication between a cluster of DBs servicing > 100k rps??
back to the problem of sharding, if you want to gate the access to a single endpoint
there is many ways to shard a database, this is part of the advantage of enhancing records to become events with metadata
the front doesn't even have to have any storage, or it can be a simple cache as well, you can push the logic back up the stream
What will be needed for many use cases is an open standard for clustering relays and sharing data to maintain a high degree of replication.
sure, or no reinventing the wheel with specialized unmaintainable tech debt and using a database that can that for them. 1-3ms of added latency doesn't fucking matter as long as I can make it consistent by scaling out.
and this is the entire fucking issue with strfry, realy, khatru, etc
they try to reimplement replication when it has been done many times, often at worse performance
one of the primary choices for the underlying DB were it must support automatic replication and healing, and that it also must not be complete shit to maintain
Which many if not most database systems provide, even if they aren't ideal. Hell even SQLite has options for replication.
No one has been able to give me numbers. If you had to write it down, how many concurrent users, and total users would you expect to service with something like strfy? Meaning maybe 80% or better latency rolloff?
nostr:npub10npj3gydmv40m70ehemmal6vsdyfl7tewgvz043g54p0x23y0s8qzztl5h could likely answer this more specifically!
I’d say at a few thousands users you’d start having issues with strfry.
Nostr.land was less affected because it had less data to store than a standard public relay
it uses LMDB for DB which is both good but also has issues, maintenance tasks such as breaking changes require taking the entire DB offline, etc
biggest problem was it was a pain to do AUTH on, or search, or any sort of spam filtering that wasn’t basic

gathering numbers based on users is tough on nostr because what would you base it on? how do you tell if its a user, or a scraper gone wild?
I'm sure nostr:nprofile1qqs06gywary09qmcp2249ztwfq3ue8wxhl2yyp3c39thzp55plvj0sgprdmhxue69uhhg6r9vehhyetnwshxummnw3erztnrdakj74c23x6 could come up with a test plan, but all i can see is #connections, and periodic latency smokepings (doing a simple REQ)
ive seen one strfry handle up to 8000 simultaneous connections, but that just means someone left their connections open.
one performance thing is in my mind, there is a very real difference between a nostr aggregator and a relay. if you are doing aggregation and search, you have different needs for your data pipeline than normal client-relay nostr usage.
since outbox model is still barely used, not many actual users are connecting to regular relays, they only connect to primal or damus.
anyway, not sure why im bothering saying this, if you want to build a better relay I'm all for it. i guess im just annoyed at performance comparisons i cannot confirm myself (closed source). nostr clients dont even judge a relays performance other than a websocket ping, so i never have received a user complaint of slowness. I use the relays daily myself and it seems just fine with minimal resources.
If an aggregator thinks they're too slow, well, they're not paying me to make their aggregation fast so it makes no sense to scale up for them. There's a reason robots.txt exists because early web was the same, a crawler could take down your site, but you wouldn't want to scale up just to help them crawl faster.
distributed systems where you dont get any heads up what people are doing, is a hard environment to work in. but strfry handles it like a champ.
Most of the clients are so inefficient that a measurement would mostly be of their own slowness. 😂
We've added result time to our Alex client success message, so that might provide some transparency.
what could be done is, have test harness that mimicks exactly the common types of requests a user does (like record what amethyst does) and play it back x1000 against a test relay with a bunch of generated data to query.
or for alex client, the typical set of reqs or events that are expected to be happening.
My smoke test with Playwright will be timed, and I could run it in parallel across a set of relays, on an hourly basis, and then post pretty trend diagrams on https://status.gitcitadel.com .
if its a stress test, i wouldnt do it on live relays, but a periodic ping of what a client would do in separate geolocations x1 is useful
I said smoke test, not stress test. It's just one happy path e2e in a headless browser.
i call it "smokeping" because there was a cool monitoring tool called that, written in perl back in the day.. it was my #1 fav thing for seeing status of the end to end service and it's trends over time.
