
eigencentrality + web of trust nostr:note1qkakcjnct6j67chyg596ked4n4nutyp9e6k35s6ly3w3ssc4wuxq2harxs
Starting to write down the low level ingredients needed to make this happen:
Since its wasm, there can even be innovation in algorithm generation tooling. Everything from visual programming (node graphs) to scripting.
They will have infinite flexibility, so that people can have limitless innovation when building these algorithms into the future
these run locally, are private, don’t depend on an internet connection. They are turing complete nostr queries that run locally.
DVMs are inherently about asking something from an external resource which may not exist or stop working.
the future of damus is a marketplace of turing complete, sandboxed edge algorithms powered by nostrdb. edge algorithms means no relay overhead. efficient, private, scalable, where new algorithms can be created, shared and sold without limits.
I just figured out a solid plan on how to make this happen. I’ve started building it today. This may be bigger than zaps 💥
i2p is another interesting option! Would be cool to see i2p relays
I don’t think so, zeronet is more for static content
markdown in kind1 = straight to jail
yeah there would have to be some static analysis to ensure there are no loop ops, or even bail if there are too many ops in general.
ideally for this use case for public relays we would have a more special purpose virtual machine/bytecode, i think sqlite has something like that internally. I’m just using wasm because I’m lazy and already have code in place for it.
Having this on the local relay is the real intended use case. if you run a script that is just a slow query it doesn’t matter too much, you can run it in a thread and kill the thread if its taking too long or being weird.
hmm i am leaning toward wasm filters/reducers for arbitrarily complex local queries:
nostr:npub1zafcms4xya5ap9zr7xxr0jlrtrattwlesytn2s42030lzu0dwlzqpd26k5 new weekend 🐇🕳️ just dropped
good point, I leave controversial stuff out of these now 😅

For example: once I add WoT scoring to nostrdb, nostrscript query filters will be able to do queries such as:
{give me all the notes of kind 1 with wot > 5}
the nostrscript is a simple wasm function:
{wot_score(note.pubkey) > 5}
Paired with a query: {“kinds”: [1]}
which can be jit compiled and run alongside the nostr query. Possibilities are endless really.
Maybe you could represent this as:
{“kinds”: [1], “reducer”: “nscriptabcdef…”} nostr:note1m0d064c4qkn9pu3d09qn36jd6tdp72jdg5zqlpqyuzhwz39anrqq3gqj69
Pairing a nostr query with a nostrscript(wasm) filter makes a lot of sense: the nostrscript can be jit-compiled and cached, and the query plan is determined from the base nostr query so that the results can start returning instantly and efficiently. I think I just came up with a new kind of database powered by nostr 🤔
Arbitrary but fast sandboxed code execution to query a database sounds really cool, and it can be really fast, fast as strfry.
What if instead of just filtering, we pass a reducer, so you could effectively do map-reduce over nostr data 🤔 this can be used for counting and grouping nostr notes in arbitrary ways, directly from a query, efficiently. Holy shit.
Just noticed it briefly awhile back, seems ok now
This is a weird damus but that started happening for some reason. Will fix
> it enables a way for people to scroll up to see every note they missed since last session. Is this necessarily a good thing? To me this is stressful,
Interesting take.
But it could also be stressful for someone to go back through the history to look for the last notes viewed, and then jump back to the top.
I think we can find a middle ground and it dependes from the context: in a general feed (followed) is probably healtier let the notes flow; in a curated custom feed with a moderate flow I would like to keep the sign of where I was at.
Perhaps an option for each individual feed is the right choice.