i do this and publish as nip66 latency events and to influxdb for querying. very useful, not on the same network as the relay (geo distributed). It connects and does a simple REQ, records total latency. 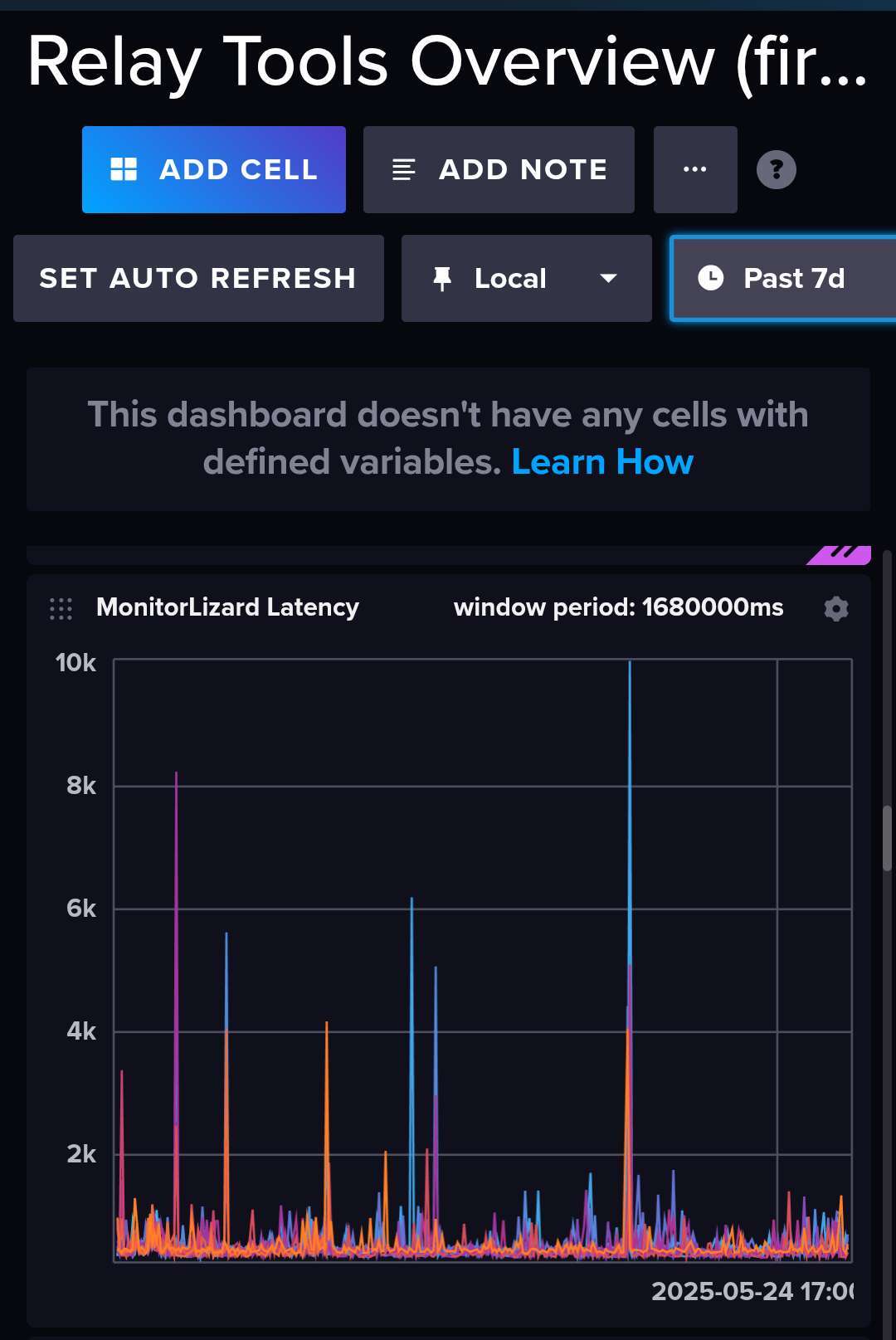
for a stress test of relay software itself you usually have to be running it on the same hardware configuration. maybe we can work together on benchmarking somehow though anyway, everybody loves benchmarks
Yeah so 8k open connections, not 8k in use fair enough. Yeah my concern is we need way more than a single instance and (I hope) way more than 8k active connections to support a product like Alexandria assuming we get anywhere close the reach were aiming for. I just want the software to exist for the time we DO need it. Like I said in my argument before. In just about any other software deployment, the software exists to scale, if needed, but not implemented _until_ needed. What happens when we do need it, and it doesn't exist?