/cc nostr:npub1jlrs53pkdfjnts29kveljul2sm0actt6n8dxrrzqcersttvcuv3qdjynqn
I personally use nostr for “whats happening now” i might scroll down a bit but I don’t go down far. I miss a lot of stuff but I don’t fret about it
nice 
you can’t really fetch follower count on the nostr protocol. its a centralized concept. damus does its best, but relays have limits to the amount of data it can do in a single query.
nostrdb should be able to improve this but it will still be tricky and require lots of data storage because contact lists are changing all the time, not to mention people can spam fake contact lists , why is probably why it says I have 1 million followers which is definitely fake/wrong.
nostr:nprofile1qy88wumn8ghj7mn0wvhxcmmv9uq3qamnwvaz7tmwdaehgu3wd4hk6tcpz9mhxue69uhnzdps9enrw73wd9hj7qpqtcekjparmkju6k83r5tzmzjvjwy0nnajlrwyk35us9g7x7wx80ysre4sjn @npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s
oh shi new hellthread just dropped lfg

walking buddy would be cool
sounds like you just need something like a count query instead. Would be more efficient
you would do it like lightning:
ws://pubkey@45.123.123.8:4444
maybe you would first fetch this pubkey from the relay metadata and use it as an optional faster and more secure mode of connection for future sessions (no tls overhead). wouldn’t work on the web but native apps would see a latency reduction on reconnections which happens a lot on mobile. nostr:note1f84rezwtnax5ctpvnrm30rc37gep5gassssv4yzelzvpfv2w9m6shju8ra

looks like #bittorrent dev has kinda stalled recently. many torrent devs are working on shitcoin projects now (chia, tron). Not many clients have v2 support. Maybe we need more bittorrent v2 implementoors. I am itching on hacking support for this in notedeck 🤔
bittorrent is not all about piracy. could be an interesting way to share files on nostr, as an alternative or combined approach with blossom.
bittorrent v2[1] is interesting because of its merkle hash trees: the same file can be replicated across torrent swarms.
So if you share a directory with multiple files in one torrent, and that files exists in other torrents, you can share the same seeders for those files. Maybe you could even use #blossom nodes as seeders if they have a merkle root hash that you need?
Lots of cool possibilities here 🤔

Can’t post the large video, but here’s the latest thing I’ve been working on. It’s a nostr:npub1y2qcaseaspuwvjtyk4suswdhgselydc42ttlt0t2kzhnykne7s5swvaffq for kids to save Sats and earn. Uses nostr:npub1a8jzweysxa9qmtmht874736aalm0lwdsl306nrys9d05ktlrhw3qcr5pj4's LNBits behind the scenes. Will show the same balance as the 3D printed piggy you may have seen me post.
neat
nostr:npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s this is a reply to one of my notes, but it displays as a root note in the latest TestFlight release of Damus
hmm good catch… fixing
Posting to specific relay subsets only makes sense if you have a way to view individual relays or relay subsets. Even better if there is some data on the note which shows intent for that note to only appear on those relays. This would allow topic relays to filter out rebroadcasts.
If the goal is topical relays we need way more than just relay broadcast selection.
What client are you using? It seems to be creating threads incorrectly
Bittorrent v2 is really good at having shared merkle trees across torrents
lol it seems many legacy media outlets picked up the same headline
I’m guess either his phone was compromised or he leaked something outside the protocol.
just escape the json when you need to calculate the id, seems like changing the id wouldn’t be worth it ?
Have you looked at the nostrdb format?
Me and nostr:npub1acg6thl5psv62405rljzkj8spesceyfz2c32udakc2ak0dmvfeyse9p35c also talked about this at nostrasia. You can either make it compact (varints) with an encoding/decoding step or flat/aligned with zero copy. I chose flat for query performance.
I think nostr:npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6 also has one in his Go libraries somewhere.