Beyond that my concern, and I made this number up, something like a latency log scale showing some sort of "rolloff" - when load gets high enough to cause latency to creep to the point the service becomes interrupted or noticeable to the end user.
alexandria would be a read heavy load, books read and commented vs. uploading of the books
almost exclusively. The relay doesn't have to be a relay, kind if just needs a database (or files tbh) and some good caching.
http api like the one i made
badger has a good read cache on it as well, and it's designed to split the read/write load mainly in favor of writing indexes because events don't change, also, scanning the key tables is fast because it's not interspersed with value read/write
with any DB there is always going to be a ceiling where you must eventually start splitting into clusters
but NFDB makes this a very hard problem to reach, and even if you do there are many solutions:
1. You can shard indexes across clusters with very little changes
2. Events can also be stored in a blob store
this gives up strong consistency in certain contexts but also is extremely manageable, compared to say, trying to split events into 8 different relays
then you would have to query 8 relays for each request
but with NFDB the only difference is index reads now happen to a different cluster and there is no request or resource amplification
most scaling strategies are built as trees of requests instead of a web, and assume the client is dumb and not able to address several entry points to the data set
the biggest mistake everyone makes about nostr is there is a need for "global" at all
there isn't, and the social graph creates a path for data requests to flow through in a more optimal way
this same dumb mistake is why blockchains have not solved any real problems
they think because all nodes are replicas that you can just go to any and ...oh, it's just one machine!
What he said. ☝🏻
And we're getting improved performance out of the client side, with the rewrites. A lot of it has to do with the client's handling of the connections and filters, and their internal parallelization and clever patterns.
Too much sequentialization and inefficient workflows and algorithms in the clients.
It's lazy-ass client devs causing most of the slowness because they're trying to keep the Feature Junkies happy and lump sloppy algo on top of buggy interface on top of inefficient architecture...
There have got to be models by which a relay (DB) can plug in as a shard into a larger system.
Nostr is open, so in theory each relay can be independent. That's what makes it decentralized. But if a client wants a picture of a greater portion of the network, you need to be able to index across relays.
Farcaster tried to solve this by just forcing each node to sync with all the others, but that seems to expensive to scale.
that's why i say the smartest sharding strategy is to put users on maybe 2-3 relays and then the relays forward queries for stuff they don't have, cache it, and next time can get it
you have to deal with the one hit wonder problem but aside from that, there's no real reason why the entry points to the data set need to be narrow and fast
They need to be narrow and fast, but you can have n number of them. #GitCitadel alone has 6 relays. And I have three local ones.
> Farcaster tried to solve this by just forcing each node to sync with all the others, but that seems to expensive to scale.
Exactly my argument.
But besides that, the web generally works off the assumption that it's extremely rare when I request https://gitcitadel.com it fails. Which is why HA backends exist. HA now gets pushed to the client level, and the assumption that GET https://gitcitadel.com HTTP/1.1 returns data becomes a 20 second timeout and a socket error... That's not good UX or DevX
Yeah you need a really smart client layer that handles relay connections full-time.
which is a lot harder to do with sockets

This is why we plan to build our own client SDK.
I think Nostr will win with a mix of smarter clients and smarter relays.
It's exciting to see how even small tweaks to the retrieval algo causes the speed and accuracy to literally jump. So fucking satisfying, fr.

Performance programming is so fun.
Vibe coders will never understand.
my first love in programming was GUIs and stuff like painting deadlines is so juicy for me
how do we get enough of a solution to be satisfactory if we get a bottleneck upstream?
I hate GUIs. I pretended I couldn't code, on here, for nearly 2 years, because I didn't want to have to touch a GUI. 😂
But the under-the-hood part of GUIs is legit fun.
i really liked the "immediate mode" GUI model but unfortunately the current state of the best one, Gio, is pretty poor in the widget department, and best practices for ensuring minimal wait to do the painting is far from settled, i had lots of fun with that stuff, built a couple of extra wingdings for it when i was working on it (a scrollbar, for one) and was in the process of building a searchable log viewer tool but we didn't get the bugs ironed out before we ran out of runway
my colleague was very ambitious but wasted so much of his time in stupid things, by the last 1/4 of the process i was basically left to clean up his mess and of course you know how much longer it takes to fix stuff than build it
I'll never not find it funny how I heard "Learn to code," a million times, on here.
They've all gone so strangely quiet. I miss them. They were like my little, idiotic, chauvenistic mascots.
Some of it is elegantly handling failure on the UX side, so if there is a bottleneck it doesn't feel so bad to the user.
Some of it is building redundancy: using fallback relays, like nostr:nprofile1qqs06gywary09qmcp2249ztwfq3ue8wxhl2yyp3c39thzp55plvj0sgprdmhxue69uhhg6r9vehhyetnwshxummnw3erztnrdakj74c23x6 has been doing, is one way.
this is also why i designed the filter query on realy's http API to return event IDs instead of pumping the whole event back, this opens up clients to the possibility of sipping at the list to cope with user input (scrolling) and allowing that to pipeline into the render stage
you just can't do that if you can only get the whole event every time, and as well, if you have the event id, if one relay is down you can request it from others, whereas if you just throw the whole shebang at the user you have to have these idiotic "max limit" things that make spidering relays also a lot more complicated
Also preparing the filter efficiently and making assumptions and guesses to make more specific requests.
And parallelization of the requests, breaking off requests early, chunking large result sets, workers, graceful exit-reform-and-retry
or in other words, front end needs Go
none of that is advanced concurrency in Go, now if you want to get into advanced concurrency lol... D,:
Well, we'll soon have it all in C++ 🤔
you see, that's gonna be a problem
Go was literally invented to replace C++ for servers, by people of which two of them are the most legendary names in Unix history

Anyone who knows C++ doesn't see that as a problem.
have fun doing coroutines without clumsy syntax then
or atomic queues, fun fun fun
C++ has the throughput advantage but Go can reduce request latency
which is more priority in the domain of servers?
This is for the client-midware, tho.
in the real world of the internet, latency is everything
throughput is for training your AI
"training your AI"
Don't threaten me with a good time, bro.
😁 Okay, gotta go. Getting carsick and Hubby needs to grab a coffee.
I'm aware.. use case.. Network effects would be felt better with go because of those choices made by other teams. for relays I see a lot of people get very upset when it's not go or rust specifically. I'm not religious when it comes to language and it's not a good idea to get stuck into one or two.
A lot of it is just my experience being a Nostr PowerUser. I can make educated guess about what someone is looking for and how that something probably looks and how fuzzy the logic should be and where it might be located and...
An AI could do that, too, with enough data, but I think my hit-rate is still higher because I understand the human motivation to search for _some particular thing from some particular place at some particular time_. If we then juice up the resulting search with smart engines, it's... awesome.
A big thing is the "where"? What topic are you searching for? Who else really likes that topic and what relays do they have? 🤔
Find the cluster of relays for that tribe and search around there. nostr:nprofile1qyw8wumn8ghj7argv43kjarpv3jkctnwdaehgu339e3k7mf0qydhwumn8ghj7argv4nx7un9wd6zumn0wd68yvfwvdhk6tcpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhsqgxufnggdntuukccx2klflw3yyfgnzqd93lzjk7tpe5ycqdvaemuqcmsvq8y 's work on visualisation could allow for this sort of targeted fetches.

I’d also like a WoT-lookalike that uses content instead of follows to map users by topic proximity if anyone volunteers to make it happen. Then you can feed it a topic and it gives you sources and sources lead to content even if it’s not in the same place.
the word index i've been building could probably help you find this kind of clustering at some primitive level of precision, was quite funny trying to figure out how to make it language agnostic, found a nice library for segmenting unicode UTF-8 text that did a pretty good job, then i just had to filter out common things like filename extensions and nostr entities and whatnot
i gotta finish building that thing... i'm actually done with the draft now and really just need to hook it up to a query endpoint
Yeah, it's the sort of service that saves client devs from having to think through the filters and algorithms.
Or they just use Aedile's topicGraph component. 😉
Are you promising Aedile features? 👀
😁 No pressure.
Something I was thinking about is starting with highly-prepared searches and then expanding iteratively, if they reclick the search button.
Like an LLM does, but with no chat. Just keep looking deeper and broader until you've exhausted the possibilities.
Ooh I do like that. Like the next page of Google, but smarter.
Could have an auto-iterate toggle and there's already a Cancel button, to stop searches underway, and a progress bar. The final stage could be full-text on all active relays or something ridiculous. 😂
We could call that the "Great time to grab a snack and a coffee." Iteration.