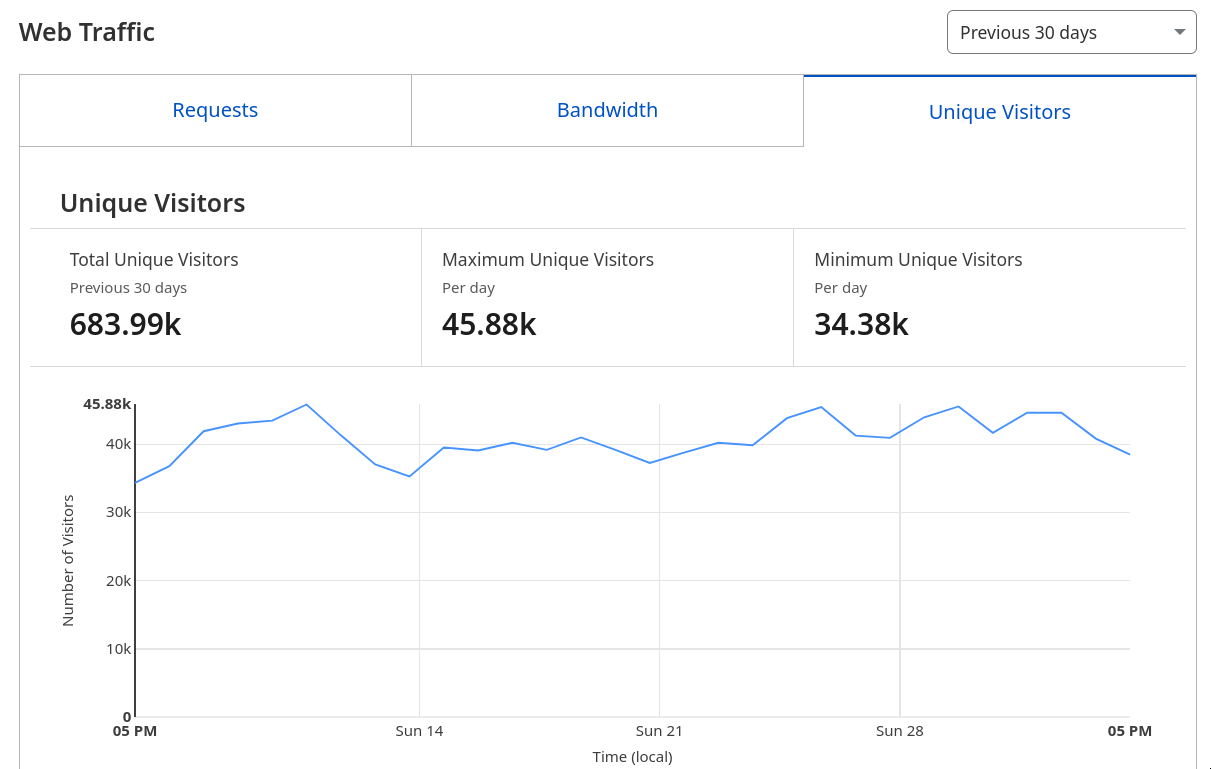
I suspect most of these numbers is to the relay though, i don’t know what the exact breakdown is, i don’t have detailed analytics
yeah maybe cut this in half for a conservative estimate
Rough estimate for number of active lurkers? This is over a 30 day period 🤔 this seems high… this is across the damus domain which includes the relay.
I think they are filtering on any p2p activity. I was able to reproduce the throttling by turning torrents on and off, even through a vpn. Not sure how they are doing that. Eventually i turned it off but now I think they are detecting bitcoin and lightning traffic and potentially throttling me because of that.
I can’t think of anything else :/
There is a feature in nostr queries defined in nip01 for sesrching on prefixes of ids/pubkeys instead of the entire id. The rationale was to make queries smaller but that doesn’t really make any sense as I showed above because it doesn’t really reduce the query size.
I went to a dinner with 5 other bitcoin devs and they all were into climbing without each of them realizing.
I was told climbing is a cerebral thing. Solving puzzles + exercise. Makes sense now.
I suddenly find myself much more interested in coinjoin protocols. funny how being attacked tends to do that. fucking with bitcoiners is not going to work out well for them.
The satellite cdn thing is a neat idea. I may just dump on an s3 bucket or something
Dumped my entire twitter archive from when I last deleted (2017) was 1GB. Would be neat if I converted these to notes on a personal archive relay so I can still reference old tweets after I delete them.
wow thats pretty smart