I'm trying to corral LLMs into their lane enough in my workflows that I can turn them loose and grab a snack.
😂
that won’t even be necessary though
SEARCH HARDER, BABY
Yeah, Just one bar, that isn't an LLM, but you can say "longform article from liminal from last week about LLMs" and ta-da!
Semantic search ftw
It's actually not that difficult, but nobody has built it yet and I want to find stuff. I'm so tired of not being able to find "bible KJV" because the search is too retarded to normalize and prepare the filter properly and is like,
Yo, I found no "bible KJV". 🤙🏻
Okaaaay, but you found a "KJV Bible" right? 🤦🏻♀️
The worst is when people are like, Just ask am LLM. Ugh. It's like four lines of code, you morons.
The wiki disambiguation page will be a topical search page, for all sorts of notes, with wiki pages listed at the top and more prominently. I was thinking of adding a button that searches "deeper" over a megalist of relays, and then returns counts of how many hits it has to that topic from which relays. And if you go to the profile page, it'll list "top ten hashtags" and you can click one and find out which other users also have it as their top ten. With some fuzzy logic and some keywords and d-tags and titles mixed in.
Just think it'd be cooler to receive the results with a link to the Visualisation page. Especially since that's so pretty, now.
Graph > lists
I tested a software project for visualizing topically-related scientific journals and I want to recreate that effect.
Or we use a different design. Think of the pretty content maps nostr:nprofile1qythwumn8ghj7un9d3shjtnwdaehgu3wvfskuep0qyfhwumn8ghj7ur4wfcxcetsv9njuetn9uq3jamnwvaz7tmjv4kxz7fwwdhx7un59eek7cmfv9kz7qghwaehxw309aex2mrp0yh8qunfd4skctnwv46z7qgmwaehxw309a6xsetxdaex2um59ehx7um5wgcjucm0d5hsqgx5wh8ykwth2pcnpapv07rrgmhex6qq7wh8f40vlqyf9qxdcxfrayzvsft7 . 🤩
Well, first come, first serve. 😁

I need help cleaning up a memory allocator if you're interested XD
Or building an abstraction for hosting CGI applications (CGI, Fast CGI, jrpc etc)
https://git.vaughnnugent.com/cgit/vnuge/vnlib-core.git/tree/lib/Utils/src?h=develop
Gives me Hardware Basic 101 flashbacks.
Malloc purgatory.
oooooo mmap() oooooo
XD
😂
I had to learn Assembler, at one point, but that is in my dark past.
i loved assembler, i was using Macro68 back in the day... funny i can't remember the name of the 3d graphics app that the same friend i got that from gave me. imagine? lol, i can't remember, the assembler was lit, it was like crossing BASIC and C
Masochist spotted.
slow and steady wins the race
language features lead to bloated binaries, more difficult to resolve bugs and idk even what to say about the swarming menagerie of build systems for C++ and Rust and Java, i mean, come on... i can get on a fresh installed PC and be running a server from source in like 10 minutes, try that with any of these other "server programming" languages.
you can still whip it out. Noscrypt could probably use some more assembly :)
do you have access to a SIMD version of SHA256? that's what i use on realy: https://github.com/minio/sha256-simd
At the moment no. I rely on the underlying crypto libraries for that. That would be a micro-optimisation at the moment.
Oh, don't. Michael already dragged me into the frontend and now poor Nusa trails behind me with a mop and bucket because I'm such a noob.
They were asking for people who know COBOL at work and me like

Wait I know what will make you shiver
VirtualAlloc();
0_0
Yes, the Nostr clients often have lots of whiz-bang features, but their middle layer is dumb as a rock.
Because the founding documents presumed existing infrastructure as it is XD. Which honestly I agreed with... as a hobby project it turns out.
mostly because it's built by people who have zero experience writing servers
clients should be more like peers than clients, and they are to some extent but oversimplifying the query interface has dumbed down the challenge for client devs
and it's not an easy thing, personally, the reason why i use Go is because i mainly write servers and concurrency is essential to simplifying features and scale, but you get stuck with dumb heavy or foreground/background thread architectures on most UI dev languages
I only know backend and middle, to be honest. I have an innate fear of GUIs. 😂
i could drown in front end logic, i was building input/output systems for GUI when i was 9 years old, it's just not ... how to say... Saint Rob Pike gave us Newsqueak in 1986, and the state of front end programming has not caught up.
Also, I'm not saying this is the way things _should_ be built. I'm saying, right now, we need it. You can build your specialized database thingy later, but right now I need something that works.
simple, and efficient
IMO "scaling to the planet" is pure hubris
a) we don't need it
b) it's not possible
if it’s not possible then how do all the big websites work
They don't work, is the thing. The website backends scale dynamically, but they have one entry point through a particular domain, and they got taken down so often, that they came up with stupid shit like captcha.
We need to have a system for n entry points, which we do, as any client can access the same database. If Alexandria goes down, switch to Chachi or Nostrudel or Njump or...
It's n entry points to n data stores. Beautiful.
I don't need to the moon, but it would be nice to see 50k concurrent users. Regardless my concern is that the software to do this IF NEEDED doesn't exist yet. The argument for Your Not Gonna Need it is fine in a field where, if the _do_ need it, the software exists to get them there. In a world where the software simply doesn't exist as a company and as a sysadmin, how am I supposed to guarantee a scale of 50k users can be done with minimal expense and down time.
We have customers that will need uptime and consistent pricing. Were targeting users that don't and won't understand how or why nostr works, but it's our job to bring it to them.
this was precisely what NFDB is trying to achieve with a bunch more as well
no one understands the limitations until they are a large relay operator, and even then most of them don’t have the skills to write good relay software
this turns opex from trying to herd a bunch of strfry or whatever instances, into capex
all you need is the message queue, DB and frontends
the frontends are completely stateless
the DB can be scaled up by adding more nodes (you copy a file and done!)
the message queue can be pluggable and is also easy to scale
> the frontends are completely stateless
As it should be
>the DB can be scaled up by adding more nodes (you copy a file and done!)
as it should be
> the message queue can be pluggable and is also easy to scale
as it should be
TY sir
stateless front ends can't cope with a multiplicity of data stores, so theres' that
there is also the fact that users generally cluster around a section of the data set and this can then be easily the shard they are interested in
generic scaling solutions always start with the assumption you only enter the data from one point, that is stupid because there is billions of us humans, we don't need to concern ourselves with the same things all the time
fiat thinking. followers, sheep, i would say "idiots"
I think it's unrealistic to redesign the entire web around the "proper" way to store and interact with data, but the reality is we need something that works with the way things are built now.
well, nothing's stopping you from going and picking up a job at google building their data systems, well?
You can’t design users around systems, but you can design systems around users
The worst part is if done right the current state of Nostr can scale a lot. Not ideal (a v2 for event format is possibly needed) but possible
the most unfortunate part is lazy devs assume that large databases are not possible, but oh boy they are wrong
how do any large platform work then? nostr being decentralized does not mean they are much different (relays and the backend are effectively same)
I’m not working on implementing a complex query system or multi-level caching crap because the existing tools can scale to the fucking planet
I'd say that you are both right. Nostr can assume that there will be n number of entry points, and that some data is more in-demand than others, and which data that is will depend upon the relay's users.
So, databases will have to become smarter about where they store which data and have archiving schemas. People don't mind if something rarely called up is returned more slowly; they're more happy that it is returned at all. But if something popular isn't returned quickly, they will begin to whine about the latency.
I've added return-time display, to our client's search, by the way. Some relays will be setup to return an item fastest, whereas others will be setup to return them most reliably, even when the Internet is generally slower.
and oh look that’s what Noswhere SmartCache is going to do
it can automatically detect popular data and cache it on edge relays
any sort of caching more complex is actually more of a performance hit than benefit
Yes, but I do not think that _every_ relay needs this capability. Different use cases are free to have different architectures, so long as they can communicate according to NIP-01. That's the brilliance of Nostr.
Define the shape of the data and the most-basic way to request it, and keep the implementation open.
exactly... so you define relay groups and they act as caches, and you also need to define limited scopes that each relay is given as an entry point to clients
probably a lot of this can be made dynamic
yes, this is just a matter of building out a query forwarding mechanism into the relays, so they can all keep the hot stuff, and then, they just need a way to expire that shit
separation of concerns ftw. you give it the core primitives and it turns that into a NIP-01 compliant relay DB